IEEE ICDM 推荐的十大数据挖掘算法解析
需积分: 10 183 浏览量
更新于2024-07-19
收藏 773KB PDF 举报
"这篇论文介绍了2006年IEEE国际数据挖掘会议(ICDM)评选出的十大数据挖掘算法:C4.5、k-Means、SVM、Apriori、EM、PageRank、AdaBoost、kNN、朴素贝叶斯和CART。这些算法在研究社区中具有重大影响力。对于每个算法,论文提供了算法的描述,讨论了其影响,并回顾了当前和未来的研究方向。这十个算法涵盖了分类等领域。"
本文是关于数据挖掘领域的重要算法的综述,主要关注了2006年ICDM会议上选定的十大算法,它们对研究领域产生了深远影响。以下是对这些算法的详细说明:
1. **C4.5**:由Ross Quinlan开发,是ID3决策树算法的升级版,用于分类任务。它通过信息增益率选择最佳属性进行划分,处理不均衡数据集效果较好,同时能处理连续属性。
2. **k-Means**:一种聚类算法,将数据点分配到最近的k个聚类中心,通过迭代优化聚类结果。适用于大规模数据集,但对初始聚类中心的选择敏感。
3. **SVM(支持向量机)**:通过构建最大边距超平面进行分类,能有效处理高维数据和非线性问题。SVM的核技巧使其在各种复杂数据上表现优异。
4. **Apriori**:关联规则学习的基础算法,用于发现项集之间的频繁模式。它遵循“频繁项集的子集必须也是频繁的”原则,避免了无效的数据库扫描。
5. **EM(期望最大化)**:用于处理含有隐变量的概率模型的参数估计方法,常用于混合高斯模型和隐马尔可夫模型等。
6. **PageRank**:Google搜索引擎的核心算法,衡量网页的重要性。通过迭代计算网页间的链接关系,PageRank值高的网页被视为更有影响力。
7. **AdaBoost**:一种集成学习方法,通过迭代训练弱分类器并调整其权重,形成强分类器。每次迭代重点关注前一轮被错误分类的数据,提高整体性能。
