Kafka深度解析:分布式消息系统的架构与优势
需积分: 10 14 浏览量
更新于2024-07-19
收藏 3.18MB PDF 举报
"Kafka设计解析"
Kafka是一个由LinkedIn开发并广泛应用于各种场景的分布式消息系统,其核心设计目标是实现高吞吐、低延迟的消息传递,并且具有良好的可扩展性和数据持久化能力。Kafka最初是为了解决LinkedIn的活动流数据和运营数据处理需求,现在则被众多开源分布式处理系统如Cloudera、Apache Storm和Spark等集成。
Kafka的主要特点包括:
1. **高持久化**:Kafka能够在O(1)的时间复杂度内实现消息的持久化,这意味着即使面对大量数据,它也能保持高效的读写性能,支持TB级以上的数据存储。
2. **高吞吐**:Kafka在普通的商用硬件上可以实现每秒处理数十万条消息,满足大规模数据传输的需求。
3. **消息分区与顺序保证**:Kafka支持消息分区,每个分区内的消息按照严格的顺序进行传输,这对于需要顺序保证的业务场景非常重要。
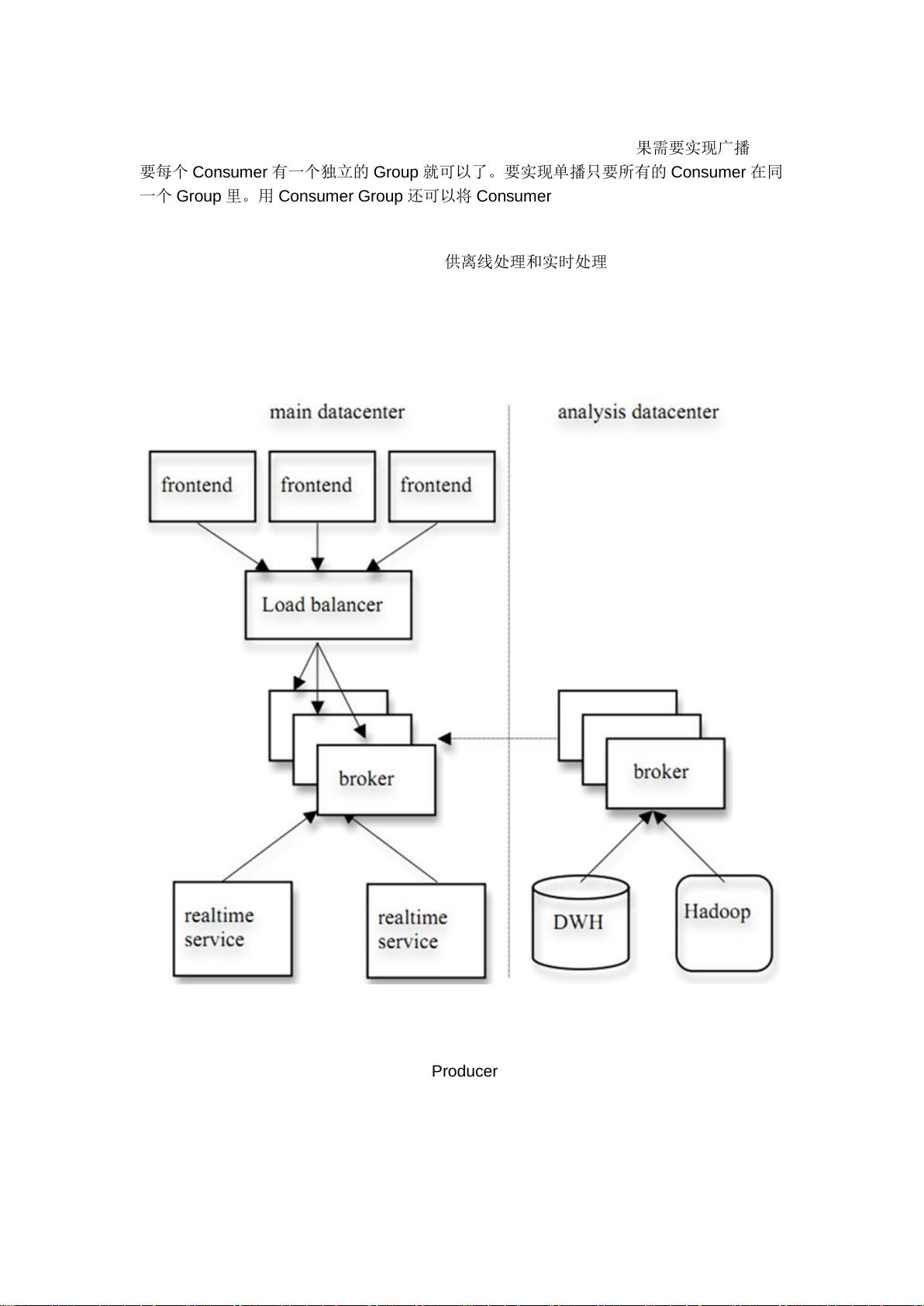
4. **混合数据处理**:Kafka不仅支持实时数据处理,还能够与离线数据处理系统配合,提供灵活的数据处理方案。
5. **水平扩展**:Kafka可以通过添加更多的服务器轻松地进行水平扩展,以应对不断增长的负载。
