TalkingData的Spark实践:从Hadoop到Spark的转型之路
87 浏览量
更新于2024-08-28
收藏 415KB PDF 举报
"这篇文章主要讲述了 TalkingData 在大数据平台建设中从使用Hadoop过渡到采用Spark的架构实践过程,以及Spark在国内大数据领域的普及和发展情况。文章提及Spark的核心特性,如内存计算的弹性分布式数据集(RDD)、对机器学习的支持以及与Hadoop YARN的集成,展现了Spark在实时和离线处理上的优势。此外,文章还讨论了TalkingData如何基于Hadoop YARN和Spark构建移动大数据平台,以及在面对业务需求和数据增长时,选择Spark而非Impala的原因。"
在大数据处理领域,Hadoop 作为早期的重要框架,以其分布式存储(HDFS)和MapReduce计算模型为业界提供了强大的数据处理能力。然而,随着实时分析和快速迭代的需求增加,Hadoop 的效率显得不足。Spark 的出现,以其内存计算的能力和对多种工作负载的支持,弥补了Hadoop在速度和灵活性上的短板。
Spark的核心组件包括Spark Core、Spark Streaming、Spark SQL和MLlib。Spark Core 提供了基础的并行计算框架,支持任务调度和数据存储管理;Spark Streaming 则用于处理实时流数据,提供低延迟的数据处理;Spark SQL 结合了SQL查询和DataFrame API,简化了结构化数据的处理;MLlib 是Spark的机器学习库,包含了多种机器学习算法,支持数据科学家进行预测和模式识别。
在 TalkingData 的实践中,他们发现Spark的内存计算模型能够显著提高数据分析的速度,尤其是在处理大量移动设备数据时,这比传统的Hadoop MapReduce更加高效。此外,Spark与Hadoop YARN的兼容性使得在现有Hadoop集群上无缝集成Spark成为可能,这减少了平台迁移的复杂性和成本。
对比Impala,虽然Impala优化了Hive的查询性能,但Spark的目标是构建一个全面的大数据处理生态系统,包括批处理、交互式查询和流处理。这种统一的处理模型对于 TalkingData 这样的公司来说,更适合其不断变化的业务需求和数据增长的挑战。
通过建立基于Hadoop YARN和Spark的移动大数据平台,TalkingData能够实现实时数据汇聚、分析和挖掘,从而提升数据价值的发现和业务洞察力。这样的平台不仅加速了数据处理流程,也增强了对瞬息万变的移动互联网市场的响应能力。
总结来说,从Hadoop到Spark的转变反映了大数据技术的发展趋势,即追求更快、更灵活的数据处理解决方案。Spark的出现,特别是在 TalkingData 的实践中,证明了它在处理大规模移动数据时的优势,以及在构建高效、可扩展的大数据平台中的重要角色。
从从Hadoop到到Spark的架构实践的架构实践
本文则主要介绍TalkingData在大数据平台建设过程中,逐渐引入Spark,并且以Hadoop YARN和Spark为基础来构建移动大
数据平台的过程。
当下,Spark已经在国内得到了广泛的认可和支持:2014年,Spark Summit China在北京召开,场面火爆;同年,Spark
Meetup在北京、上海、深圳和杭州四个城市举办,其中仅北京就成功举办了5次,内容更涵盖Spark Core、Spark
Streaming、Spark MLlib、Spark SQL等众多领域。而作为较早关注和引入Spark的移动互联网大数据综合服务公
司,TalkingData也积极地参与到国内Spark社区的各种活动,并多次在Meetup中分享公司的Spark使用经验。本文则主要介绍
