有赞实时计算演进:从Storm到Flink的效率提升实践
版权申诉
173 浏览量
更新于2024-08-08
收藏 395KB PDF 举报
"有赞公司从使用Storm到转用Flink的实时计算发展历程及效率提升实践"
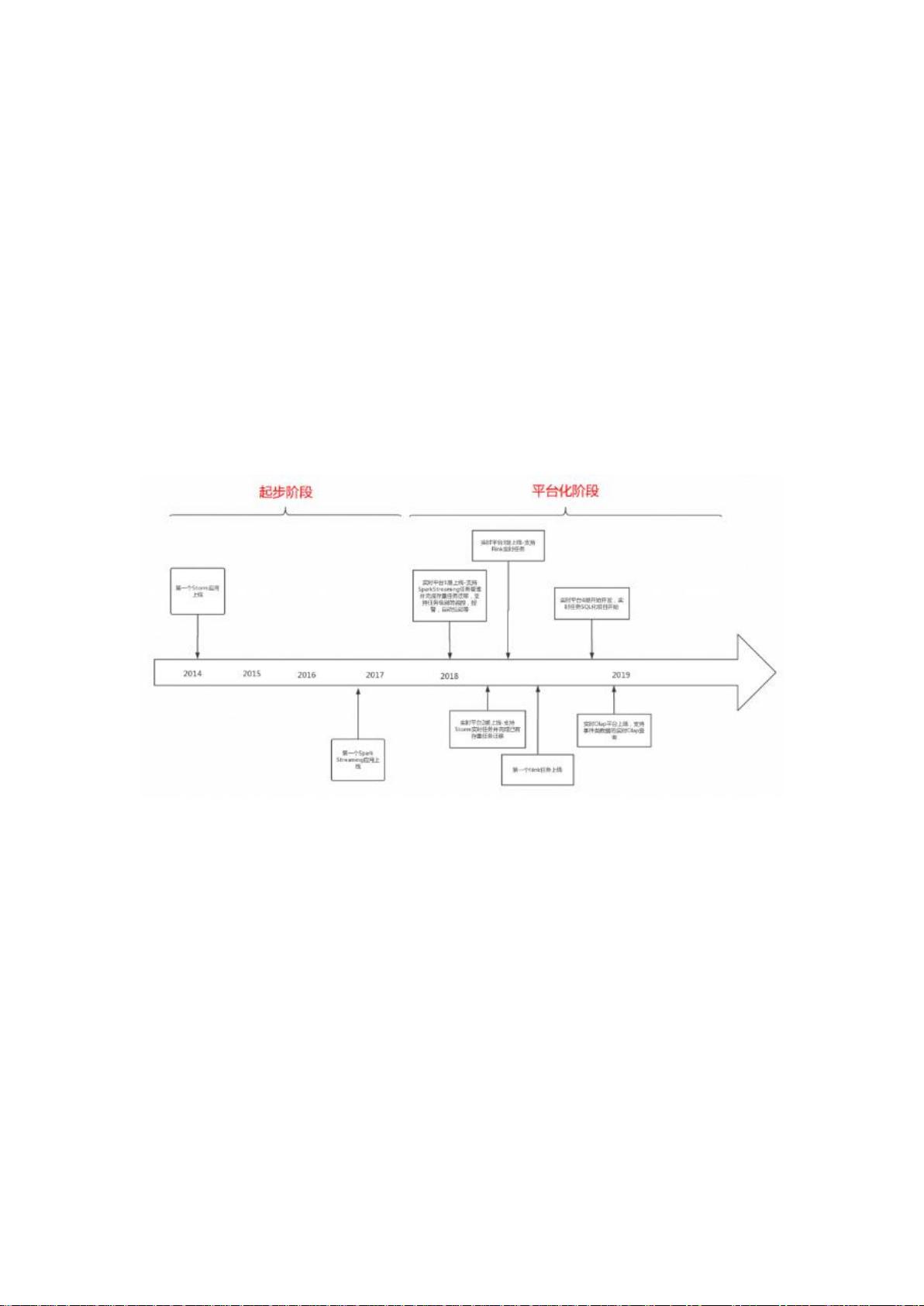
在有赞公司的实时数仓实践中,他们经历了从早期的Storm到JStorm,再到SparkStreaming,最后采用Flink的实时计算技术演进。这个过程中,实时计算技术在有赞的发展可以分为两个主要阶段:起步阶段和平台化阶段。
2.1 起步阶段
在这个阶段,实时计算系统缺乏整体规划和管理工具,任务提交依赖于直接登录服务器进行命令行操作,这对可用性和稳定性提出了挑战。尽管如此,这个阶段为有赞积累了丰富的实时计算场景。2014年,Storm首次被引入,用于处理MySQL binlog事件,实现业务数据的实时统计和更新。随着时间推移,Storm支持了越来越多的业务,但其在高吞吐量场景下的表现不尽人意,延迟问题逐渐暴露。
2.1.2 引入SparkStreaming
为解决Storm的性能瓶颈,2016年末,有赞开始尝试使用SparkStreaming。由于有赞在离线计算领域已经积累了大量Spark任务的经验,SparkStreaming成为了自然而然的选择。随着业务日志系统和埋点日志的实时应用接入,SparkStreaming逐渐在多个业务场景中得到应用。
2.2 平台化阶段
随着实时计算需求的增长和场景的复杂化,有赞进入了平台化阶段。在这个阶段,他们开始构建统一的实时计算平台,提供任务管理、监控和报警工具,以提高服务的可用性和稳定性。在此期间,Flink作为新兴的流处理引擎,以其强大的性能和低延迟特性,逐渐吸引了有赞的注意。
Flink的出现解决了Storm在高吞吐量场景下的性能问题,并且提供了更强大的状态管理和窗口功能,使得实时计算能够更好地服务于交易数据大屏、商品实时统计分析、日志平台、调用链和风控等多个业务场景。有赞通过引入Flink,不仅提升了实时计算的效率,还简化了任务运维,实现了实时计算平台的标准化和规范化。
总结起来,有赞的实时计算实践展示了实时数仓技术如何从初期的单一工具发展到多元化选择,以及如何通过不断迭代和优化,提升实时数据处理的效率和质量。从Storm到Flink的转变,反映了实时计算领域的技术进步和业务需求的变化,同时也体现了有赞在技术创新和应用实践上的敏锐度。
2022精品解决方案/精品实践方案/精选研究报告
导读:有赞是一个商家服务公司,提供全行业全场景的电商解决方案。在有赞,大
量的业务场景依赖对实时数据的处理,作为一类基础技术组件,服务着有赞内部几