8. **kNN(k近邻)**:基于实例的学习,分类新样本时将其与训练集中最近的k个邻居进行比较,多数邻居所属类别决定新样本的类别。简单但计算量大。
9. **朴素贝叶斯**:基于贝叶斯定理的分类算法,假设特征之间相互独立。尽管“朴素”,但在许多实际应用中表现出色,如文本分类。
10. **CART(分类与回归树)**:既可以做分类也可以做回归的任务,通过最小化不纯度或平方误差来构建树结构。剪枝策略用于防止过拟合。
这些算法在数据挖掘和机器学习中占有重要地位,它们各自解决了不同问题,共同推动了领域的发展。随着时间的推移,针对这些算法的改进和新变种不断出现,进一步提升了数据挖掘的效率和准确性。研究人员持续探索这些算法的潜力,以及如何将它们应用于新的数据类型和挑战。
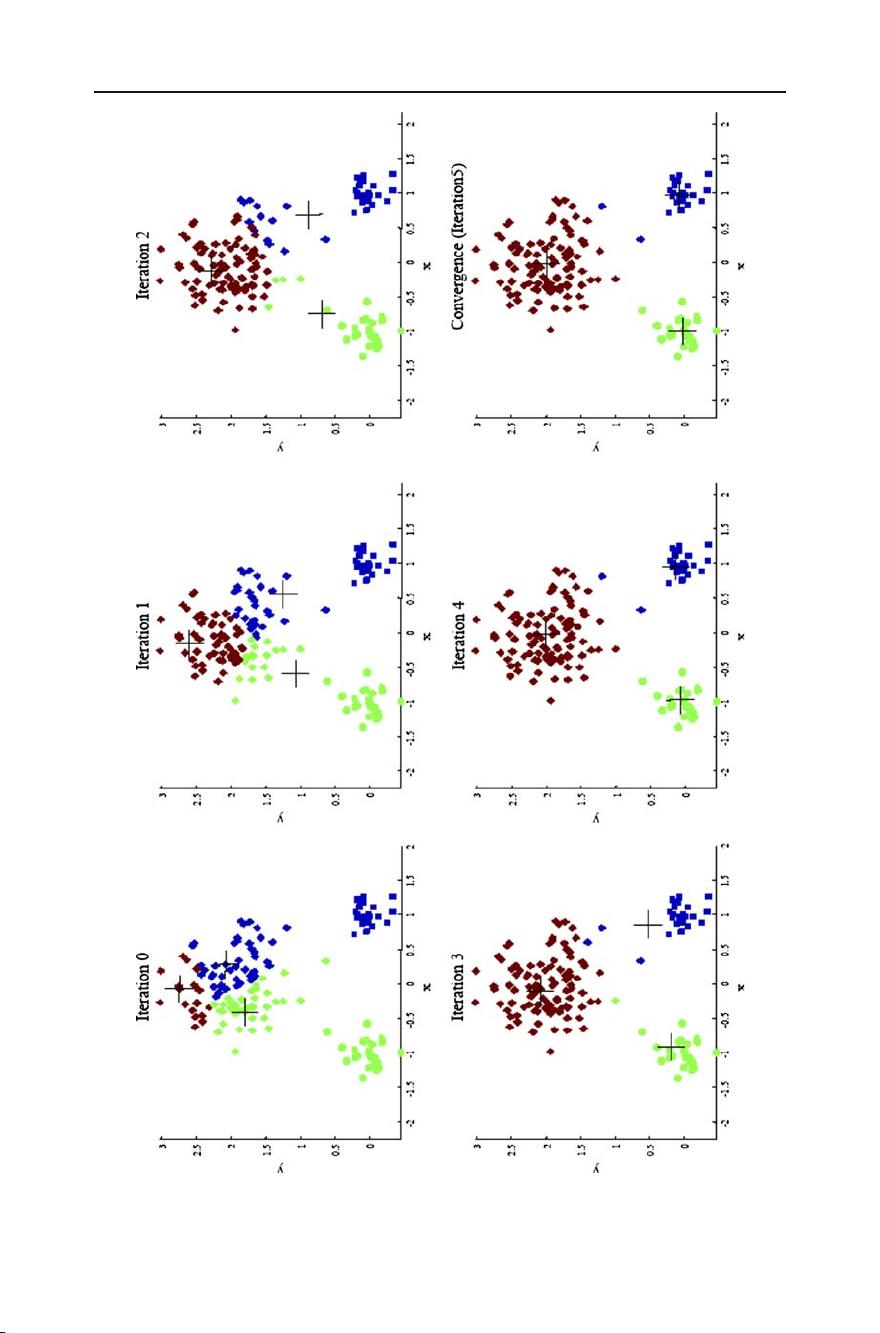
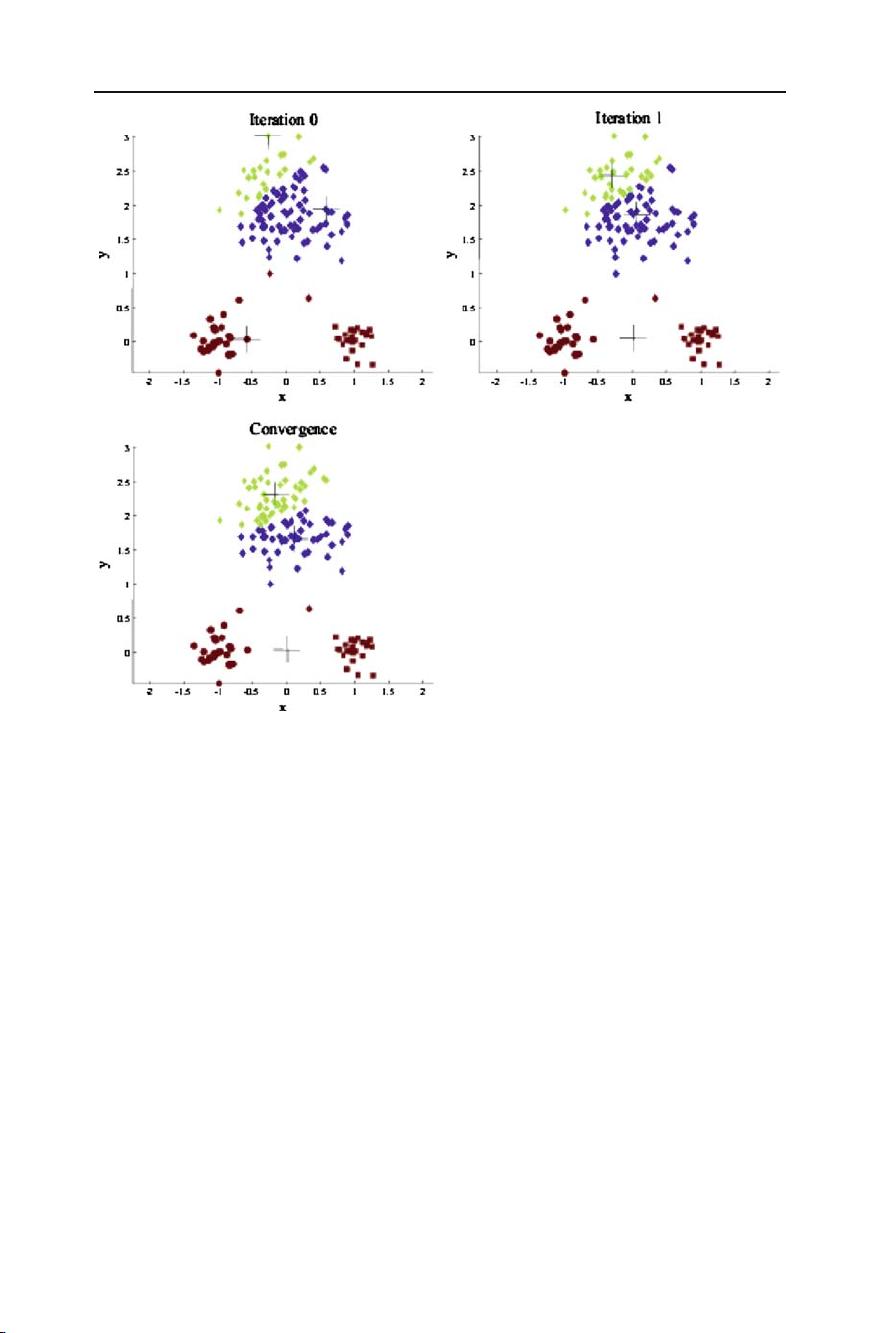
Top 10 algorithms in data mining 7
Fig. 1 Changes in cluster representative locations (indicated by ‘+’ signs) and data assignments (indicated
by color) during an execution of the k-means algorithm
123
剩余36页未读,继续阅读
2010-01-06 上传
2019-09-14 上传
2019-09-17 上传
2023-03-28 上传
2023-07-30 上传
2024-11-01 上传
2024-11-01 上传
2024-11-12 上传
2023-04-03 上传

ShawDa
- 粉丝: 50
- 资源: 17
 我的内容管理
展开
我的内容管理
展开







