HBase深度解析:分布式列式数据库的关键特性
136 浏览量
更新于2024-08-28
收藏 541KB PDF 举报
"Hbase原理分享"
HBase是一个高度可扩展的分布式数据库,它构建于可靠的Hadoop文件系统(HDFS)之上,专为处理大规模数据而设计。HBase的出现是为了满足实时读写和随机访问大数据集的需求,它是Google Bigtable的开源实现。
**HBase的主要特点**
1. **大规模数据存储**:HBase能够处理极大量的数据,一个表可以包含上亿行和上百万列,这种能力使得它非常适合大数据场景。
2. **面向列存储**:HBase支持列式存储,允许按列(或列族)进行存储和权限控制,且可以独立检索特定列或列族的数据,这提供了高效的数据查询能力。
3. **稀疏性**:由于不存储为空的列,HBase可以创建非常稀疏的表,节省存储空间。
4. **无固定模式**:每行都有一个排序的主键(RowKey)和任意多的列,列可以在表中动态增加,使得表结构具有灵活性。
5. **多版本数据**:每个单元格可以有多个版本,版本由插入时的时间戳标识,这提供了历史数据追踪的能力。
6. **数据类型单一**:HBase中所有数据都被视为字节数组,不区分具体的数据类型。
**HBase数据模型**
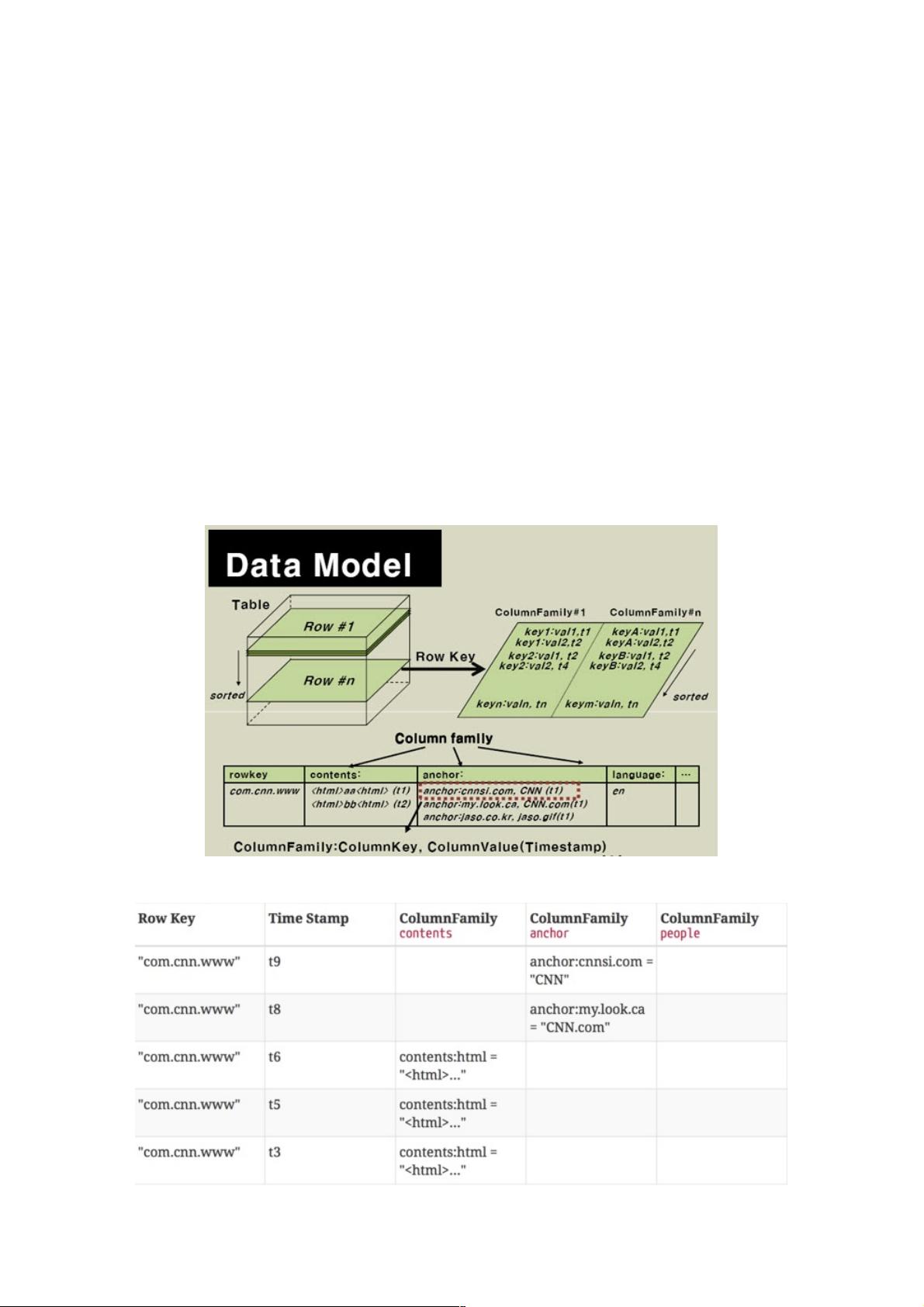
HBase的数据模型分为逻辑数据模型和物理数据模型。在逻辑模型中,未存储数据的单元格在物理上不会占用空间。RowKey是检索记录的关键,可以按单个RowKey或其范围进行访问。RowKey可以是任意字符串,但长度有限制。列被组织成列族,列族是表的Schema的一部分,必须在创建表时定义,而列可以在使用过程中动态添加。列族提供了访问控制和资源管理的便利。
在HBase中,列名由列族前缀加列标识组成,如"courses:history"和"courses:math"属于"courses"列族。列族的控制权限有助于不同类型的应用管理,例如,某些应用可能有权限添加新数据,而其他应用可能只能读取现有数据或创建继承的列族。
HBase是大数据领域的关键组件,它的设计理念和特性使其在实时大数据处理和存储方面表现出色。理解并掌握HBase的工作原理和数据模型对于有效地利用其功能至关重要。
Hbase原理分享原理分享
一、HBase简介
Hbase是什么
