Spark入门指南:基础解析与集群安装
需积分: 9 57 浏览量
更新于2024-07-18
收藏 7.58MB DOCX 举报
"Spark01 基础解析"
Spark是一种由Apache基金会开发的开源大数据处理框架,最初在2009年的加州大学伯克利分校AMPLab诞生,并于2010年开源,2014年成为Apache顶级项目。Spark的核心特性在于其快速、通用和可扩展性,它主要由Scala语言编写,但同时也提供了Java、Python、R等多种编程接口。
Spark的特点主要体现在以下几个方面:
1. **内存计算**:Spark通过将数据存储在内存中,实现了比传统Hadoop MapReduce更快的计算速度,尤其是在迭代计算和交互式查询中。
2. **弹性**:Spark能够运行在多种集群管理模式下,如Standalone、Hadoop YARN、Mesos或Kubernetes,这使得它具有很好的灵活性和适应性。
3. **统一的计算模型**:Spark支持批处理、流处理、图形计算和机器学习等多种计算类型,提供了一个全面的大数据处理解决方案。
4. **易用性**:Spark提供了Spark Shell,一个交互式的命令行工具,使得用户可以方便地进行数据探索和测试。
5. **丰富的生态系统**:Spark有多个子项目,如Spark SQL(用于结构化数据处理)、Spark Streaming(用于实时流处理)、GraphX(用于图形处理)、MLlib(机器学习库)和SparkR(R语言接口),它们共同构建了一个完整的数据分析栈。
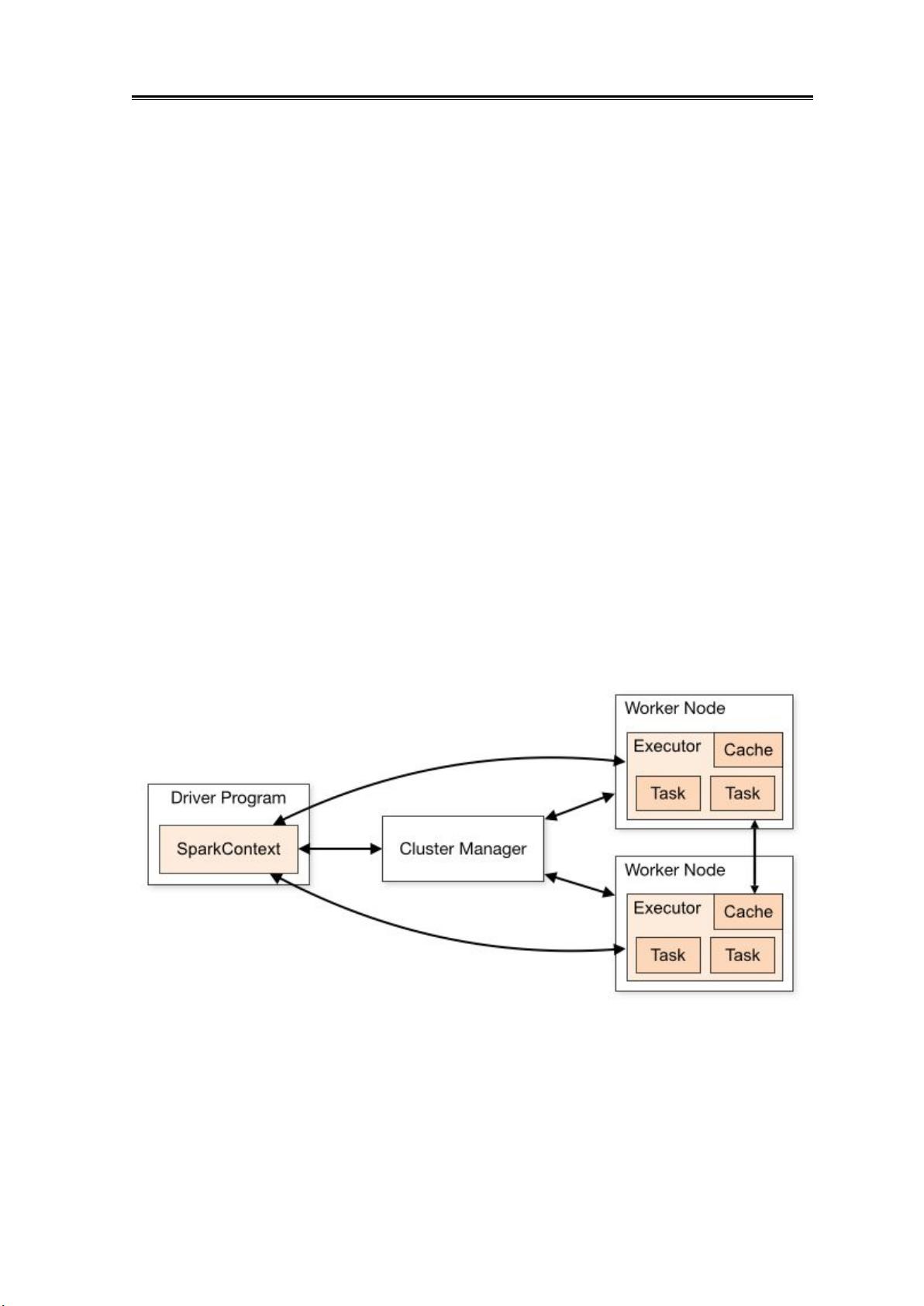
在安装Spark集群时,我们需要了解集群中的不同角色,如Master和Worker节点,以及如何配置这些节点。对于Standalone模式,需要下载Spark安装包,配置Master和Worker节点,以及JobHistoryServer来记录应用日志。若选择在Yarn上运行Spark,还需要进行相应的配置以便Spark作业能在Yarn集群上调度执行。
