




思科系统会议讨论:以太网标准的制定与时间线提案
PDF格式 | 810KB |
更新于2025-03-20
| 94 浏览量 | 举报
从提供的文件内容来看,文档似乎是关于Cisco Systems, Inc. 内部的一个名为 "kochuparambil_3ck_01_1118" 的讨论或会议记录。文档中讨论了IEEE 802.3ck标准的进度和时间线,以及一些与此相关的内部审核流程。以下是根据提供的内容摘要的一些知识点:
1. IEEE 802.3ck 标准:这是一个特定的技术标准,可能涉及网络通信或以太网标准。IEEE 802.3系列标准主要规定了以太网局域网(LAN)的技术细节。
2. 讨论和时间线提案:文档提到了回顾7月份的讨论,以及在不同时间点(比如会议、工作组投票、赞助商投票、非正式审查等)的提案。这表明了标准制定过程中不同阶段的讨论和决策要点。
3. 审核流程:
- 采纳基线(Adopt Baselines):这部分讨论可能涉及确定标准的基线版本,这是制定标准的基础。
- 任务组审查(Task Force Review):指的是由专门的任务小组对标准草案进行审查的步骤。
- 工作组投票(Working Group Ballot):工作组成员对草案进行投票,这可能是为了获得团队的共识或批准。
- 赞助商投票(Sponsor Ballot):在获得工作组内部支持后,标准草案将提交给赞助商进行投票,这通常是为了获得更高级别的批准。
- 非正式审查(& Informal Review):在正式投票前,可能会有一个非正式的审查过程,允许所有利益相关者对草案提出意见和建议。
4. 时间线提议:文档中包含了一个时间线,展示了从7月开始的不同时间点的会议安排。例如,“Adopt Baselines (4 mtg)”可能表示采纳基线的工作会在四次会议后完成。
5. Cisco Systems, Inc.:这家公司是全球领先的网络技术和解决方案供应商,参与标准化组织如IEEE的活动是其正常业务流程的一部分。
基于这些信息,我们可以构建出一个关于Cisco参与IEEE 802.3ck标准制定过程的知识框架。文档内容虽然简短,但涉及了标准化过程中的关键环节,从初步讨论到提案的制定,再到审查和投票阶段,每一步都是确保技术标准高质量完成的重要组成部分。通过这样的流程,利益相关者可以对标准进行充分的讨论和审查,最终形成广泛接受的技术规范。对于IT行业来说,这样的标准化工作是确保不同设备和系统之间互操作性和兼容性的基础。
