高维相似性搜索的问题分析
版权申诉
72 浏览量
更新于2024-06-25
收藏 3.63MB PDF 举报
"这篇文档是VLDB 2008会议上关于高维相似性搜索问题的论文节选,由Stephen Blott和Roger Weber撰写。文章探讨了在大规模图像集合中进行相似性搜索的挑战,主要关注高维特征空间中的相似性搜索困境。作者们回顾了十年前(即VLDB 1998)对于相似性搜索的研究,当时已经认识到高维空间的特性对搜索性能的影响,并进行了定量分析和性能研究。"
正文:
在信息技术领域,尤其是在数据库和数据挖掘中,相似性搜索是一种关键的技术,用于查找与给定对象在某些方面具有相似性的其他对象。在本文档中,Stephen Blott和Roger Weber深入讨论了高维相似性搜索所面临的问题。他们指出,随着数据维度的增加,搜索效率和准确性会受到严重影响,这被称为“高维灾难”或“维度诅咒”。
1. 相似性搜索的重要性:
在图像检索、语音识别、文本分类等应用中,相似性搜索至关重要。例如,在大型图像集合中,我们可能希望找到与特定查询图像最相似的图片。然而,随着数据集的增长,如何快速准确地找到这些相似项成为一个复杂的问题。
2. 高维空间的特性:
高维空间的特性对相似性搜索带来了挑战。在高维空间中,数据点分布变得更加稀疏,导致原本近似的对象在度量上看起来非常遥远,而原本相距很远的对象可能看起来却很接近。这种现象被称为“近邻失真”,使得传统的距离度量在高维空间中变得不可靠。
3. VLDB 1998的分析:
在1998年的VLDB会议上,Weber、Schek和Blott进行了对高维相似性搜索方法的定量分析和性能研究。他们发现,随着维度的增加,数据点之间的欧几里得距离变得难以区分,从而影响了基于距离的搜索算法的性能。
4. VA-File分析:
VLDB 1998的研究中提到的VA-File是一种针对高维数据的索引结构,旨在优化相似性搜索。然而,论文揭示了即使在这样的索引结构下,高维数据的复杂性也会导致查询效率降低和存储需求增大。
5. 当前问题的探讨:
十年后的VLDB 2008会议上,作者们重新审视了这个问题,指出尽管过去十年中有许多技术进步,但高维相似性搜索的问题依然存在。他们可能探讨了新的解决方案,如降维技术(如主成分分析PCA)、局部敏感哈希(LSH)和其他近似搜索方法,以应对高维空间的挑战。
这篇论文强调了高维相似性搜索的困难以及需要不断改进的紧迫性。随着大数据时代的到来,解决这些问题对于提高各种应用程序的性能至关重要,包括推荐系统、搜索引擎优化和机器学习模型的训练。未来的解决方案可能会结合更高效的索引结构、优化的近似算法以及利用机器学习来更好地理解高维数据的复杂性。
VLDB 2008 – What’s Wrong with High-Dimensional Similarity Search? 14 of 62
So, high-dimensional spaces are odd . . .
. . . but how does that affect the perf ormance of search struc tures?
Stephen Blott and Roger Weber
VLDB 2008 – What’s Wrong with High-Dimensional Similarity Search? 15 of 62
Analysis – Access Probabilities
Given some arbitrary query,
what is the probability that a particular r egion must be accessed?