HBase是一种构建在HDFS之上的分布式、面向列、多版本、非关系型的数据库。在需要实时读写、随机访问超大规模数据集
时,可以使用HBase。HBase 是Google Bigtable 的开源实现。
HBase的特点
大:一个表可以有上亿行,上百万列。
面向列:面向列(组)的存储和权限控制,列(组)独立检索。
稀疏:对于为空(NULL)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
无模式:每一行都有一个可以排序的主键和任意多的列,列可以根据需要动态增加,同一张表中不同的行可以有截然不同的
列。
数据多版本:每个单元中的数据可以有多个版本,默认情况下,版本号自动分配,版本号就是单元格插入时的时间戳。
数据类型单一:HBase中的数据都是字符串,没有类型,存储在hbase上的都是字节数组。
二、HBase数据模型
HBase 以表的形式存储数据。表由行和列组成。列划分为若干个列族(row family),如下图所示。
1) HBase的逻辑数据模型
2) HBase的物理数据模型
下载后可阅读完整内容,剩余6页未读,立即下载
2019-03-30 上传
点击了解资源详情
2019-04-20 上传
2022-06-09 上传
2018-02-09 上传
2013-11-19 上传
2012-09-07 上传
点击了解资源详情

weixin_38680247
- 粉丝: 4
- 资源: 922
 我的内容管理
展开
我的内容管理
展开







最新资源
- js-exercises:JavaScript练习,用于训练和保存一些信息
- Python库 | datalab-0.1.1701291453.tar.gz
- Stack-Learner
- practice3:Практическоезадание3
- maheoi
- 西门子PLC工程实例源码第533期:电厂入煤炉程序,内有说明.rar
- 计步器matlab代码-Step-Counting:计步
- akka-spring:测试SPRING扩展提供商
- arcDevProj2
- RWD-
- OpenLD-开源
- fundingsocieities
- 麻风树
- 电网调度matlab代码-WindChaser:直接项目
- 迷你圣诞节物联网展示!-项目开发
- javascript的当当网项目