**使用消息系统的理由**:
1. **解耦**:消息系统使得生产者和消费者之间无需直接交互,降低了两者之间的耦合度,允许系统组件独立演化。
2. **容错性**:消息队列提供了错误恢复机制,如果消费者出现问题,消息不会丢失,可以在消费者恢复后重新处理。
3. **异步处理**:消息队列可以将耗时的操作异步化,提高系统的响应速度。
4. **流量控制**:通过消息队列,可以平滑系统间的流量波动,避免下游服务因瞬间高流量而崩溃。
5. **批量处理**:消息积压可以提供批量处理的机会,提高处理效率。
Kafka在实际应用中,可以用于日志收集、用户行为追踪、实时数据分析等多种场景。随着大数据和实时处理需求的增长,Kafka的重要性日益凸显,成为构建现代数据基础设施的关键组件。无论是大型企业还是初创公司,都可以从Kafka的高效和弹性中受益。
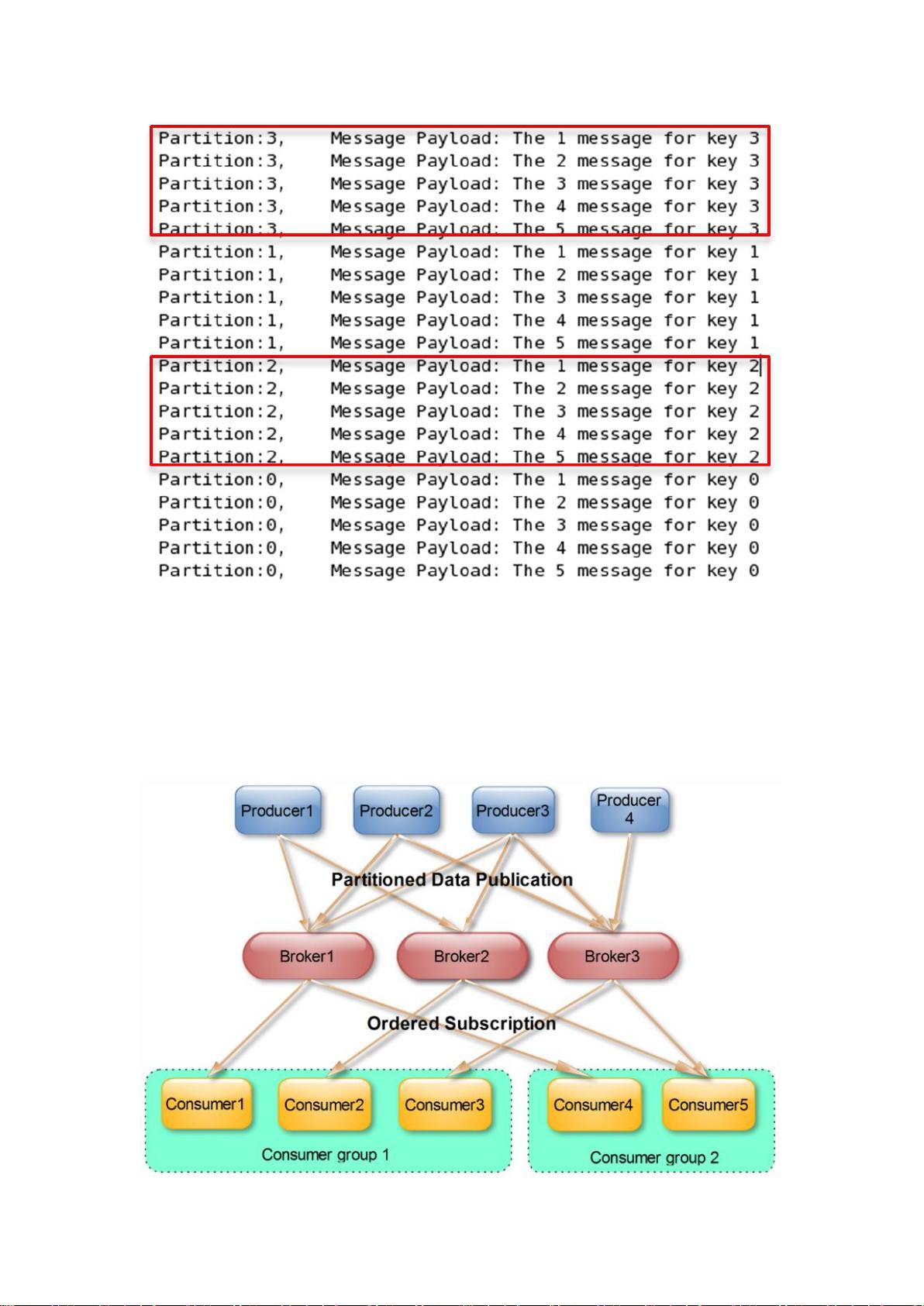
Consumer Group
(本节所有描述都是基于 Consumer hight level API 而非 low level API)。
使用 Consumer high level API 时,同一 Topic 的一条消息只能被同一个 Consumer Group
内的一个 Consumer 消费,但多个 Consumer Group 可同时消费这一消息。

剩余56页未读,继续阅读
2021-01-27 上传
2015-12-11 上传
2021-02-25 上传
