Hadoop DataNode心跳分析:命令与处理流程
需积分: 9 200 浏览量
更新于2024-09-13
收藏 194KB DOC 举报
在Hadoop源代码分析的第三十三章中,重点关注的是DataNode与NameNode之间的通信机制,特别是DataNode发送心跳信息的过程。DataNode通过`sendHeartbeat`方法向NameNode报告其当前的状态,这个方法接受的参数包括DatanodeRegistration对象(存储节点的信息)、总容量、已使用空间、剩余空间、正在进行的数据传输数以及接收器计数。DatanodeCommand类包含了多种可能的命令,如数据块复制(DNA_TRANSFER)、数据块失效(DNA_INVALIDATE)、节点关闭(DNA_SHUTDOWN)、重新注册(DNA_REGISTER)、升级完成(DNA_FINALIZE)以及数据块恢复(DNA_RECOVERBLOCK)。
在`FSNamesystem.handleHeartbeat`方法中,首先,系统会通过`getDatanode`方法获取与请求匹配的DatanodeDescriptor,并将其保存在`nodeinfo`变量中。如果现有NameNode上的StorageID与请求不符,`handleHeartbeat`会返回`DatanodeCommand.REGISTER`,促使DataNode重新注册以确保一致性。
如果节点已经被标记为需要关闭(isDecommissioned),会抛出`DisallowedDataNodeException`异常。如果`nodeinfo`为空或节点状态非活跃,也会返回`DatanodeCommand.REGISTER`来激活节点。
处理过程中,`FSNamesystem`还会更新系统的状态信息,包括总容量、已使用容量、剩余容量和总体负载。然后,会检查是否存在恢复数据块、数据块复制、数据块删除或升级等操作的需求。由于一次心跳响应只允许执行一条命令,这些操作按照优先级顺序进行判断。
在构造应答的命令时,会根据`nodeinfo`中的状态和需求选择最合适的命令。这个过程体现了Hadoop分布式系统中节点之间如何保持同步和协调,确保数据的一致性和可靠性。通过深入理解这些源代码细节,开发者可以更好地掌握Hadoop内部的工作原理,并在开发和优化分布式应用时做出更明智的决策。
下面来看一个大家伙:
