

目 录
1 实验过程 .......................................................................................................... 1
1.1
1.2
1.3
问题实质性思考.................................................................................................................................. 1
分析属性集和目标类.......................................................................................................................... 1
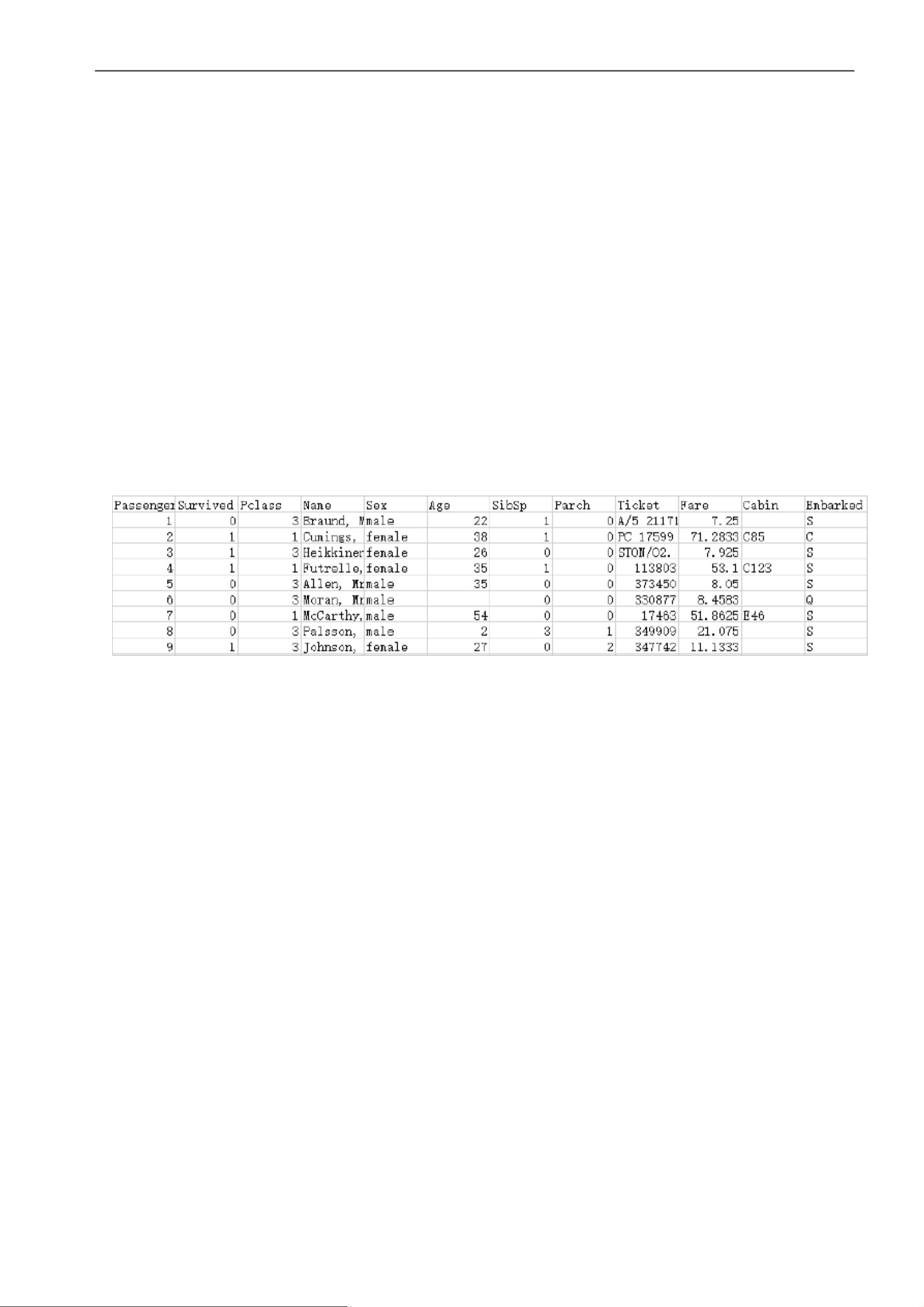
理解数据和认识数据,完成数据的初步探索。.............................................................................. 2
数据认识和理解 .......................................................................................................................... 21.3.1
1.4 数据预处理.......................................................................................................................................... 7
去除无关属性 .............................................................................................................................. 7
缺失值处理 .................................................................................................................................. 7
数据离散化 .................................................................................................................................. 8
数据数值化 .................................................................................................................................. 9
衍生变量.................................................................................................................................... 10
1.4.1
1.4.2
1.4.3
1.4.4
1.4.5
1.5 建立模型、分析模型、比较模型.................................................................................................... 12
C5.0 模型.................................................................................................................................... 13
C&R 树........................................................................................................................................ 16
贝叶斯网络 ................................................................................................................................ 18
SVM 模型 ................................................................................................................................... 20
神经网络模型 ............................................................................................................................ 21
1.5.1
1.5.2
1.5.3
1.5.4
1.5.5
1.6 模型的比较........................................................................................................................................ 26
2 问题反馈与收获 ............................................................................................. 26
2.1
2.2
问题与解决办法................................................................................................................................ 27
发现与收获........................................................................................................................................ 27
3 指导教师评语及成绩:.................................................................................. 27
剩余32页未读,继续阅读

若♡
- 粉丝: 6287
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 多模态联合稀疏表示在视频目标跟踪中的应用
- Kubernetes资源管控与Gardener开源软件实践解析
- MPI集群监控与负载平衡策略
- 自动化PHP安全漏洞检测:静态代码分析与数据流方法
- 青苔数据CEO程永:技术生态与阿里云开放创新
- 制造业转型: HyperX引领企业上云策略
- 赵维五分享:航空工业电子采购上云实战与运维策略
- 单片机控制的LED点阵显示屏设计及其实现
- 驻云科技李俊涛:AI驱动的云上服务新趋势与挑战
- 6LoWPAN物联网边界路由器:设计与实现
- 猩便利工程师仲小玉:Terraform云资源管理最佳实践与团队协作
- 类差分度改进的互信息特征选择提升文本分类性能
- VERITAS与阿里云合作的混合云转型与数据保护方案
- 云制造中的生产线仿真模型设计与虚拟化研究
- 汪洋在PostgresChina2018分享:高可用 PostgreSQL 工具与架构设计
- 2018 PostgresChina大会:阿里云时空引擎Ganos在PostgreSQL中的创新应用与多模型存储
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