十个业务产品,几百个实时计算任务,其中包括交易数据大屏,商品实时统计分
析,日志平台,调用链,风控等多个业务场景,本文将介绍有赞实时计算当前的发
展历程和当前的实时计算技术架构。
实时计算在有赞发展
从技术栈的角度,我们的选择和大多数互联网公司一致,从早期的 Storm,到
JStorm, Spark Streaming 和最近兴起的 Flink。从发展阶段来说,主要经历了
两个阶段,起步阶段和平台化阶段;下面将按照下图中的时间线,介绍实时计算在
有赞的发展历程。
2.1 起步阶段
这里的的起步阶段的基本特征是,缺少整体的实时计算规划,缺乏平台化任务管
理,监控,报警工具,用户提交任务直接通过登录 AG 服务器使用命令行命令提
交任务到线上集群,很难满足用户对可用性的要求。但是,在起步阶段里积累了内
部大量的实时计算场景。
2.1.1 Storm 登场
2014 年初,第一个 Storm 应用在有赞内部开始使用,最初的场景是把实时事件
的统计从业务逻辑中解耦出来,Storm 应用通过监听 MySQL 的 binlog 更新事
件做实时计算,然后将结果更新到 MySQL 或者 Redis 缓存上,供在线系统使
用。类似的场景得到了业务开发的认可,逐渐开始支撑起大量的业务场景。
下载后可阅读完整内容,剩余6页未读,立即下载
2024-04-26 上传
2023-06-09 上传
2023-05-01 上传
2023-09-09 上传
2023-06-13 上传
2023-06-13 上传
2023-06-09 上传
2023-11-19 上传
2023-11-15 上传

安全方案
- 粉丝: 2159
- 资源: 3863
 我的内容管理
展开
我的内容管理
展开







最新资源
- Hadoop生态系统与MapReduce详解
- MDS系列三相整流桥模块技术规格与特性
- MFC编程:指针与句柄获取全面解析
- LM06:多模4G高速数据模块,支持GSM至TD-LTE
- 使用Gradle与Nexus构建私有仓库
- JAVA编程规范指南:命名规则与文件样式
- EMC VNX5500 存储系统日常维护指南
- 大数据驱动的互联网用户体验深度管理策略
- 改进型Booth算法:32位浮点阵列乘法器的高速设计与算法比较
- H3CNE网络认证重点知识整理
- Linux环境下MongoDB的详细安装教程
- 压缩文法的等价变换与多余规则删除
- BRMS入门指南:JBOSS安装与基础操作详解
- Win7环境下Android开发环境配置全攻略
- SHT10 C语言程序与LCD1602显示实例及精度校准
- 反垃圾邮件技术:现状与前景
