详解EM算法:理论与实例解析
期望最大化算法(EM)是一种常用的无监督或半监督学习方法,特别适用于处理带有隐变量的数据集,比如在混合高斯分布、贝叶斯网络和因子分析等概率模型中。EM算法的核心思想是通过迭代的方式,交替优化观测数据的参数估计和隐变量的后验分布,即使在数据中存在缺失值或部分观察时也能进行有效的参数估计。
1. 基础知识准备:
- **数学期望**:是随机变量的平均值,它表示一个随机变量取所有可能值的加权平均,对于EM算法来说,这是计算参数估计的重要工具。
- **极大似然估计**:是根据给定观测数据寻找模型参数的一种方法,目标是使数据的似然函数最大化的估计。在EM算法中,极大似然估计用于初始化和每次迭代后更新模型参数。
2. 凸函数与凹函数:在优化理论中,凸函数具有重要的性质,它的图形总是向上凸起,而凹函数则是向下凹陷。理解这些概念有助于理解EM算法中的梯度上升过程,因为优化目标通常是凸函数,从而保证了全局最优解的存在。
3. **詹森不等式**:这个不等式是衡量偏导数与原函数之间关系的一个工具,对于证明EM算法的收敛性和性能有着关键作用。在算法迭代过程中,利用詹森不等式可以确保每个步骤都在朝着增加总体似然的方向推进。
1.2 期望最大化算法理论推导:
- **三枚硬币问题**:这是一个直观的示例,用于解释EM算法的基本运作。设想有三枚硬币,其中两枚公平,一枚偏斜。目标是估计每枚硬币出现正面的概率。在EM算法中,隐变量可能是硬币的种类,我们先用极大似然估计初始参数,然后通过迭代过程估计隐藏的硬币类型分布,同时更新各硬币的抛掷概率。这个过程直到达到局部最优或者满足停止条件。
