字节跳动海量时序数据库字节TSDB内核与应用探索
版权申诉
92 浏览量
更新于2024-07-05
收藏 6.08MB PDF 举报
“海量时序数据库的内核探究.pdf”主要探讨了字节跳动公司内部使用的时序数据库——字节TSDB的设计与应用,重点在于其内核特性、业务支撑能力以及未来展望。
时序数据库(Time Series Database,TSDB)是一种专门用于处理和存储时间序列数据的数据库系统。时间序列数据是指按照时间顺序排列的数据,常用于监控、分析和预测,如系统指标、IoT设备数据等。字节TSDB是字节跳动为了应对大规模可观测性平台的业务挑战而设计的内部数据库。
在业务挑战方面,字节跳动面临着庞大的服务数量、国内装机量、日均服务发布和配置变更,这些都对数据存储和分析提出了极高要求。为了应对这些挑战,字节跳动构建了一个三位一体的可观测性平台,包括Metrics监控数据、Tracing调用链路数据和Logging日志数据。这些数据通过一套统一的存储进行链接和分析。
字节TSDB的核心概念包括序列(Series),由时间戳和值组成,其唯一主键是Tag的组合。数据写入支持多种SDK(Golang/Java/C++/Python)和不同数据类型(Timer/Counter/Gauge/Histogram)。查询功能兼容OpenTSDB查询语法,可以与Grafana、Bosun等工具集成,或者通过OpenAPI直接查询。
在架构上,字节TSDB展示了出色的性能,如国内每秒20亿打点的吞吐量(30秒本地聚合后)、每秒4万次查询(QPS)的处理能力,平均延迟0.3秒,99.9%的请求在2.1秒内完成。资源配比上,每5台机器可支撑1000台机器的监控,集群中的Metric数量超过2000万个,有1000多个OpenAPI应用账号,且支持2000多条预聚合规则,单指标最大可支持30个维度。
字节TSDB的内核设计中,采用了结合Cache和HDFS的冷热存储策略,优化了TagK和TagV的字典化处理,提高了存储效率。同时,它还具备高性能的查询能力,这得益于其精心设计的引擎内核。
总结和展望部分,尽管没有提供具体的内容,但可以推测,字节TSDB未来可能会继续优化内核性能,增强高并发和大数据量处理能力,提升用户体验,扩展更多集成工具,并可能在安全性、可扩展性和云原生等方面进行改进。
字节TSDB是针对大规模时序数据存储和查询需求而设计的高性能数据库,它的设计思路和实践经验对于理解时序数据库的实现和优化具有重要的参考价值。
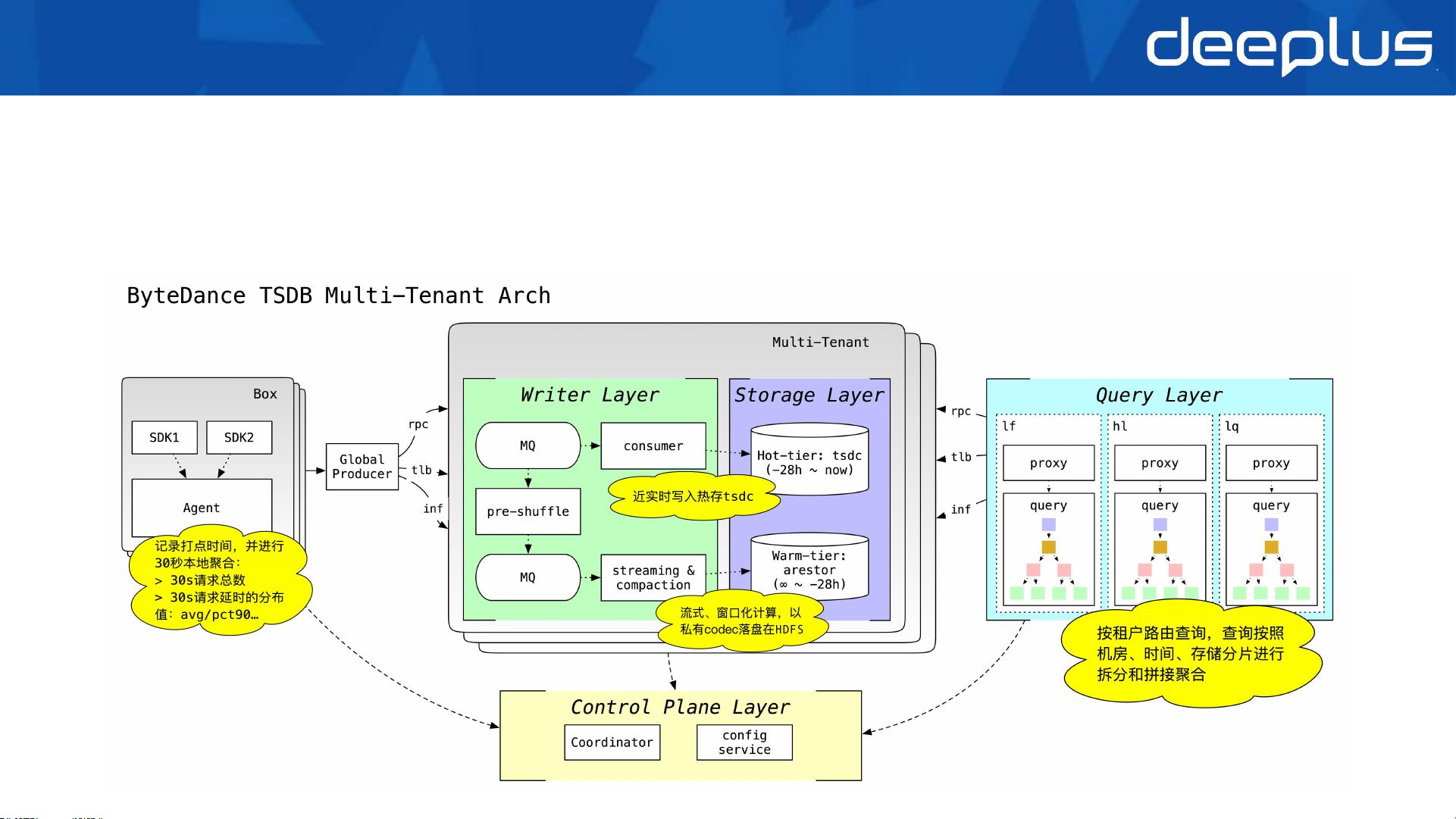
字节 TSDB 整体架构
剩余34页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-08-29 上传
2021-10-14 上传
2019-08-29 上传
2022-03-18 上传
2022-06-01 上传
2022-02-25 上传

Build前沿
- 粉丝: 807
- 资源: 2137
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
