"集成学习方法中的随机森林与adaboosting原理和应用探讨"
需积分: 0 59 浏览量
更新于2024-01-15
收藏 2.1MB PDF 举报
本文主要介绍了随机森林和adaboosting这两种集成学习方法的原理和应用。在介绍随机森林的原理时,提及了使用信息增益比作为选择特征的准则,以及信息增益和信息增益比之间的区别。此外,还介绍了随机森林中的剪枝操作。最后对随机森林的原理进行了简要总结。
随机森林是一种集成学习方法,通过结合多个弱学习器的预测结果来提高分类准确率。在训练随机森林时,首先从样本集中随机抽取一个样本集,然后构建一个决策树。重复这个过程多次,构建多棵决策树,最终通过投票的方式确定样本的分类结果。随机森林的关键在于每棵决策树的随机性,通过引入随机性来减少过拟合的风险。
在使用信息增益比作为选择特征的准则时,需要计算每个特征对分类结果的信息增益,并将其除以该特征的熵来得到信息增益比。信息增益比对属性取值数目较多的特征有所惩罚,可以避免选择属性取值数目较多的特征作为分类特征。
信息增益和信息增益比都是衡量特征对分类结果的重要性的指标,但是信息增益比对属性取值数目较多的特征有所惩罚,更适合在属性取值数目不一致的情况下使用。
在随机森林中,剪枝是一种用来减少过拟合的技术,通过剪枝可以去除一些决策树的分支,提高泛化能力。剪枝的目标是找到一个最优的剪枝点,即去除哪些分支可以使模型的准确率得到最大的提升。
总的来说,随机森林是一种强大的集成学习方法,通过引入随机性和剪枝操作,可以有效地提高分类准确率并减少过拟合的风险。
在集成学习方法中,除了随机森林还有adaboosting这种方法。adaboosting也是一种集成学习方法,通过串行训练多个弱学习器,并根据每个弱学习器的训练误差调整样本权重,最终得到一个强学习器。adaboosting在每一轮训练中都会调整样本权重,使得每个弱学习器都专注于训练误差较大的样本,从而逐步提高整体的分类准确率。
总的来说,随机森林和adaboosting都是常用的集成学习方法,它们分别通过引入随机性和调整样本权重的方式来提高分类准确率。在实际应用中,需要根据数据集的性质和要求选择合适的集成学习方法,并根据具体情况对模型进行调参和优化。
2018/8/3 机器学习面试干货精讲
http://www.360doc.com/content/18/0123/11/49770339_724393519.shtml 4/18
个体学习器之间不存在强依赖关系、可同时生成的并行化方法。代表是 Bagging 和随机森林
(Random Forest)。