Stephen Blott and Roger Weber
VLDB 2008 – What’s Wrong with High-Dimensional Similarity Search? 12 of 62
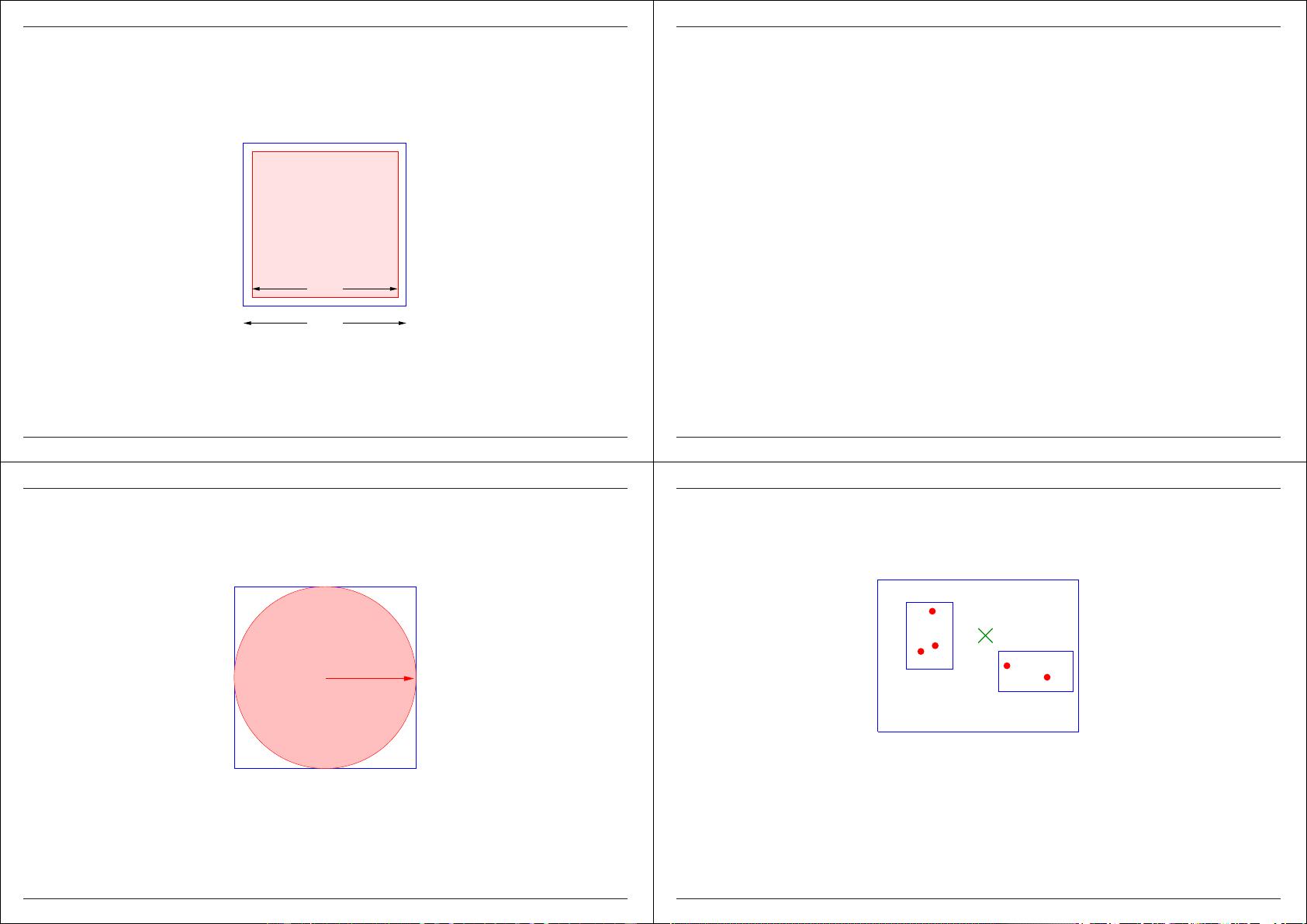
Oddity 2
Consider a
really big square search region of size s, say s = 0.95:
0.95
data space
target region
1.0
But with d = 100:
probability of a point being in this region is 0.95
100
≈ 0.0059
Stephen Blott and Roger Weber
VLDB 2008 – What’s Wrong with High-Dimensional Similarity Search? 13 of 62
Oddity 3
Same game, but with largest possible spher e as the target:
data space
target region
0.5
For d = 40:
volume of sphere is 3.278 × 10
−21
all the space is in the corners
require 3 × 10
20
points to expect, on a ver a ge, one to be in this sphere
Stephen Blott and Roger Weber
剩余15页未读,继续阅读
2023-03-31 上传
2023-06-06 上传
2023-05-05 上传
2023-11-29 上传
2023-06-11 上传
2023-06-06 上传
2024-06-18 上传
2023-06-12 上传


白话机器学习
- 粉丝: 1w+
- 资源: 7673
 我的内容管理
展开
我的内容管理
展开







最新资源
- WPF渲染层字符绘制原理探究及源代码解析
- 海康精简版监控软件:iVMS4200Lite版发布
- 自动化脚本在lspci-TV的应用介绍
- Chrome 81版本稳定版及匹配的chromedriver下载
- 深入解析Python推荐引擎与自然语言处理
- MATLAB数学建模算法程序包及案例数据
- Springboot人力资源管理系统:设计与功能
- STM32F4系列微控制器开发全面参考指南
- Python实现人脸识别的机器学习流程
- 基于STM32F103C8T6的HLW8032电量采集与解析方案
- Node.js高效MySQL驱动程序:mysqljs/mysql特性和配置
- 基于Python和大数据技术的电影推荐系统设计与实现
- 为ripro主题添加Live2D看板娘的后端资源教程
- 2022版PowerToys Everything插件升级,稳定运行无报错
- Map简易斗地主游戏实现方法介绍
- SJTU ICS Lab6 实验报告解析