通过三枚硬币问题的推导,我们可以看到EM算法的主要步骤:(1)初始化观测数据的似然函数;(2)用当前的参数估计隐变量的分布;(3)基于新的隐变量分布更新观测数据的参数;(4)重复步骤2和3,直至收敛。每一步都遵循数学期望和极大似然原则,确保模型参数逐渐接近真实分布。
总结来说,期望最大化算法是一种强大的工具,尤其适用于复杂模型中的参数估计。理解其背后的数学原理和关键概念如数学期望、极大似然、凸函数等,能帮助我们更深入地掌握这一方法,并在实际问题中有效地应用。同时,通过具体案例如三枚硬币问题,我们能看到算法的具体操作流程及其在优化过程中的应用。
MAGE
–4/37– 第 1 章 期望最大化算法
4. 求解似然方程
对上述似然方程求解可以得到 θ 的极大估计量
ˆ
θ,极大估计量
ˆ
θ 是关于样本集 D
的函数 d(D),记作:
ˆ
θ = d(D)
= d(x
1
, x
2
, ··· , x
n
)
(1.9)
因此,
ˆ
θ 称作极大似然函数的估计值。
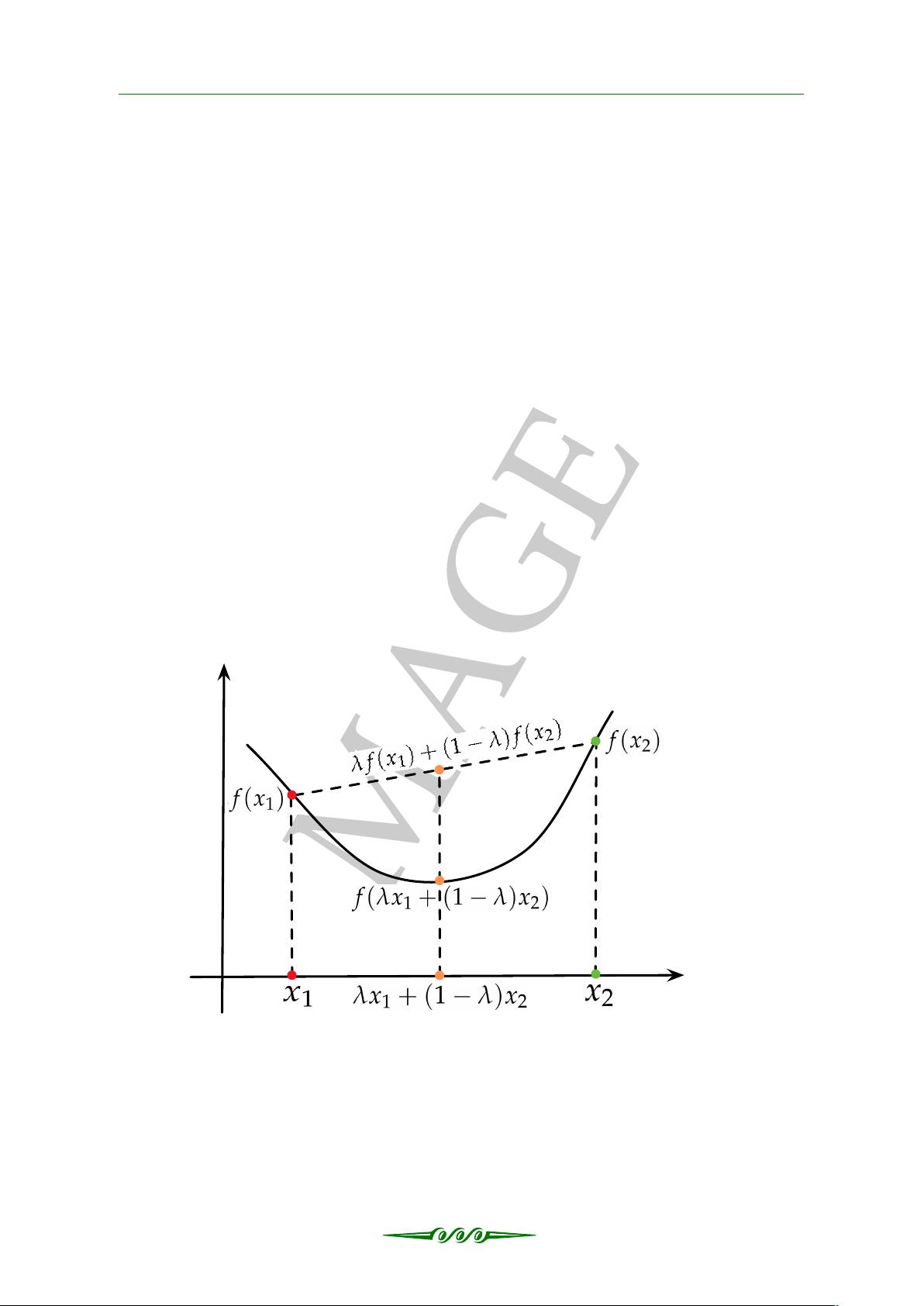
1.1.3 凸函数与凹函数
1. 凸函数(Convex Function)
设函数 f (x) 在区间 I 上连续,且对 ∀x
1
, x
2
∈ I 和 ∀λ ∈ (0, 1) 有:
f (λx
1
+ (1 −λ)x
2
) ≤ λ f (x
1
) + (1 − λ) f (x
2
) (1.10)
则称 f (x) 为凸函数,若不等号严格成立(即 > 号成立),则 f (x) 在 I 上是严格
凸函数。如图1.1所示。
x
y
图 1.1: 凸函数