2.2 Bagging
前面提到,想要集成算法获得性能的提升,个体学习器应该具有独立性。虽然 “独立” 在现
实生活中往往无法做到,但是可以设法让基学习器尽可能的有较大的差异。
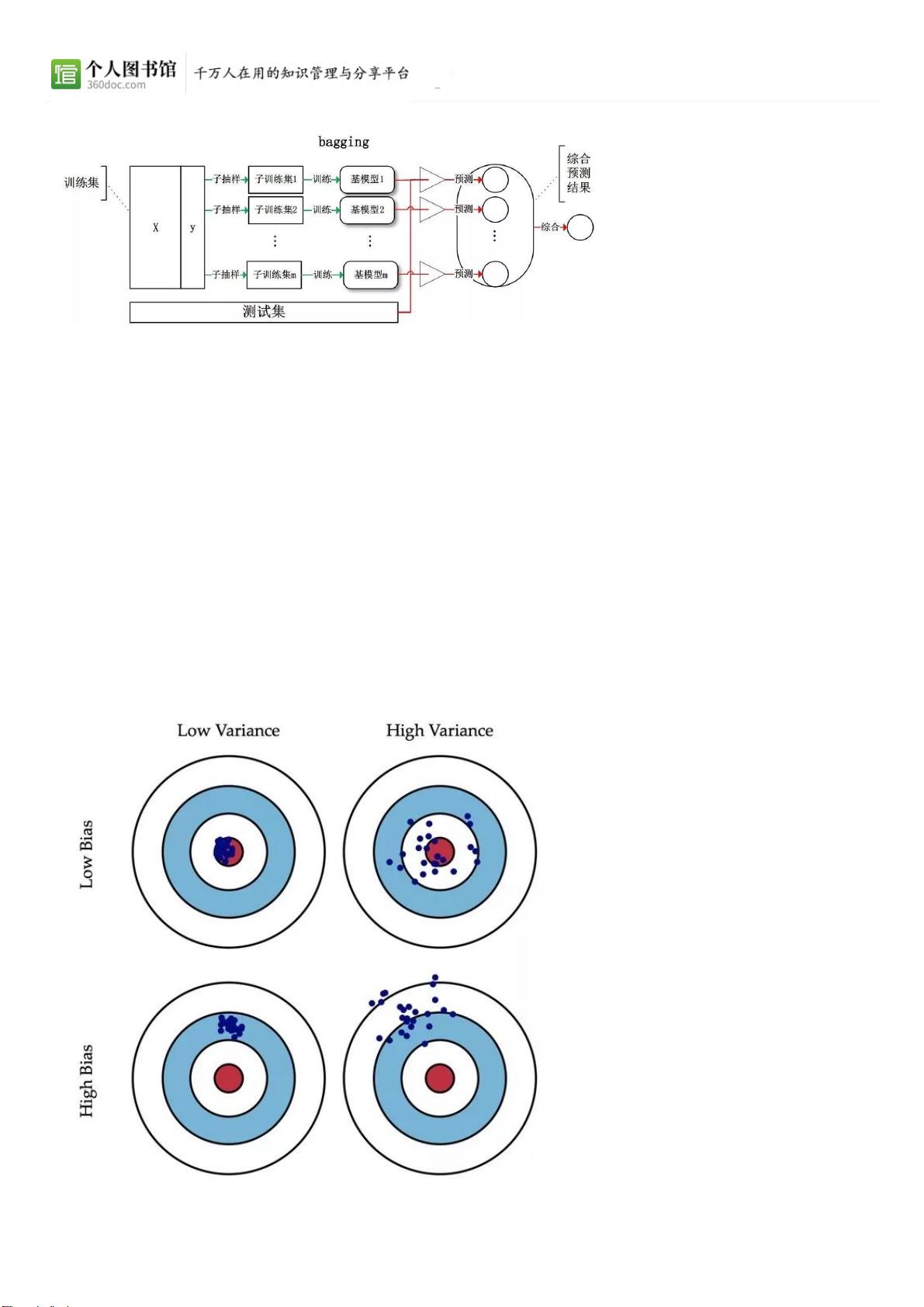
Bagging 给出的做法就是对训练集进行采样,产生出若干个不同的子集,再从每个训练子集
中训练一个基学习器。由于训练数据不同,我们的基学习器可望具有较大的差异。
Bagging 是并行式集成学习方法的代表,采样方法是自助采样法,用的是有放回的采样。初
始训练集中大约有 63.2% 的数据出现在采样集中。
Bagging 在预测输出进行结合时,对于分类问题,采用简单投票法;对于回归问题,采用简
单平均法。
Bagging 优点:
高效。Bagging 集成与直接训练基学习器的复杂度同阶;
Bagging 能不经修改的适用于多分类、回归任务;
包外估计。使用剩下的样本作为验证集进行包外估计(out-of-bag estimate)。
Bagging 主要关注降低方差。(low variance)
2.3 随机森林(Random Forest)
2.3.1 原理
留言交流
我的图书馆
搜文章 找馆友
剩余17页未读,继续阅读
2022-08-03 上传
2023-06-13 上传
2023-11-07 上传
2023-05-22 上传
2024-04-25 上传
2023-09-03 上传
2024-03-02 上传

洪蛋蛋
- 粉丝: 28
- 资源: 334
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机人脸表情动画技术发展综述
- 关系数据库的关键字搜索技术综述:模型、架构与未来趋势
- 迭代自适应逆滤波在语音情感识别中的应用
- 概念知识树在旅游领域智能分析中的应用
- 构建is-a层次与OWL本体集成:理论与算法
- 基于语义元的相似度计算方法研究:改进与有效性验证
- 网格梯度多密度聚类算法:去噪与高效聚类
- 网格服务工作流动态调度算法PGSWA研究
- 突发事件连锁反应网络模型与应急预警分析
- BA网络上的病毒营销与网站推广仿真研究
- 离散HSMM故障预测模型:有效提升系统状态预测
- 煤矿安全评价:信息融合与可拓理论的应用
- 多维度Petri网工作流模型MD_WFN:统一建模与应用研究
- 面向过程追踪的知识安全描述方法
- 基于收益的软件过程资源调度优化策略
- 多核环境下基于数据流Java的Web服务器优化实现提升性能