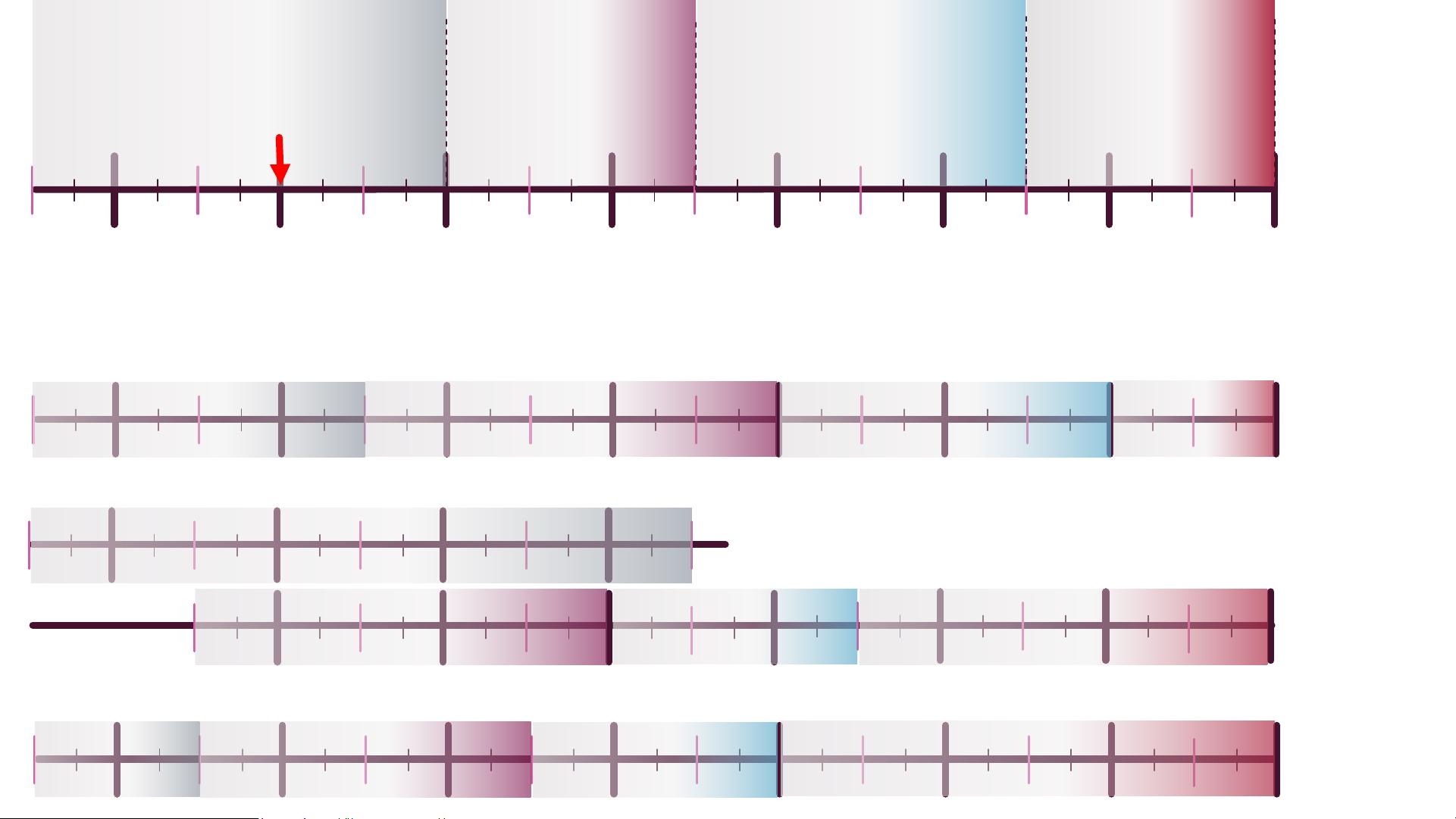
July
November
March
July
November
March
July
November
Adopt Baselines
& Informal Review
Working Group Ballot Sponsor Ballot
WE ARE
HERE
May
September
January
May
September
January
May
September
Task Force Review
Adopt Baselines (4 mtg)
Task Force Review
Working Group Ballot
Sponsor Ballot
Adopt Baselines (2
mtg)
Task Force Review
.3cd
.3bj
.3bs
Task Force Review
July’s
Timeline
Proposal
Sponsor Ballot
Working Group Ballot
Working Group Ballot
Sponsor Ballot
Adopt Baselines (8 mtg)
下载后可阅读完整内容,剩余13页未读,立即下载
相关推荐


123 浏览量
214 浏览量
101 浏览量
204 浏览量
145 浏览量
236 浏览量

DavidWangYang
- 粉丝: 4536
 我的内容管理
展开
我的内容管理
展开







最新资源
- React App入门教程与TypeScript项目结构
- C语言实战105例:经典源代码深入解析
- HD Tune Pro 4.60硬盘性能测试软件评测
- 深入理解Objective-C中的Retain和Assign属性
- 支持64位iOS平台的ZBar SDK更新
- OpenGL源码示例:纹理映射与旋转立方体交互
- Antibiotech:字体设计的新纪元
- 华为AP2050DN-S FAT版本详细解读
- 优化React组件结构:派对筹划者应用程序
- Java环境下的MQ消息发送源代码示例
- 11套精选单页网站源码及订单系统模板发布
- django_puppeteer_pdf包下载 - PyPI官方资源
- C#打造功能强大的音乐播放器应用
- 超市商品管理系统:易用性与实用功能详解
- COMET试用培训库:Lyrid-Training介绍
- Alpine7558s字体:独特的设计与应用






















