入门的学习分析中,常用的数据集包括 iris 数据集和 wine 数据集。iris 数据集包含了150个样本,分为3类,每类50个数据,每个样本包含4个特征,分别是花萼长度、花萼宽度、花瓣长度和花瓣宽度。wine 数据集包含了178个样本,分为3类,每类59-71个数据,每个样本包含13个特征,包括酒的化学特性。这些数据集常用于数据分析的入门学习中,帮助初学者对数据分析的基本方法和概念有一个初步的了解。
在数据分析的第六章中,聚类分析是一个重要的内容。聚类分析是指将数据集中的对象按照其相似性分成若干类的方法。俗语说,物以类聚、人以群分。当有一个分类指标时,分类比较容易。但是当有多个指标,要进行分类就不是很容易了。比如,要想把中国的县分成若干类,可以按照自然条件来分:考虑降水、土地、日照、湿度等各方面;也可以考虑收入、教育水准、医疗条件、基础设施等指标。
由于不同的指标项对重要程度或依赖关系是相互不同的,所以也不能用平均的方法,因为这样会忽视相对重要程度的问题。因此,需要进行多元分类,即聚类分析。最早的聚类分析是由考古学家在对考古分类中研究中发展起来的,同时又应用于昆虫的分类中,此后又广泛地应用在天气、生物等方面。
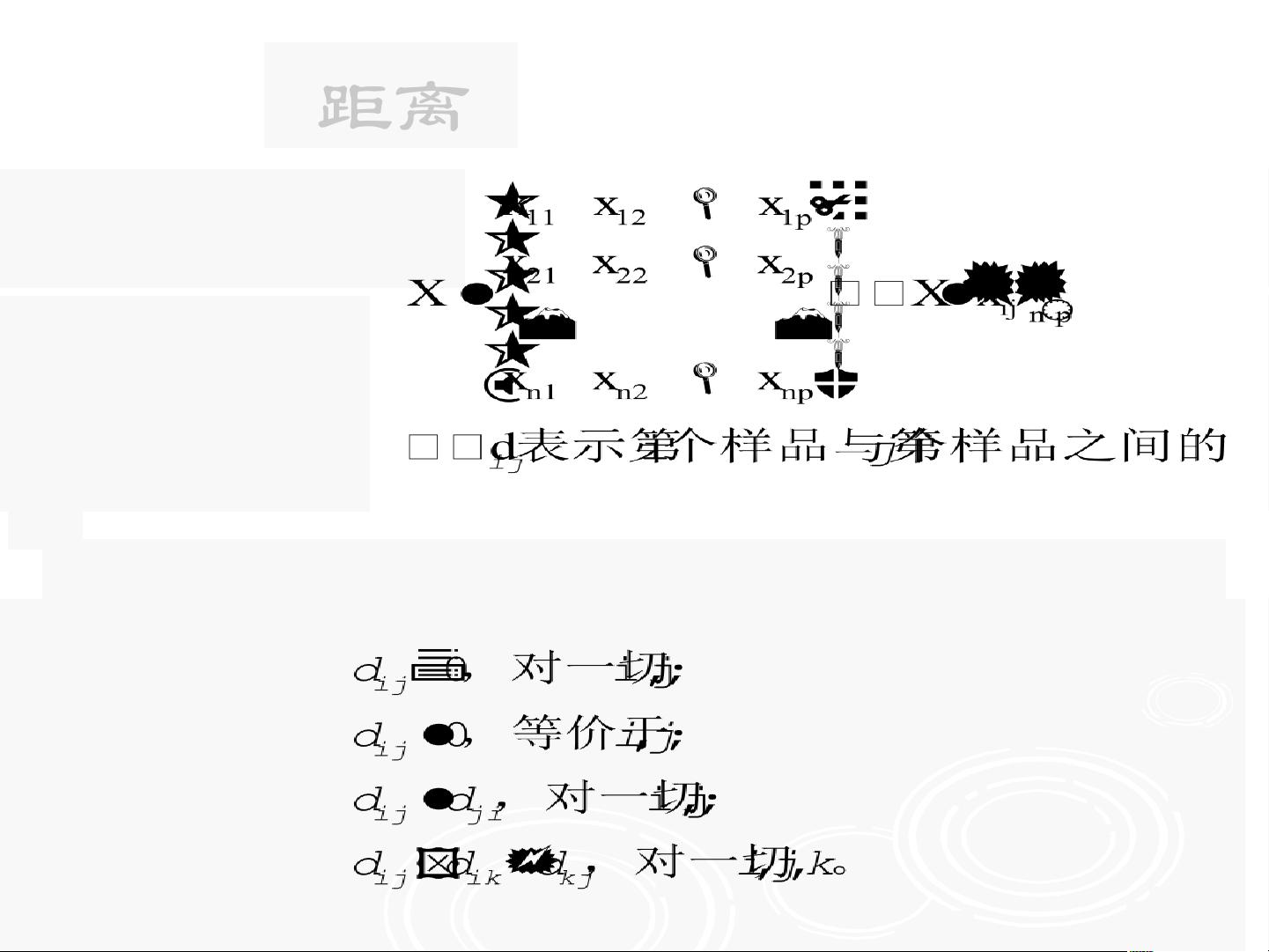
对于一批数据,人们既可以对变量(指标)进行分类(相当于对数据中的列分类),也可以对观测值(事件,样品)来分类(相当于对数据中的行分类)。对变量的聚类称为R型聚类,而对观测值聚类称为Q型聚类。这两种聚类在数学上是对称的,没有什么不同。
聚类分析就是要找出具有相近程度的点或类聚为一类。在聚类分析中,常用的方法有K均值聚类、层次聚类、DBSCAN聚类等。K均值聚类是一种划分方法,根据每个数据点到均值的距离来划分聚类。层次聚类是一种聚合方法,从下到上逐步合并相近的聚类。DBSCAN聚类是一种基于密度的聚类方法,可以识别任意形状的聚类。
总的来说,聚类分析是数据分析中的重要内容,对于数据的分类和理解具有重要意义。可以根据不同的需求和数据特点选择不同的聚类方法,进行数据的分类和分析。通过对数据的聚类分析,可以帮助我们更好地理解数据的内在结构和规律,为后续的数据挖掘和预测建模奠定基础。