提交Spark应用程序时,可以有多种方式,如直接在Standalone或Yarn集群上提交,或者通过IDEA等集成开发环境进行提交和调试。SparkShell是Spark提供的交互式环境,用户可以直接在Shell中编写和运行代码,比如实现一个简单的WordCount程序。对于更复杂的开发需求,可以在IDEA中创建项目,编写Spark程序,然后通过IDEA的工具进行本地或远程调试。
Spark的核心概念包括RDD(弹性分布式数据集)、DataFrame和Dataset,它们提供了数据处理的基础。RDD是Spark最早的数据抽象,DataFrame和Dataset是Spark SQL引入的,它们提供了更高级别的抽象,支持更丰富的优化和更高的性能。此外,Spark的DAG(有向无环图)执行模型也是其高效运行的关键,它允许任务的优化和重用。
Spark01基础解析涵盖了Spark的基本概念、集群安装步骤、程序执行方法以及核心组件的介绍,为初学者提供了全面的入门指导。通过学习这部分内容,可以建立起对Spark框架的整体理解,并为进一步深入学习和应用Spark打下坚实基础。
应的有两种人群:数据科学家和工程师。
数据科学任务
主要是数据分析领域,数据科学家要负责分析数据并建模,具备 SQL、统
计、预测建模(机器学习)等方面的经验,以及一定的使用 Python、 Matlab 或 R
语言进行编程的能力。
数据处理应用
工程师定义为使用 Spark 开发 生产环境中的数据处理应用的软件开发者,
通过对接 Spark 的 API 实现对处理的处理和转换等任务。
第2章 Spark 集群安装
2.1 集群角色
从物理部署层面上来看,Spark 主要分为两种类型的节点,Master 节点和
Worker 节点,Master 节点主要运行集群管理器的中心化部分,所承载的作用是
分配 Application 到 Worker 节点,维护 Worker 节点,Driver ,Application 的状
态。Worker 节点负责具体的业务运行。
剩余37页未读,继续阅读
117 浏览量
2021-05-06 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情









