GPU计算优化:CUDA内存优化技术
48 浏览量
更新于2024-07-14
收藏 2.61MB PDF 举报
"NVIDIA GPU Computing Webinars - CUDA Memory Optimization (2011)" 是一场关于CUDA内存优化的高级研讨会,主要关注如何提升基于NVIDIA GPU的计算性能。该研讨会涵盖了硬件概述、内存优化、主机与设备间的数据传输、设备内存优化、性能度量以及算法在GPU上的优化等多个方面。
在CUDA内存优化中,一个关键概念是“有效带宽”的测量,这是评估GPU性能的重要指标。有效带宽是指GPU在单位时间内能够处理的数据量,它对于理解内存系统性能至关重要。为了提高有效带宽,讲座提到了“合并访问”(Coalescing)的概念。在GPU上,当多个线程并行访问连续的内存位置时,可以实现内存访问的合并,从而显著提升效率。
共享内存(Shared Memory)是另一个重要的优化手段。相对于全局内存,共享内存能提供数百倍的速度提升,因为它允许线程块内的线程合作并通过共享内存交换信息,减少了对全局内存的访问,降低了延迟。然而,使用共享内存时应避免高程度的银行冲突,以确保内存访问的高效性。
纹理内存(Textures)作为一种特殊的缓存机制,优化了空间局部性的数据访问。当数据具有空间连续性时,利用纹理内存可以极大地提升读取速度,特别是在图形和物理模拟等应用中。
除了内存优化,研讨会还强调了优化GPU算法的重要性。最大化独立并行性和算术强度(数学操作与带宽使用之比)是两个关键目标。在某些情况下,即使计算效率较低,如果能避免昂贵的数据传输,重新计算可能比缓存数据更优。
这场CUDA内存优化研讨会提供了深入的见解,指导开发者如何充分利用GPU的计算能力,通过内存管理策略和算法优化来提升应用程序的性能,减少数据传输开销,并最大化GPU的计算潜力。对于那些希望深入理解并优化GPU计算性能的开发者来说,这些内容是非常宝贵的资源。
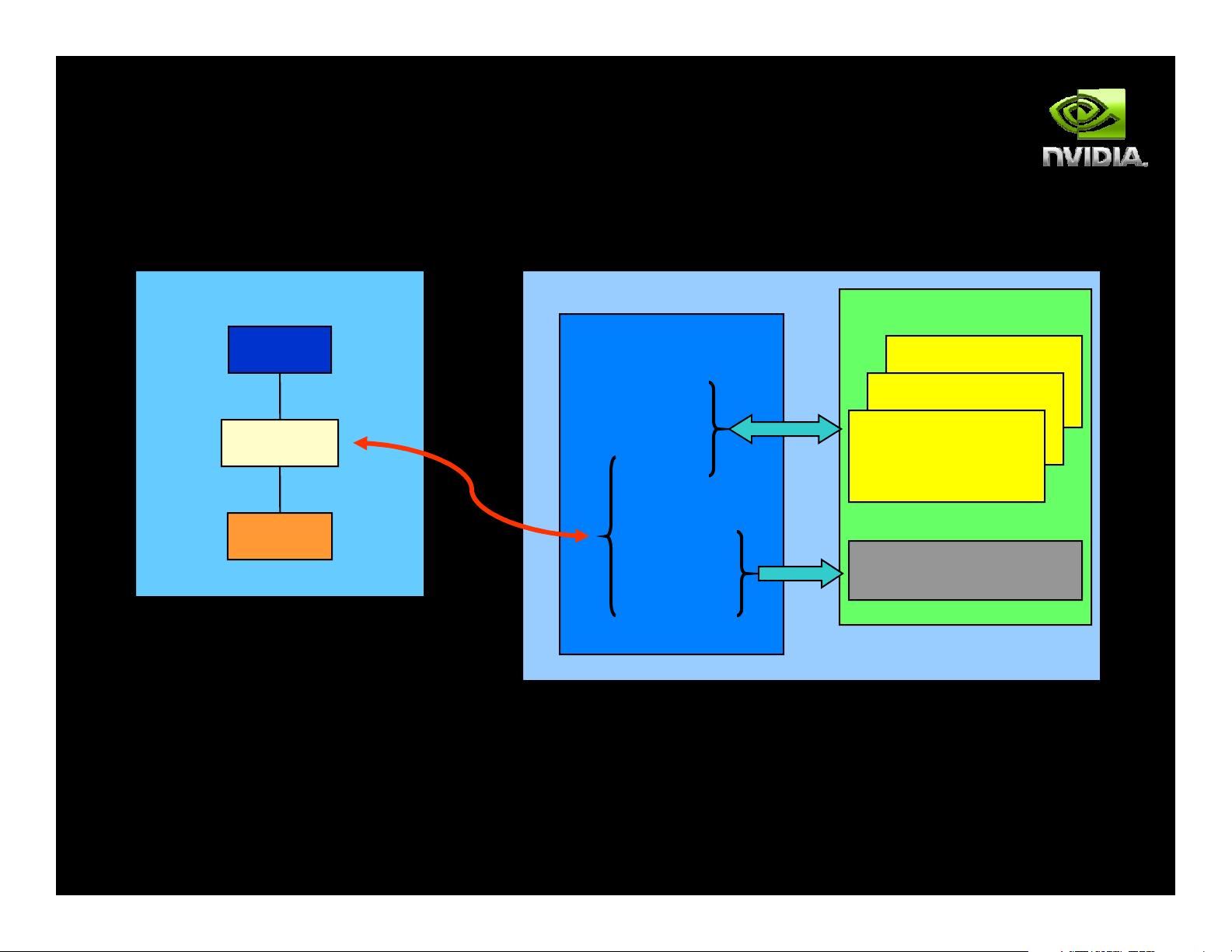
Execution Model
Software Hardware
Threads are executed by scalar processors
Thread
Scalar
Processor
Thread blocks are executed on multiprocessors
Thread blocks do not migrate
© NVIDIA Corporation 2009
9
Thread
Block
Multiprocessor
Thread blocks do not migrate
Several concurrent thread blocks can reside on
one multiprocessor - limited by multiprocessor
resources (shared memory and register file)
...
Grid
Device
A kernel is launched as a grid of thread blocks
Only one kernel can execute on a device at one
time
剩余51页未读,继续阅读
2015-08-13 上传
2021-09-20 上传
2021-06-12 上传
2020-12-23 上传
2023-06-04 上传
2023-08-23 上传
2023-09-28 上传
2024-02-25 上传
2024-05-03 上传

weixin_38611796
- 粉丝: 8
- 资源: 943
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