2023-08-29 上传
2023-12-02 上传
2023-08-30 上传
2023-07-27 上传
2023-11-03 上传
2024-07-24 上传

lp5563226
- 粉丝: 0
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 多模态联合稀疏表示在视频目标跟踪中的应用
- Kubernetes资源管控与Gardener开源软件实践解析
- MPI集群监控与负载平衡策略
- 自动化PHP安全漏洞检测:静态代码分析与数据流方法
- 青苔数据CEO程永:技术生态与阿里云开放创新
- 制造业转型: HyperX引领企业上云策略
- 赵维五分享:航空工业电子采购上云实战与运维策略
- 单片机控制的LED点阵显示屏设计及其实现
- 驻云科技李俊涛:AI驱动的云上服务新趋势与挑战
- 6LoWPAN物联网边界路由器:设计与实现
- 猩便利工程师仲小玉:Terraform云资源管理最佳实践与团队协作
- 类差分度改进的互信息特征选择提升文本分类性能
- VERITAS与阿里云合作的混合云转型与数据保护方案
- 云制造中的生产线仿真模型设计与虚拟化研究
- 汪洋在PostgresChina2018分享:高可用 PostgreSQL 工具与架构设计
- 2018 PostgresChina大会:阿里云时空引擎Ganos在PostgreSQL中的创新应用与多模型存储
