云计算与大数据综合实践:Hadoop-Hive-Spark实验报告
需积分: 5 80 浏览量
更新于2024-07-15
1
收藏 5.43MB DOC 举报
“此资源是一份来自重庆邮电大学的云计算与大数据综合实践实验报告,涵盖了hadoop、hive、spark的相关实验,以及逻辑回归和决策树在预测拍卖成功率中的应用。”
在大数据处理领域,Hadoop、Hive和Spark是三个至关重要的组件,它们各自承担着不同的角色:
1. **Hadoop**:
- Hadoop是一个开源框架,主要用于处理和存储大量数据。报告中提到了两个Hadoop相关的实验:伪分布安装部署和完全分布式安装部署,这些都是理解和运行Hadoop集群的基础步骤。
- Hadoop的核心组件包括HDFS(Hadoop Distributed File System)和MapReduce。HDFS提供了高容错性的文件存储,而MapReduce则用于大规模数据集的并行计算。
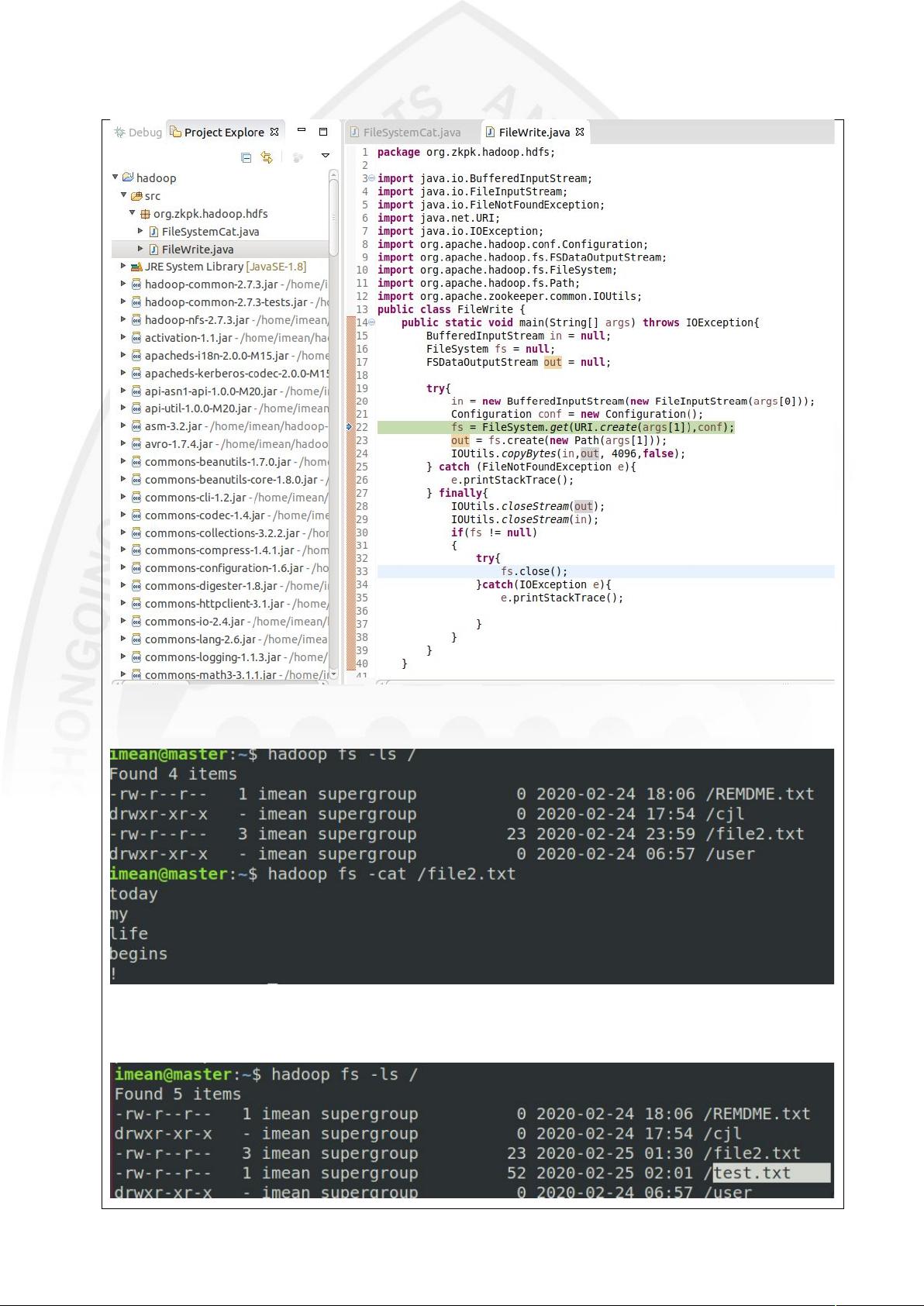
- 实验中还涉及到了HDFS的API使用,如通过IOUtils读取文件、文件创建与写入等操作,这些都是实际工作中处理HDFS数据的基本技能。
2. **Hive**:
- Hive是建立在Hadoop之上的数据仓库工具,允许用户使用SQL(HQL)来查询和管理存储在Hadoop集群中的数据,简化了大数据分析的复杂性。
- 在报告中,学生负责搭建Hive环境并进行Hive编程,这可能包括创建表、导入数据、执行查询等操作,以实现对大数据的结构化查询和分析。
