
深入理解深入理解SparkStreaming执行模型执行模型
摘要:摘要:Spark Streaming是Spark中最常用的组件之一,将会有越来越多的有流处理需求的用户踏上Spark的使用之路。本文描
述了Spark Streaming的架构并解释如何去提供上述优势,以及一些目前进行的令大家感兴趣的相关后续工作。
正如市面上存在众多可用的流处理引擎,人们经常询问我们Spark Streaming有何独特的优势?那么首先要说的就是Apache
Spark在批处理以及流处理上提供了原生支持。这与别的系统不同之处在于其他系统的处理引擎要么只专注于流处理,要么只
负责批处理且仅提供需要外部实现的流处理API接口而已。Spark 凭借其执行引擎以及统一的编程模型可实现批处理与流处
理,这就是与传统流处理系统相比Spark Streaming所具备独一无二的优势。尤其特别体现在以下四个重要部分:
能在故障报错与straggler的情况下迅速恢复状态;
更好的负载均衡与资源使用;
静态数据集与流数据的整合和可交互查询;
内置丰富高级算法处理库(SQL、机器学习、图处理)。
本文,我们将描述Spark Streaming的架构并解释如何去提供上述优势。紧接着我们还会讨论一些目前正在进行令大家感兴趣
的相关后续工作。
流处理架构-过去与现在
当前分布式流处理管道执行方式如下所述:
1. 接收来自数据源的流数据(比如时日志、系统遥测数据、物联网设备数据等等),处理成为数据摄取系统,比如Apache
Kafka、Amazon Kinesis等等。
2. 在集群上并行处理数据。这也是设计流处理引擎的关键所在,我们将在下文中做出更细节性的讨论。
3. 输出结果存放至下游系统(例如HBase、Cassandra, Kafka等等)。
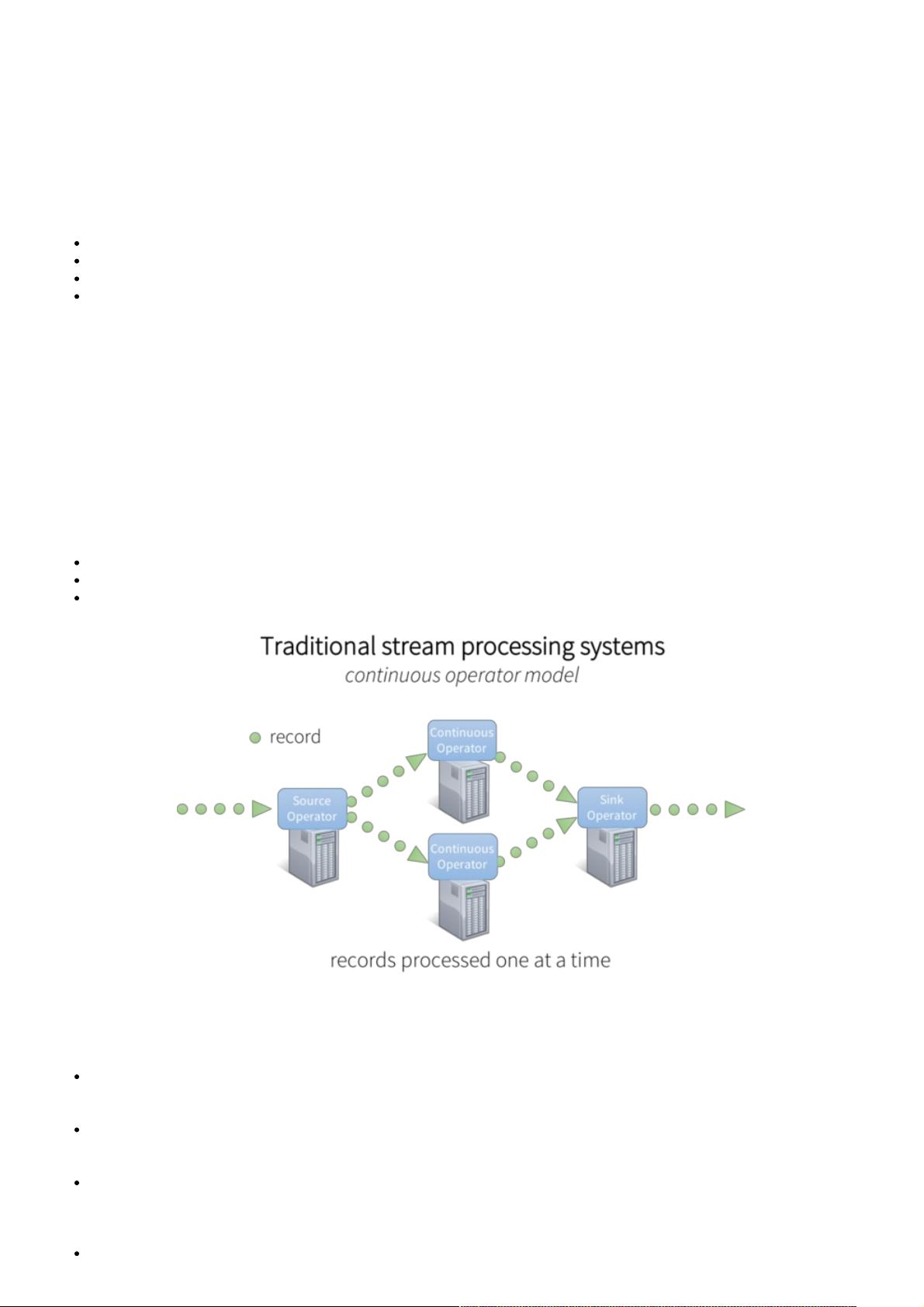
为了处理这些数据,大部分传统的流处理系统被设计为连续算子 模型,其工作方式如下:
有一系列的工作节点,每组节点运行一至多个连续算子;
对于流数据,每个连续算子一次处理一条记录,并且将记录传输给管道中别的算子;
源算子从摄入系统接收数据,接着沉算子输出到下游系统。
图1:传统流处理系统架构
连续算子是一种较为简单、自然的模型。然而,随着如今大数据时代下,数据规模的不断扩大以及越来越复杂的实时分析,这
个传统的架构也面临着严峻的挑战。因此,我们设计Spark Streaming就是为了解决如下几点需求:
