CUDA程序优化策略:存储与数据传输优化
需积分: 35 103 浏览量
更新于2024-07-17
收藏 2.69MB PPT 举报
CUDA程序优化是提高GPU性能的关键环节,尤其是在处理大规模并行计算任务时。本文主要关注存储优化策略,特别是如何有效地管理CPU-GPU之间的数据传输,以减少延迟并最大化GPU资源的利用率。
1. **存储优化**
- **CPU-GPU数据传输**:由于Host(CPU)和Device(GPU)之间的带宽差距显著,如PCIe x16 Gen2的8GB/s与C2050的156GB/s和515 GB/s(inst/s),减少Host到device的数据传输至关重要。尽可能减少不必要的数据交换可以避免性能瓶颈。
- **数据在GPU上的处理**:对于重复计算,直接在GPU上分配、操作和释放内存可以节省CPU时间,提高整体性能。将CPU计算移到GPU可能需要考虑数据传输的影响。
2. **数据传输策略**
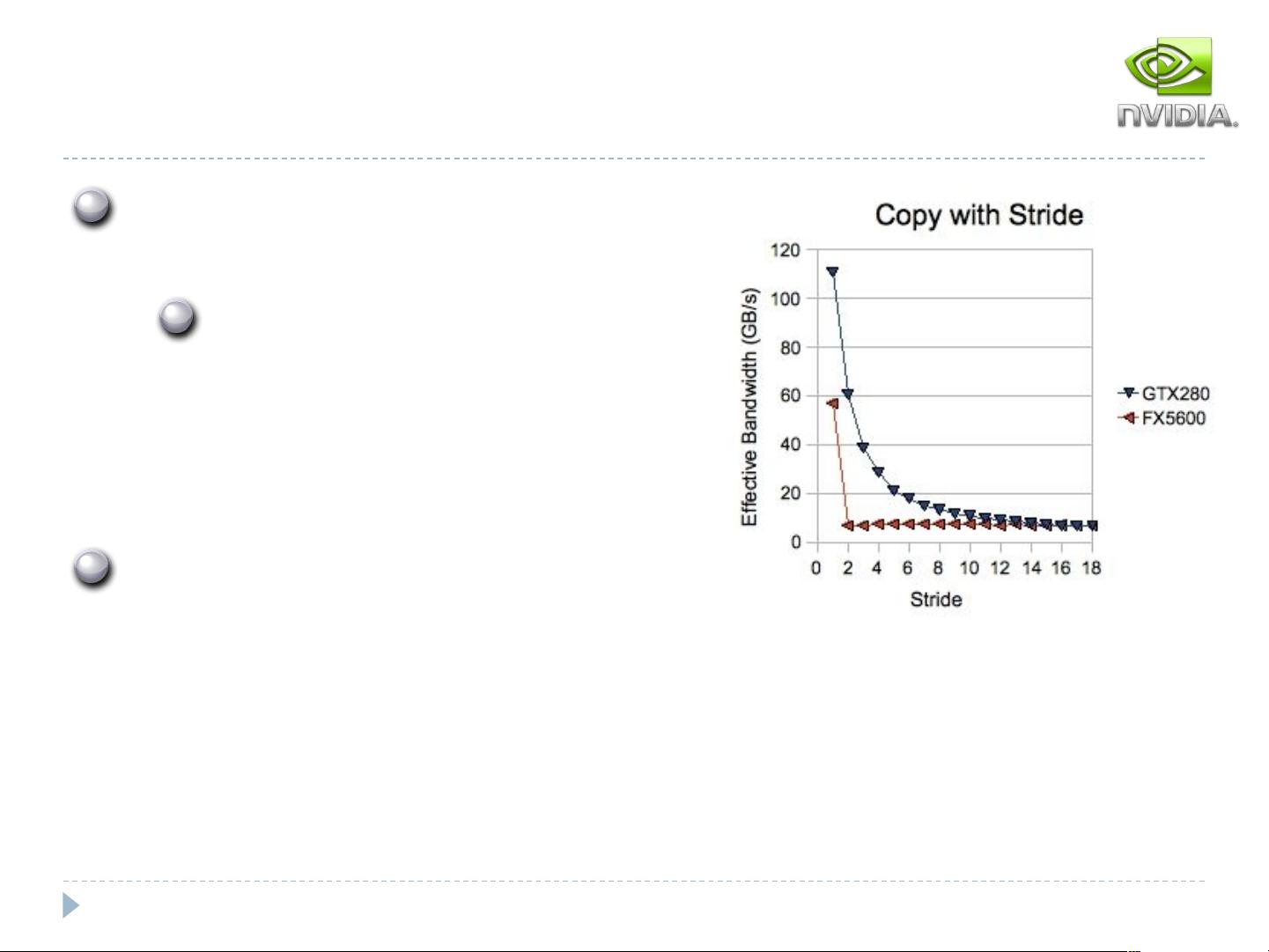
- **组团传输**:大块数据传输比小块更有效率,比如当数据小于80KB时,小块传输可能会受到10微秒延迟的显著影响。因此,合理安排数据大小有利于优化性能。
- **内存传输与计算时间重叠**:通过内存层次结构(例如双缓存系统),可以实现计算和数据传输的同时进行,从而利用好GPU的并发特性。
3. **缓存策略**
- **Coalescing合并**:Fermi架构中的全局内存默认缓存在一级缓存L1中,但可以通过nvcc指令“-Xptxas –dlcm=cg”绕过L1,只缓存到二级缓存L2。合并访问(Transaction-level Coalescing)意味着如果一个 warp 的读写请求落在L1缓存行内,只需要一次传输,显著降低延迟。
- **内存合并**:针对矩阵等数据结构,行优先的存储方式通常对线程的访存模式有利,因为这样可以利用缓存的合并,减少不连续内存访问带来的额外传输。
4. **硬件依赖性**
- **计算能力依赖**:不同的CUDA计算能力(如1.0和1.1)有不同的内存访问限制。例如,在1.0和1.1中,半warps(16个线程)的浮点32位数据访问可能需要满足特定的合并条件,以便减少传输次数。
