Spark、Zookeeper与Kafka大数据技术详解
"《大数据学习笔记》 - ewang - 2016-9-21"
本资源是一份详细的大数据技术学习笔记,涵盖了Spark、ZooKeeper、Kafka和Hive四个重要组件的学习内容。
第一部分 Spark学习
1. Spark介绍
Spark作为一个快速、通用且可扩展的计算系统,主要目标是加速大数据处理速度。Spark不仅与Hadoop MapReduce兼容,还提供了更高效的计算模型,特别适合迭代计算和交互式查询。Spark的核心特性包括弹性(resilient)、分布式(distributed)、数据集(dataset)以及内存计算(in-memory computing)。
2. Spark弹性分布数据集(RDD)
RDD是Spark的基础数据结构,是不可变、分区的记录集合。相比MapReduce,RDD在内存中进行计算,避免了磁盘I/O,从而提高了效率。RDD支持转换(transformations)和动作(actions),并具有容错性。
3. Spark安装与编程
学习内容包括Spark的安装、使用Spark Shell进行交互式编程,以及RDD的编程模式,如转换和动作的操作,以及如何控制数据持久化。
4. Spark调度与高级编程
涵盖Spark应用程序的提交,调度策略,以及高级编程特性,如变量和不同类型RDD的操作。
第二部分 ZooKeeper学习
1. ZooKeeper介绍
ZooKeeper是一个分布式协调服务,用于管理分布式系统的配置信息、命名服务、分布式同步、组服务等。它为分布式应用提供一致性服务。
2. ZooKeeper基本组成与工作流程
讲解了ZooKeeper的组件和工作原理,包括领导者选举、数据模型等。
第三部分 Kafka学习
1. Kafka介绍
Kafka是一个高吞吐量的分布式消息系统,适用于实时数据流处理。它提供发布订阅模型和队列模型,以及与ZooKeeper的集成。
2. Kafka集群架构与工作流程
解析Kafka的基本架构,包括生产者、消费者和主题(topics),以及Kafka与ZooKeeper的关系。
第四部分 Hive学习
1. Hive介绍
Hive是基于Hadoop的数据仓库工具,用于简化对大规模数据集的查询和分析。它提供了一种SQL-like的语言HiveQL,方便用户进行数据ETL(抽取、转换、加载)和分析。
2. Hive数据类型、操作、查询
包括Hive的数据类型、数据库和表的操作,以及HiveQL的基本查询语法,如SELECT、JOIN、GROUP BY等。
通过这份笔记,读者可以全面了解大数据生态中的这些关键组件,掌握它们的基本概念、使用方法以及如何相互协作处理大规模数据。