故障迅速恢复–数据越庞大,出现节点故障与节点运行变慢(例如straggler)情况的概率也越来越高。因此,系统要是能
够实时给出结果,就必须能够自动修复故障。可惜在传统流处理系统中,在这些工作节点静态分配的连续算子要迅速完成
这项工作仍然是个挑战;
负载均衡–在连续算子系统中工作节点间不平衡分配加载会造成部分节点性能的bottleneck(运行瓶颈)。这些问题更常
见于大规模数据与动态变化的工作量面前。为了解决这个问题,那么要求系统必须能够根据工作量动态调整节点间的资
源分配;
统一的流处理与批处理以及交互工作–在许多用例中,与流数据的交互是很有必要的(毕竟所有流系统都将这置于内存
中)或者与静态数据集结合(例如pre-computed model)。这些都很难在连续算子系统中实现,当系统动态地添加新算
子时,并没有为其设计临时查询功能,这样大大的削弱了用户与系统的交互能力。因此我们需要一个引擎能够集成批处
理、流处理与交互查询;
高级分析(例如机器学习、SQL查询等等)–一些更复杂的工作需要不断学习和更新数据模型,或者利用SQL查询流数
下载后可阅读完整内容,剩余4页未读,立即下载

weixin_38653602
- 粉丝: 6
- 资源: 937
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++标准程序库:权威指南
- Java解惑:奇数判断误区与改进方法
- C++编程必读:20种设计模式详解与实战
- LM3S8962微控制器数据手册
- 51单片机C语言实战教程:从入门到精通
- Spring3.0权威指南:JavaEE6实战
- Win32多线程程序设计详解
- Lucene2.9.1开发全攻略:从环境配置到索引创建
- 内存虚拟硬盘技术:提升电脑速度的秘密武器
- Java操作数据库:保存与显示图片到数据库及页面
- ISO14001:2004环境管理体系要求详解
- ShopExV4.8二次开发详解
- 企业形象与产品推广一站式网站建设技术方案揭秘
- Shopex二次开发:触发器与控制器重定向技术详解
- FPGA开发实战指南:创新设计与进阶技巧
- ShopExV4.8二次开发入门:解决升级问题与功能扩展
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