CUDA程序优化不仅涉及到代码级别的调整,还涵盖了对硬件特性的理解与利用,如缓存机制、数据传输策略以及计算能力差异。通过这些优化措施,开发者能够显著提升CUDA应用程序的性能,使其更好地适应GPU架构的并行计算需求。

11
__global__ void strideCopy(float *odata, float *idata,
int stride)
{
int xid = (blockIdx.x*blockDim.x +
threadIdx.x)*stride;
odata[xid] = idata[xid];
}
剩余63页未读,继续阅读
2021-01-20 上传
2017-12-17 上传
2020-06-06 上传
2023-09-12 上传
2023-06-12 上传
2024-05-30 上传
2024-05-16 上传
2023-05-30 上传
2023-09-15 上传

mutourenzhang
- 粉丝: 9
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Lombok 快速入门与注解详解
- SpringSecurity实战:声明式安全控制框架解析
- XML基础教程:从数据传输到存储解析
- Matlab实现图像空间平移与镜像变换示例
- Python流程控制与运算符详解
- Python基础:类型转换与循环语句
- 辰科CD-6024-4控制器说明书:LED亮度调节与触发功能解析
- AE particular插件全面解析:英汉对照与关键参数
- Shell脚本实践:创建tar包、字符串累加与简易运算器
- TMS320F28335:浮点处理器与ADC详解
- 互联网基础与结构解析:从ARPANET到多层次ISP
- Redhat系统中构建与Windows共享的Samba服务器实战
- microPython编程指南:从入门到实践
- 数据结构实验:顺序构建并遍历链表
- NVIDIA TX2系统安装与恢复指南
- C语言实现贪吃蛇游戏基础代码