- 大数据综合案例可视化可能是通过Hive查询后,利用其他工具(如Tableau、QlikView等)展示数据结果。
3. **Spark**:
- Spark是一个快速、通用且可扩展的大数据处理框架,相比MapReduce,它提供了更高效的内存计算,适用于迭代算法和实时分析。
- 学生在实验中负责搭建Spark环境,并完成了Spark编程,这可能包括使用Spark SQL、Spark Streaming、Spark MLlib(机器学习库)等模块。
- 实验中的“拍卖预测”可能涉及到使用Spark MLlib中的逻辑回归和决策树模型,这两者是常见的机器学习算法,用于预测事件发生的概率。
4. **逻辑回归和决策树**:
- 逻辑回归是一种广义线性模型,常用于二分类问题,能输出预测事件发生的概率。在拍卖预测场景中,可能通过训练模型来预测拍卖成功的可能性。
- 决策树则是一种监督学习算法,用于分类和回归问题,通过构建树状模型来做出决策。在预测拍卖成功率中,决策树可以根据多个特征来决定是否成功。
实验报告要求学生不仅理解这些技术的基本概念,还要能够实际操作和应用,从而提升其在大数据环境下的实际动手能力和问题解决能力。通过这样的实践,学生可以更好地掌握大数据处理的全貌,为未来从事相关工作打下坚实基础。
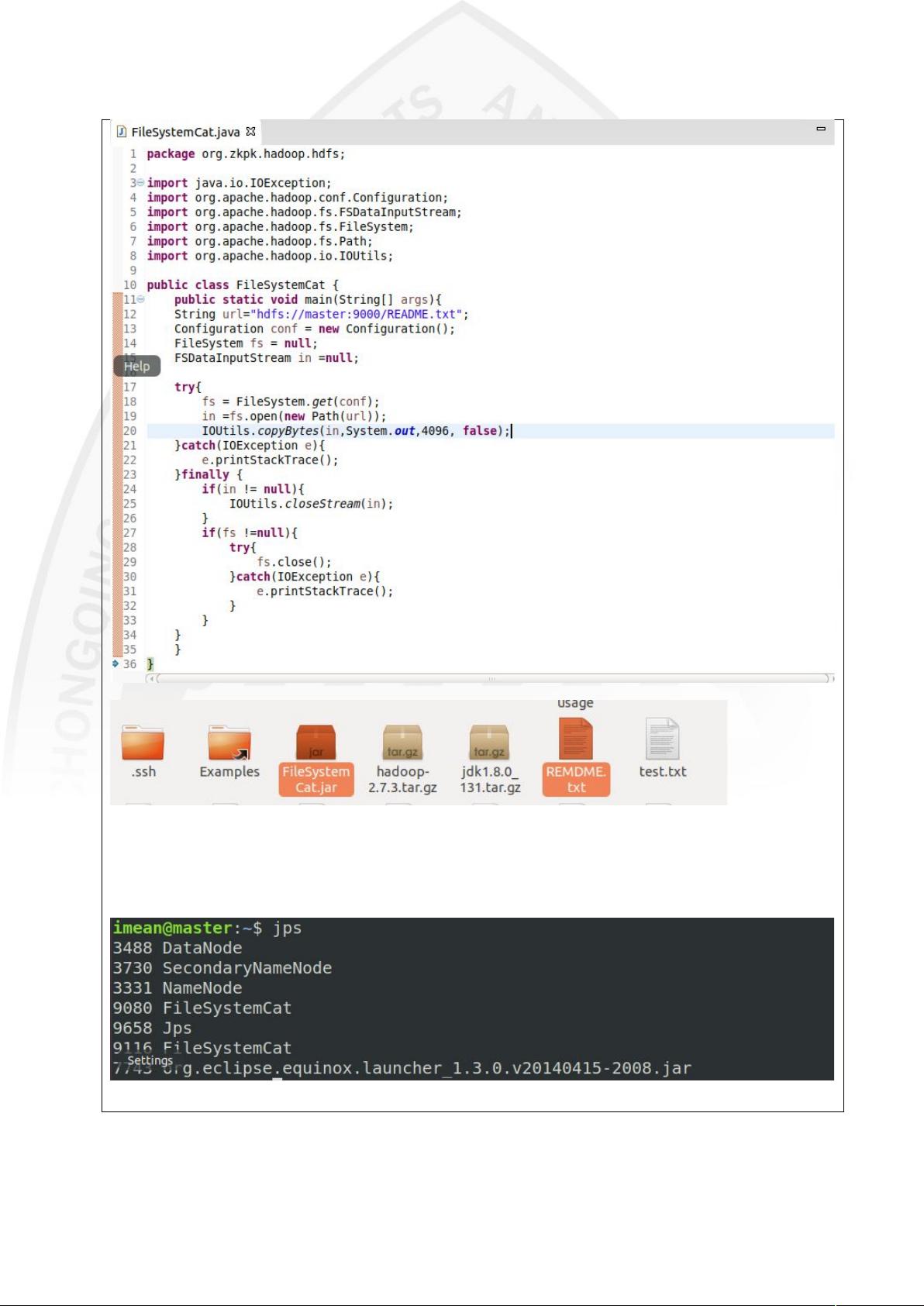
(5)HDFS:文件创建与写入
1启动 集群,并查看相关进程
1编写代码将本地磁盘上的一个文件的内容写入 上的一个新创建的文件中
剩余40页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-07-28 上传
2023-04-06 上传
2018-12-26 上传
2021-03-06 上传
2023-12-07 上传
2023-12-07 上传

JuninC
- 粉丝: 4
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 自动夜灯:自动夜灯在天黑时打开 - 使用 Arduino 和 LDR-matlab开发
- RadarEU-crx插件
- torchinfo:在PyTorch中查看模型摘要!
- FFT的应用,所用数据为局部放电信号,实测可用。matalab代码有详细注释
- 邦德游戏
- LTI 系统的 POT:LTI 系统的参数化[非线性]优化工具-matlab开发
- Information-System-For-Police:警务协助申请系统
- Mondkalender-crx插件
- 麦田背景的商务下载PPT模板
- tsdat:时间序列数据实用程序,用于将标准化,质量控制和转换声明性地应用于数据流
- ubersicht-quote-of-the-day:他们说Übersicht的当日行情
- intensivao_python:主题标签treinamentosintensivãopython
- 豆瓣网小说评论爬虫程序
- bdf_ChanOps:在 BDF 上读、写和执行任何数学运算的函数。-matlab开发
- 幕墙节点示意图
- Shalini-Blue55:蓝色测试55