TalkingData在大数据平台建设过程中,逐渐引入Spark,并且以Hadoop YARN和Spark为基础来构建移动大数据平台的过
程。
初识Spark
作为一家在移动互联网大数据领域创业的公司,时刻关注大数据技术领域的发展和进步是公司技术团队必做的功课。而在整理
Strata 2013公开的讲义时,一篇主题为《An Introduction on the Berkeley Data Analytics Stack_BDAS_Featuring
Spark,Spark Streaming,and Shark》的教程引起了整个技术团队的关注和讨论,其中Spark基于内存的RDD模型、对机器学习
算法的支持、整个技术栈中实时处理和离线处理的统一模型以及Shark都让人眼前一亮。同时期我们关注的还有Impala,但对
比Spark,Impala可以理解为对Hive的升级,而Spark则尝试围绕RDD建立一个用于大数据处理的生态系统。对于一家数据量
高速增长,业务又是以大数据处理为核心并且在不断变化的创业公司而言,后者无疑更值得进一步关注和研究。
Spark初探
2013年中期,随着业务高速发展,越来越多的移动设备侧数据被各个不同的业务平台收集。那么这些数据除了提供不同业务
所需要的业务指标,是否还蕴藏着更多的价值?为了更好地挖掘数据潜在价值,我们决定建造自己的数据中心,将各业务平台
的数据汇集到一起,对覆盖设备的相关数据进行加工、分析和挖掘,从而探索数据的价值。初期数据中心主要功能设置如下所
示:
1. 跨市场聚合的安卓应用排名;
2. 基于用户兴趣的应用推荐。
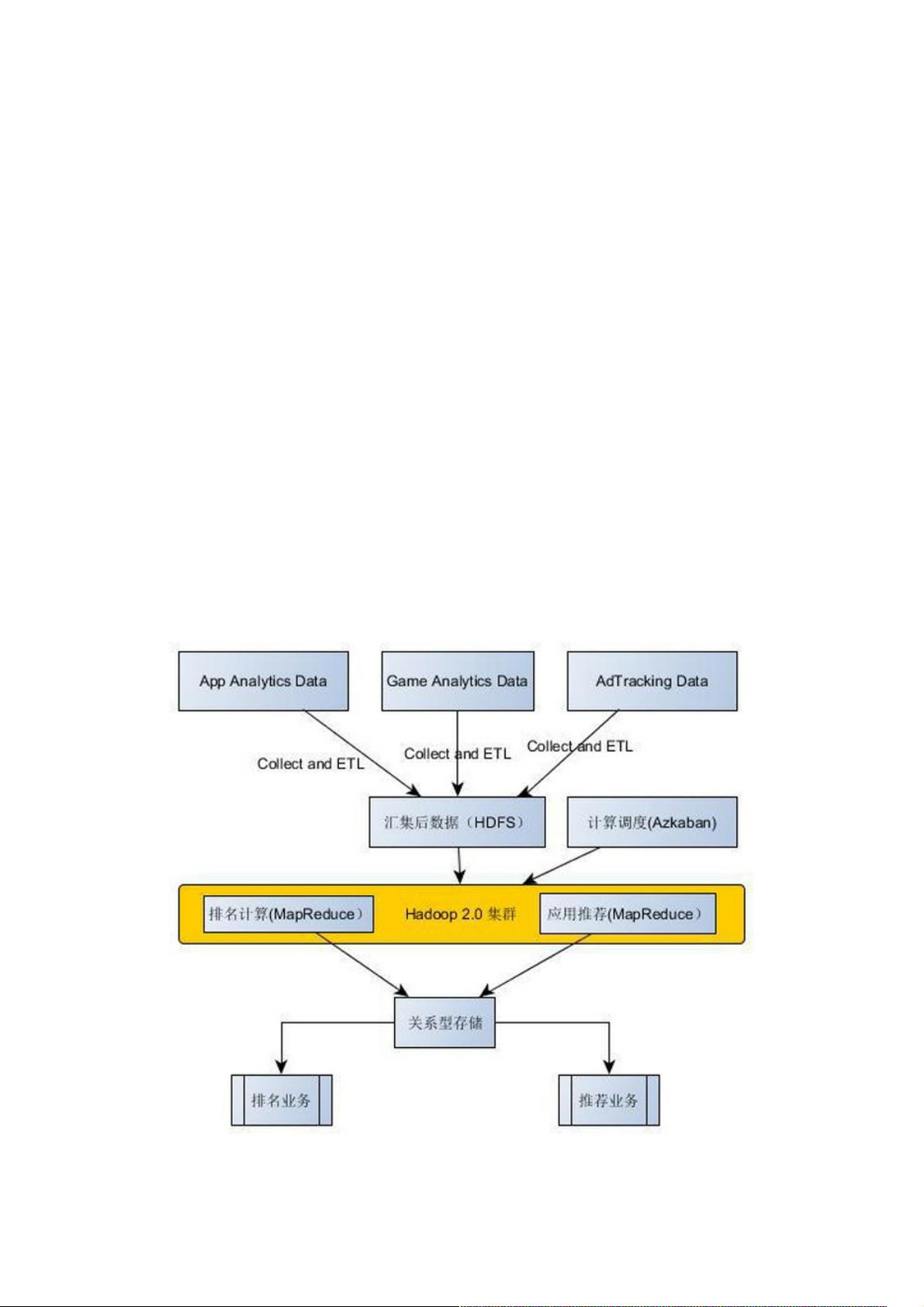
基于当时的技术掌握程度和功能需求,数据中心所采用的技术架构如图1。
图1 基于Hadoop 2.0的数据中心技术架构
整个系统构建基于Hadoop 2.0(Cloudera CDH4.3),采用了最原始的大数据计算架构。通过日志汇集程序,将不同业务平
台的日志汇集到数据中心,并通过ETL将数据进行格式化处理,储存到HDFS。其中,排名和推荐算法的实现都采用了
MapReduce,系统中只存在离线批量计算,并通过基于Azkaban的调度系统进行离线任务的调度。
下载后可阅读完整内容,剩余4页未读,立即下载
166 浏览量
2022-06-22 上传
2022-01-10 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38673812
- 粉丝: 4
- 资源: 904
 我的内容管理
展开
我的内容管理
展开







最新资源
- OptiX传输试题与SDH基础知识
- C++Builder函数详解与应用
- Linux shell (bash) 文件与字符串比较运算符详解
- Adam Gawne-Cain解读英文版WKT格式与常见投影标准
- dos命令详解:基础操作与网络测试必备
- Windows 蓝屏代码解析与处理指南
- PSoC CY8C24533在电动自行车控制器设计中的应用
- PHP整合FCKeditor网页编辑器教程
- Java Swing计算器源码示例:初学者入门教程
- Eclipse平台上的可视化开发:使用VEP与SWT
- 软件工程CASE工具实践指南
- AIX LVM详解:网络存储架构与管理
- 递归算法解析:文件系统、XML与树图
- 使用Struts2与MySQL构建Web登录验证教程
- PHP5 CLI模式:用PHP编写Shell脚本教程
- MyBatis与Spring完美整合:1.0.0-RC3详解
