理解Kafka:LinkedIn创建的数据流处理系统
"Kafka是一种分布式流处理平台,最初由LinkedIn开发,后来成为Apache软件基金会的顶级项目。它主要用于处理大规模的实时数据流,尤其适用于处理互联网公司的用户活跃数据,如页面浏览量、用户行为等。Kafka的核心概念包括生产者、消费者、Broker和Zookeeper,以及Topic、Partition和Logs。"
Kafka的存在主要是为了应对LinkedIn处理海量活跃数据的需求,这些数据反映了用户的在线活动,如浏览、搜索和互动等。通过收集和分析这些数据,公司能够获取有价值的信息,例如热门搜索关键词、用户行为模式等。这种实时的数据处理能力对于现代互联网公司至关重要,因为它可以帮助企业快速响应市场变化,优化用户体验,以及实现更高效的业务决策。
Kafka的主要组件包括:
1. **生产者**:生产者是数据的来源,负责将消息发布到Kafka的特定主题(Topic)中。
2. **消费者**:消费者从Kafka中订阅并消费这些主题中的消息,可以是实时处理或批量处理。
3. **Broker**:Kafka集群中的服务器,负责存储和转发消息,每个Broker可以包含多个Partition。
4. **Zookeeper**:协调Kafka集群,管理元数据,确保系统的稳定性和一致性。
Kafka采用Partition的设计,每个主题可以被划分为多个分区,每个分区是一个有序的消息队列。Partition的主要好处包括:
- 分散存储:通过分区,数据可以在多个服务器之间分布,避免单个服务器的存储容量限制。
- 提高性能:更多的分区意味着更高的并行处理能力,提高消息的生产和消费速度。
- 提高容错性:每个分区可以有多个副本(Replicas),分布在不同的服务器上,以实现数据备份和高可用性。
Kafka的分布式特性使得主题的多个分区可以在集群中的不同服务器上分布,每个服务器负责其分区的消息读写。每个分区的副本数量可以通过配置设置,以实现数据冗余和故障切换。当主分区的服务器出现故障时,其他副本可以接管,保证服务的连续性。