注: 直观上来说,在函数 f (x) 的图象上取任意两点,如果在这两点之间的函数
图象总在这两点连接线段的下方,那么这个函数就是凸函数。
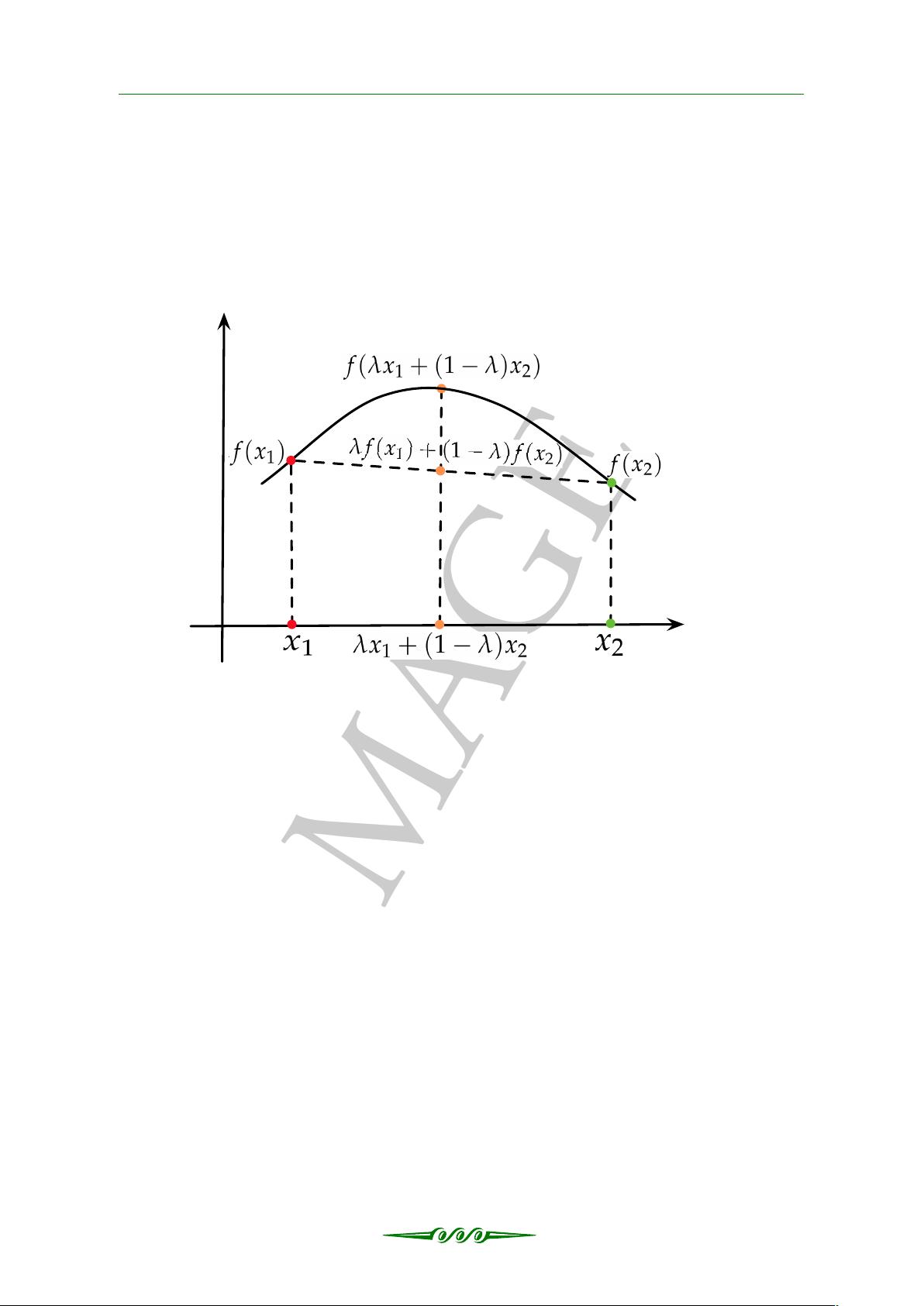
2. 凹函数(Concave Function)
剩余40页未读,继续阅读
115 浏览量
171 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
143 浏览量

瞭望清晨
- 粉丝: 86
 我的内容管理
展开
我的内容管理
展开








最新资源
- EclipseEE平台下Struts1 Web程序的入门调试指南
- 复古n-gon渲染器:HTML5画布上的软件3D艺术
- Java专业课程源代码压缩包文件名详解
- 简易文档管理系统源码:适用于小型企业高效管理
- Flacfish语言学习资源:FLA3D命令集锦解读
- 电子时钟设计原理与单片机应用毕业论文研究
- MyBatisCodeHelperPro 2.8.2 功能升级与优化
- 实现struts2+spring3+mybatis3集成登录功能
- 家庭理财管理系统:SQL与VB的高效信息管理
- 深入探索Windows PowerShell系列课程:技巧、应用与实战
- Android平台的AutoTextView自动化文本显示控件开发指南
- SSM框架下的日志系统开发实践
- 郑庆华JSP课程设计:固定资产管理系统实现
- Ansys中文高级分析技术指南
- 开源RISC处理器OR1200 Verilog源码发布
- Java程序员的LeetCode游戏代码实战