public DatanodeCommand sendHeartbeat(DatanodeRegistration
nodeReg,
long capacity,
long dfsUsed,
long remaining,
int xmitsInProgress,
int xceiverCount) throws IOException
DataNode 发送到 NameNode 的心跳信息。细心的人会发现,请求的内容还
是 DatanodeRegistration,应答换成 DatanodeCommand 了。
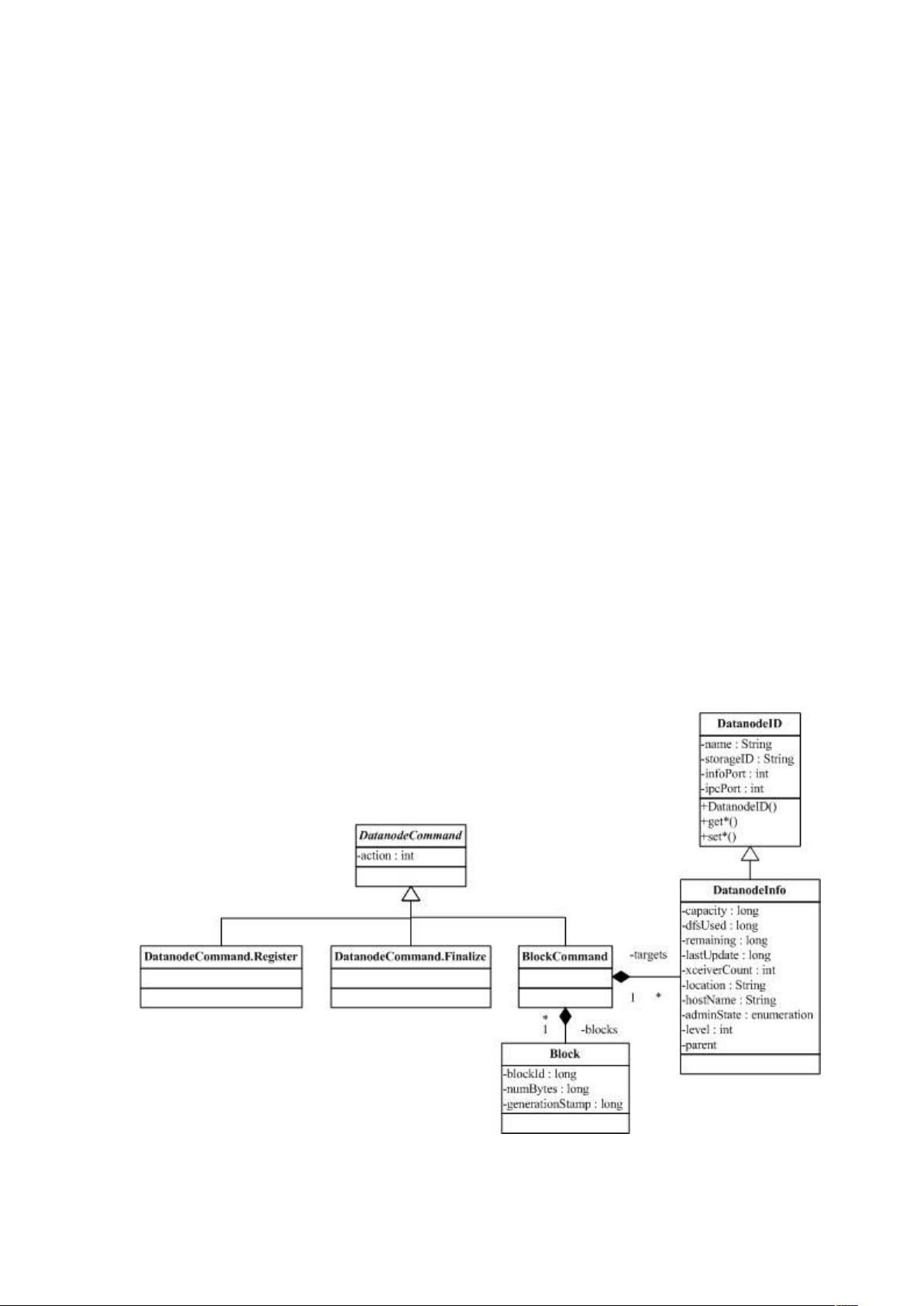
DatanodeCommand 类图如下:
前面介绍 DataNode 时,已经分析过了 DatanodeCommand 支持的命令:
DNA_TRANSFER:拷贝数据块到其他 DataNode
DNA_INVALIDATE:删除数据块
DNA_SHUTDOWN:关闭 DataNode
DNA_REGISTER:DataNode 重新注册
DNA_FINALIZE:提交升级
DNA_RECOVERBLOCK:恢复数据块
下载后可阅读完整内容,剩余7页未读,立即下载
183 浏览量
2024-11-01 上传
303 浏览量
2023-05-30 上传
256 浏览量
2024-10-26 上传

frank_20080215
- 粉丝: 166
- 资源: 1772
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机操作系统课后答案(西安电子科技大学版)
- 通用变频器应用技术.pdf
- 《开源》旗舰电子杂志2008年第4期
- C# 语言的微软官方说明书(权威)
- usb2.0协议 中文版
- 《开源》旗舰电子杂志2008年第3期
- 思科2950CR官方配置命令手册.pdf
- ABB ACS510_01 用户手册中文版
- 打造linux完美桌面
- STC单片机内部资源经典应用大全.PDF
- 进行空间,你的网站及域名的备案详细步骤
- Packt.Publishing.Learn.OpenOffice.org.Spreadsheet.Macro.Programming.Dec.2006.pdf
- 虚拟硬盘系统的实现及应用
- JasperReport3
- C/C++面试大全--算法和知识点详析
- DIV+CSS布局大全