此外,Kafka还支持批量导入数据到数据仓库(如Hadoop)进行离线分析,这使得它成为一个强大的实时与离线数据处理结合的工具。通过与Spark、Storm等大数据处理框架结合,Kafka能够构建出实时的数据处理管道,为企业提供实时的洞察力和决策支持。
Kafka是一个高效、可扩展且高可用的实时数据流处理平台,广泛应用于日志聚合、流处理、消息传递等多个场景。其设计原理和功能使其在大数据领域中扮演着重要角色。
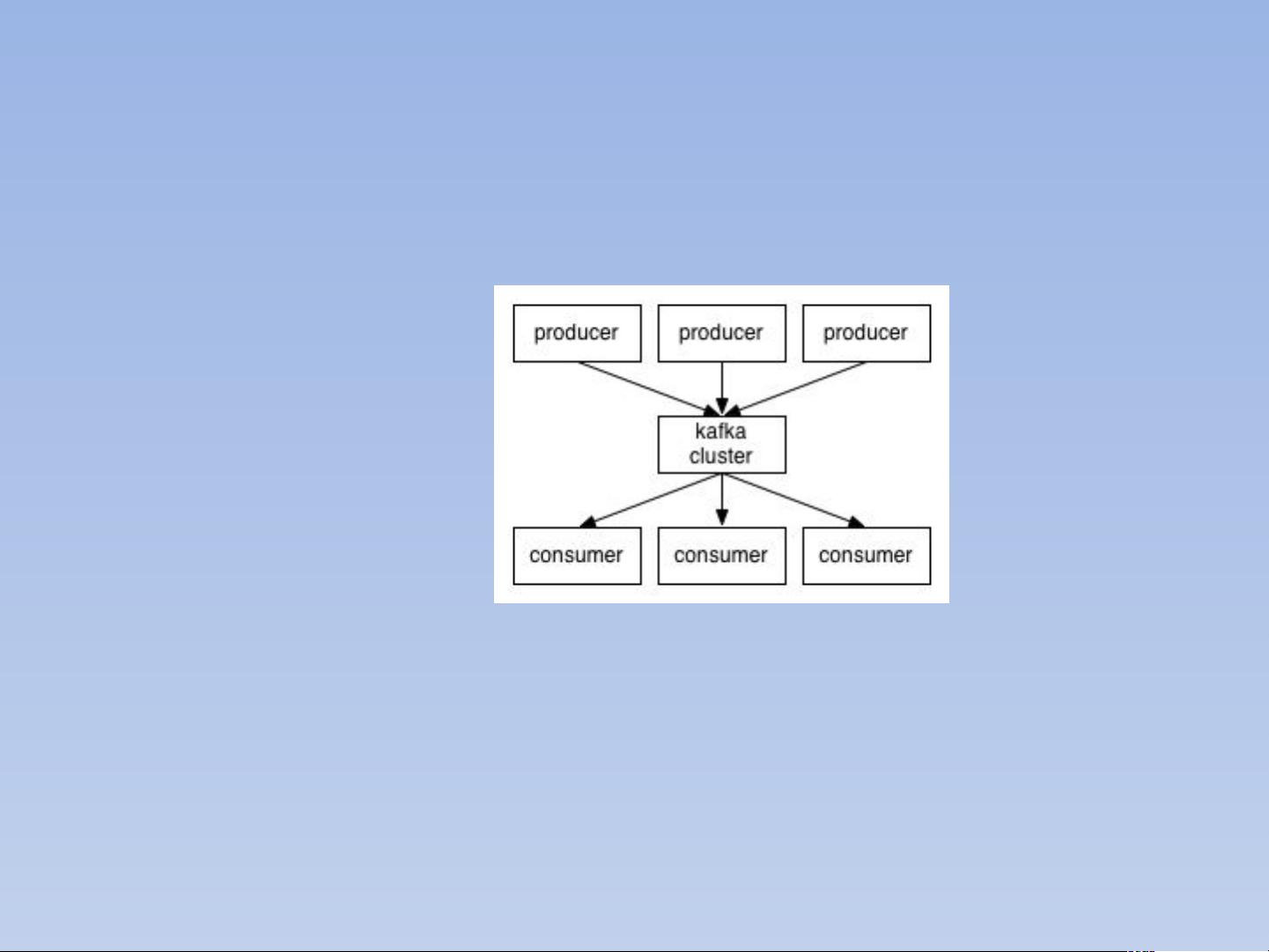
Kaa 的 4 个角色
•
生产者
•
消费者
•
Broker
•
zookeeper
剩余14页未读,继续阅读
2023-10-16 上传
2023-09-13 上传
2024-05-18 上传
2023-10-22 上传
2023-08-14 上传
2023-11-05 上传

sinat_28350201
- 粉丝: 1
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机人脸表情动画技术发展综述
- 关系数据库的关键字搜索技术综述:模型、架构与未来趋势
- 迭代自适应逆滤波在语音情感识别中的应用
- 概念知识树在旅游领域智能分析中的应用
- 构建is-a层次与OWL本体集成:理论与算法
- 基于语义元的相似度计算方法研究:改进与有效性验证
- 网格梯度多密度聚类算法:去噪与高效聚类
- 网格服务工作流动态调度算法PGSWA研究
- 突发事件连锁反应网络模型与应急预警分析
- BA网络上的病毒营销与网站推广仿真研究
- 离散HSMM故障预测模型:有效提升系统状态预测
- 煤矿安全评价:信息融合与可拓理论的应用
- 多维度Petri网工作流模型MD_WFN:统一建模与应用研究
- 面向过程追踪的知识安全描述方法
- 基于收益的软件过程资源调度优化策略
- 多核环境下基于数据流Java的Web服务器优化实现提升性能
