深度学习驱动的图像分割技术解析
需积分: 31 140 浏览量
更新于2024-07-16
收藏 2.38MB PDF 举报
"这篇论文《理解深度学习在图像分割中的技术》由Swarnendu Ghosh、Nibaran Das、Ishita Das和Ujjwal Maulik于2019年7月16日撰写,主要探讨了深度学习如何在图像分割领域发挥作用。论文对各种深度学习方法进行了分析,包括卷积神经网络(CNN)、循环神经网络(RNN)、对抗网络(GAN)、自动编码器(Autoencoder)等,并特别关注了这些技术在图像分割上的应用和发展。"
在计算机视觉领域,深度学习已经成为解决像物体检测、定位、识别和无约束环境中的图像分割等复杂任务的有效工具。其中,深度神经网络的各种变体如CNNs因其在处理图像特征提取方面的优越性而受到广泛关注。CNN通过多层次的卷积和池化操作,能够逐步提取图像的局部特征,形成高层语义表示,这对图像分割至关重要。
论文中详细介绍了传统图像分割方法,如阈值分割、区域生长、边缘检测等,然后过渡到深度学习方法。例如,全卷积网络(FCN)是最早用于像素级预测的深度学习模型之一,它将分类网络的反向传播转化为像素级别的分割输出。随后,U-Net等网络结构引入了跳跃连接,增强了细节信息的保留,提高了分割精度。
此外,递归神经网络(RNN)和长短期记忆网络(LSTM)在处理序列数据时表现出色,它们在图像分割中的应用主要体现在处理具有时间依赖性的序列图像上,如视频序列分割。对抗网络(GAN)则通过生成对抗的方式,使得生成的分割结果更加逼真。同时,自编码器(Autoencoder)在图像降噪和异常检测方面有所贡献,其压缩-解压的架构也启发了低秩表示在图像分割中的应用。
论文还分析了各种深度学习技术的独特贡献,比如基于注意力机制的模型,它们能引导网络专注于图像的特定区域,提高分割的准确性。还有,深度强化学习在部分像素级决策任务中也展现出潜力。
这篇论文通过对深度学习在图像分割领域的系统分析,为读者提供了深入的理解,帮助他们可视化这些复杂过程的工作原理。无论是对于研究人员还是实践者,都是一份宝贵的参考资料,能够促进他们在这个快速发展的领域的进一步探索和创新。
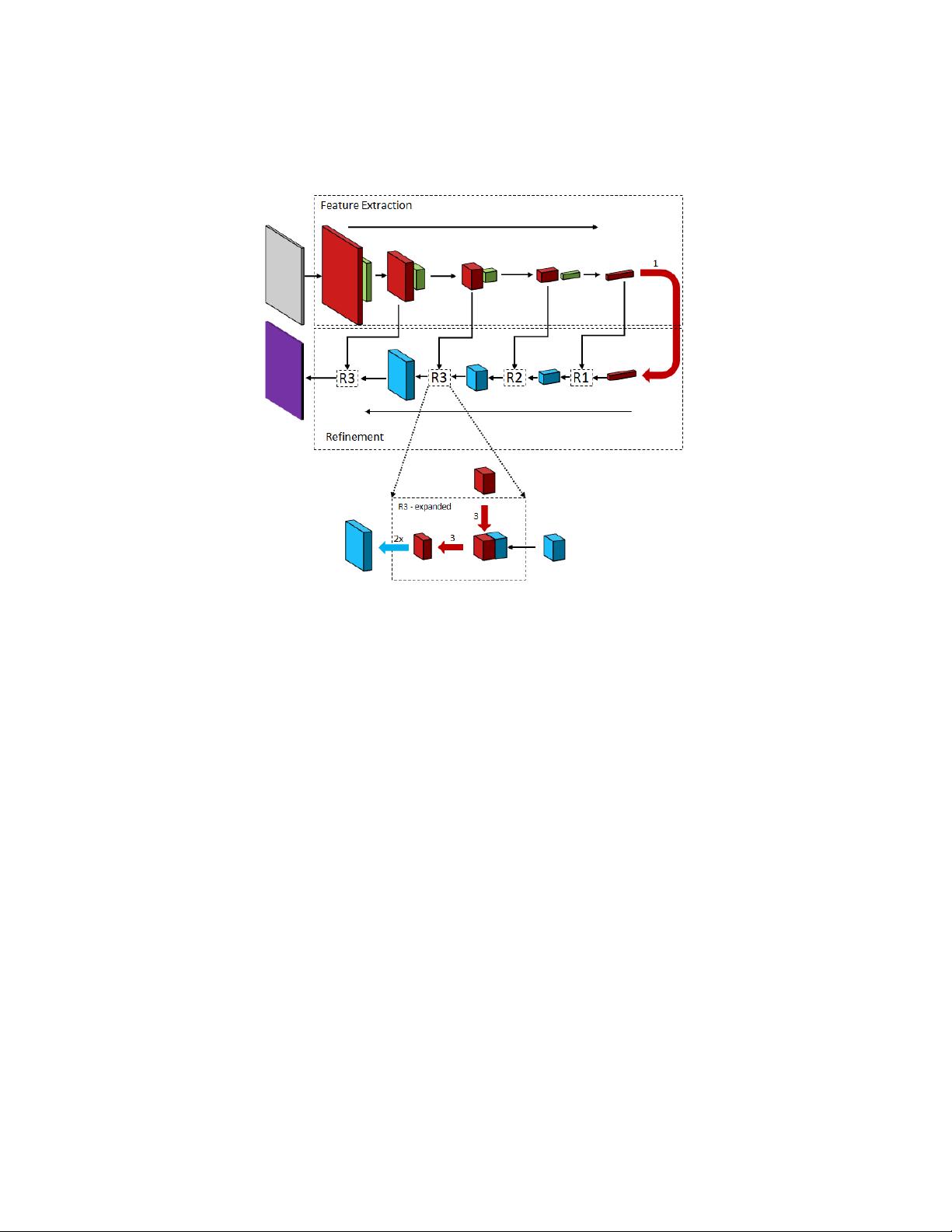
Figure 6: The Sharpmask Network
using convolutional refinements at every steps to generate high resolution masks
(Refer fig. 6). The sharpmask scored an average recall of 39.3 which beats
deepmask, which scored 36.6 on the MS COCO Segmentation Dataset.
4.1.2 Region proposal networks
Another similar wing that started developing with image segmentation was ob-
ject localization. Task such as this involved locating specific objects in images.
Expected outputs for such problems is normally a set of bounding boxes corre-
sponding to the queried objects. Though strictly stating, some of these algo-
rithms do not address image segmentation problems, however their approaches
are of relevance to this domain.
RCNN (Region-based Convolutional Neural Networks) The introduc-
tion of the CNNs raised many new questions in the domain of computer vision.
One of them primarily being whether a network like AlexNet can be extended
to detect the presence of more than one object. Region-based-CNN [70] or
more commonly known as R-CNN used selective search technique to propose
probable object regions and performed classification on the cropped window to
verify sensible localization based on the output probability distribution. Selec-
tive search technique [198, 200] analyses various aspects like texture, color, or
10


剩余57页未读,继续阅读
2023-08-12 上传
2021-01-07 上传
2011-08-16 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

苏锌雨
- 粉丝: 35
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
