清华大学刘知远:深度学习在词汇、语义、短语及知识表示中的应用
需积分: 10 159 浏览量
更新于2024-07-18
收藏 13.95MB PPTX 举报
在清华大学自然语言处理实验室(Natural Language Processing Lab, Tsinghua University)的研究背景下,刘知远等人发表了一篇题为《Representation Learning for Word, Sense, Phrase, Document, and Knowledge》的文章,该研究着重探讨了表示学习在自然语言处理中的关键作用。表示学习是机器学习系统中的基础,它涉及如何从原始数据中提取出有用的特征,以便机器能够更好地理解和处理任务。
文章的核心议题包括五个层次的表示学习:单词、词义、短语、文档以及知识的表征。每个层次都对应不同的NLP任务,如词性标注、句法分析和理解等。单词的表征通常是通过两种常见的方法来实现的:
1. One-hot representation(独热编码):这是一种基础的词袋模型方法,每个词用一个向量表示,其中只有一个位置的值为1,其余全为0。例如,"sun"和"star"的one-hot向量可能是这样的:
```
sun: [0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, ...]
star: [0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, ...]
```
这种方法无法捕捉词语之间的语义关系,星星和太阳虽然不相同,但在这种表示下它们的相似度为0。
2. Count-based distributional representation(基于频率的分布表征):这种方法利用词频或共现统计来量化词语之间的相似性,比如TF-IDF(Term Frequency-Inverse Document Frequency)。这种方法试图通过上下文信息捕捉词语的含义,从而更好地反映词语之间的语义关联。
对于词义、短语、文档和知识的表征,文章探讨了更复杂的表示学习策略,可能包括深度学习技术,如深度神经网络(Deep Neural Networks),以及更高级别的语义理解和知识整合。优化表示的目标是找到一组能有效捕获词汇、语义、结构和背景信息的低维嵌入,从而提高机器在自然语言处理任务上的性能。
这篇论文不仅阐述了表示学习的基本原理,还展示了如何在不同层面上进行有效的表示学习,这对于提高自然语言处理系统的智能和准确性具有重要意义。通过深入理解并应用这些技术,研究者们能够构建出更加智能化的系统,以适应不断增长的自然语言处理需求。
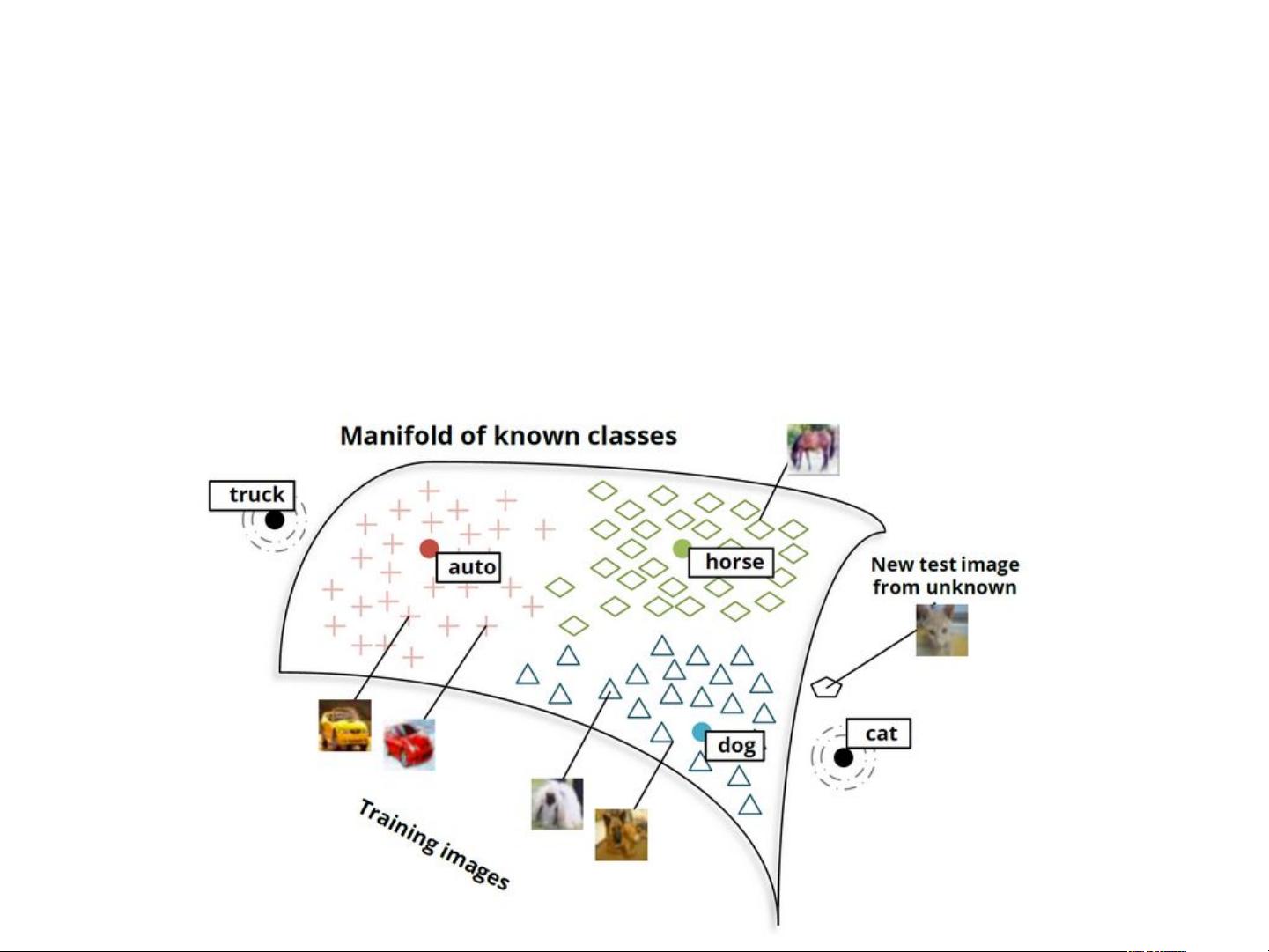
Distributed Word Representation
•
Each word is represented as a dense and real-valued vector in
a low-dimensional space

剩余55页未读,继续阅读
2012-09-02 上传
2023-05-11 上传
2023-05-26 上传
2023-03-16 上传
2024-01-09 上传
2023-05-11 上传
2023-04-06 上传
2023-03-16 上传
2023-05-10 上传

rzhangpku
- 粉丝: 2
- 资源: 15
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
