大数据与云计算教程:Spark入门及优势解析
版权申诉
84 浏览量
更新于2024-07-07
收藏 1.58MB PPTX 举报
"该资源是一套全面的大数据与云计算教程,涵盖了从Hadoop基础到Spark入门的多个主题,包括Hadoop的安装、MapReduce、YARN、HDFS、Hive、HBase、Pig、Zookeeper、Kafka、Strom、Spark、Oozie、Impala、Solr、Lily、Titan、Neo4j和Elasticsearch等核心技术和工具。课程旨在帮助学习者理解大数据处理的基本概念,并掌握相关工具的使用。"
在大数据领域,Hadoop是一个基础且关键的框架,用于存储和处理大规模数据。Hadoop的两个主要组件是HDFS(Hadoop Distributed File System)和MapReduce,它们共同构成了大数据处理的核心。HDFS提供了分布式文件存储,而MapReduce则是一个用于并行处理和计算的编程模型。Hadoop YARN(Yet Another Resource Negotiator)作为资源管理器,负责任务调度和集群资源分配。
Spark作为Hadoop的替代或补充,以其高效的内存计算和对迭代计算的良好支持而受到青睐。Spark的核心特性包括RDD(弹性分布式数据集),这是一种在内存中保持的数据结构,允许快速的计算和迭代。Spark SQL是Spark处理结构化数据的组件,它可以与Hadoop生态系统中的其他组件(如Hive)无缝集成,提供SQL查询接口,简化了数据分析任务。
此外,课程还涉及了数据处理工具如Hive,一个基于Hadoop的数据仓库工具,用于处理和管理大数据。HBase是一个非关系型数据库,适合实时读取大规模数据。Pig是Hadoop上的数据流语言,提供了Pig Latin,用于编写处理大数据的脚本。Zookeeper则是一个分布式协调服务,管理集群中的配置和服务发现。
Kafka作为一个消息队列系统,处理实时数据流,而Flume用于收集、聚合和移动大量日志数据。Strom用于实时数据处理,可以持续处理无限数据流。Oozie是Hadoop的工作流调度系统,管理Hadoop作业的生命周期。Impala提供了快速的SQL查询功能,与Hadoop生态系统紧密集成。Solr和Elasticsearch是强大的全文搜索引擎,用于快速索引和搜索大量文本数据。
Neo4j是图数据库,用于存储和查询复杂的图形数据结构。Lily和Titan是NoSQL数据库,分别提供了多模型和图数据库的功能。
通过这些课程,学习者将能够深入理解大数据处理的各个方面,包括数据存储、处理、分析和查询,同时熟悉各种工具和技术,提升大数据项目实施和管理的能力。
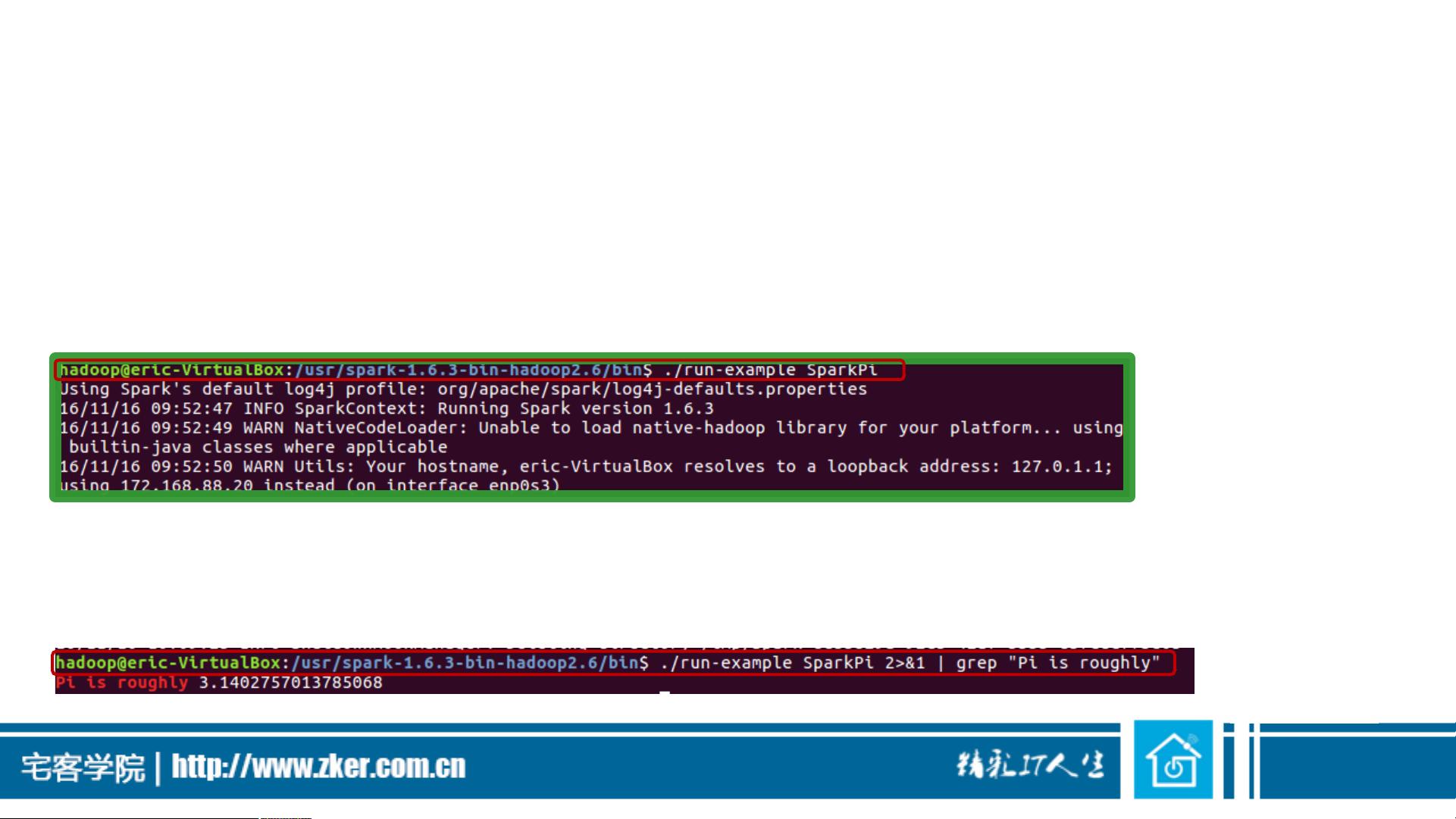
运行Spark示例
• 注意:必须安装Hadoop才能使用Spark,但如果使用Spark过程中没
用到HDFS,不启动Hadoop也是可以的
• 在./examples/src/main目录下有一些Spark的示例程序,有Scala、
Java、Python、R等语言的版本。可以先运行一个示例程序SparkPi(即
计算π的近似值),执行如下命令:
• 执行时会输出非常多的运行信息,输出结果不容易找到,可以通过grep
命令进行过滤(命令中的2>&1可以将所有的信息都输出到stdout中)
:
执行示例

剩余39页未读,继续阅读
2021-12-18 上传
2021-12-18 上传
2021-12-18 上传
2021-12-18 上传
2021-12-18 上传
2021-12-18 上传
2021-12-18 上传
2021-12-18 上传
2021-12-18 上传

passionSnail
- 粉丝: 458
- 资源: 7362
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