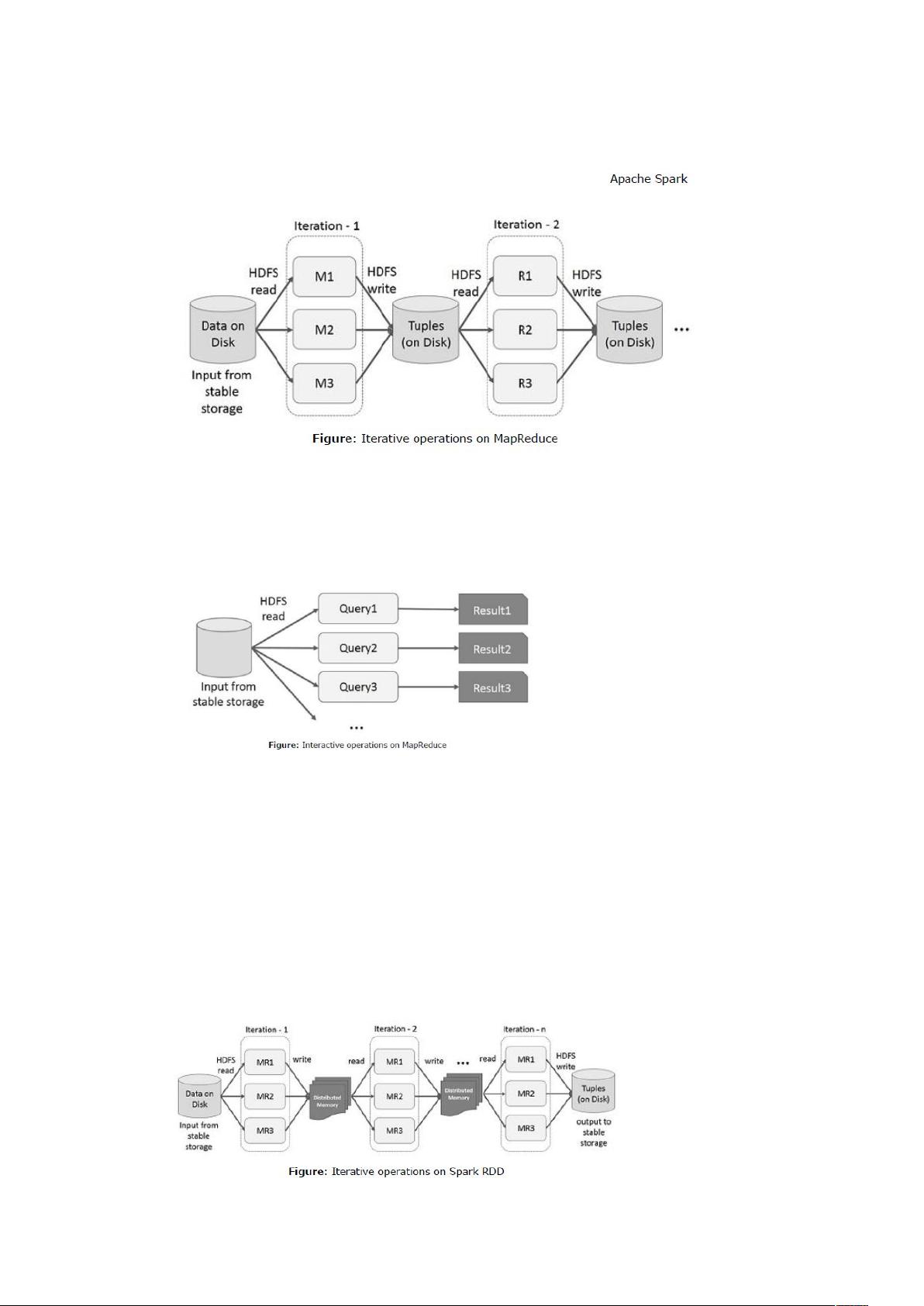
时做 的迭代操作。由于数据复制,磁盘 53 和系列化,使系统变慢。
2.4 MapReduce 进行交互操作
用户对相同的数据子集执行 ):点对点;查询。每个查询会对表存储做磁盘 53 操
作,它严重影响应用程序执行时间。下图说明了目前的框架,同时 做交互查询
的工作方式。
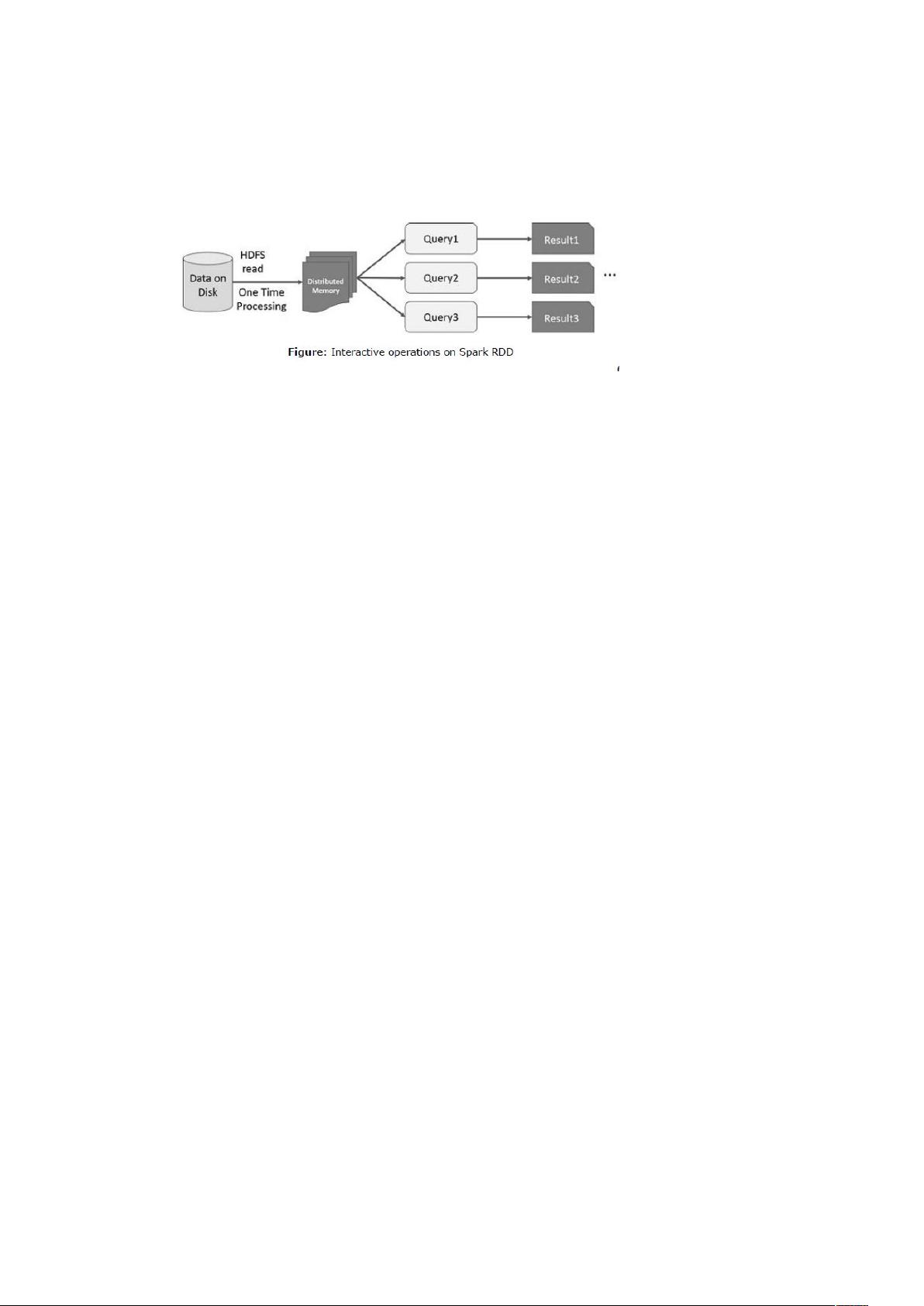
2.5 Spark RDD 数据分享
支持在内存中处理数据。这意味着,它存储横跨的作业的对象的内存状态和对象
那些作业之间共享。在内存中的数据共享是网络和磁盘的 到 倍。
在 上进交互和迭代操作。
2.6 Spark RDD 迭代操作
下面给出的图显示 迭代操作。它把中间结果存储在分布式内存中而不是
,- 存储器中(磁盘),这样会使系统更快。
注意:如果分布式内存(%)足以存储中间结果(作业状态),那么它会在内存上存储
这些结果。

剩余63页未读,继续阅读
2016-11-03 上传
2019-08-23 上传
2020-11-09 上传
2024-03-28 上传

WEL测试
- 粉丝: 4157
- 资源: 47
 我的内容管理
展开
我的内容管理
展开







