TensorFlow分布式执行原理详解:构建与优化过程
148 浏览量
更新于2024-08-28
收藏 321KB PDF 举报
TensorFlow分布式原理深入解析
TensorFlow是一个强大的深度学习框架,其核心概念是计算图,它允许开发者以静态图形的形式描述计算逻辑。分布式版本的TensorFlow旨在提高模型训练的效率和可扩展性,尤其是在大规模数据和多台机器上。本文主要围绕以下几个方面来理解TensorFlow的分布式原理:
1. **单机与分布式版本对比**:
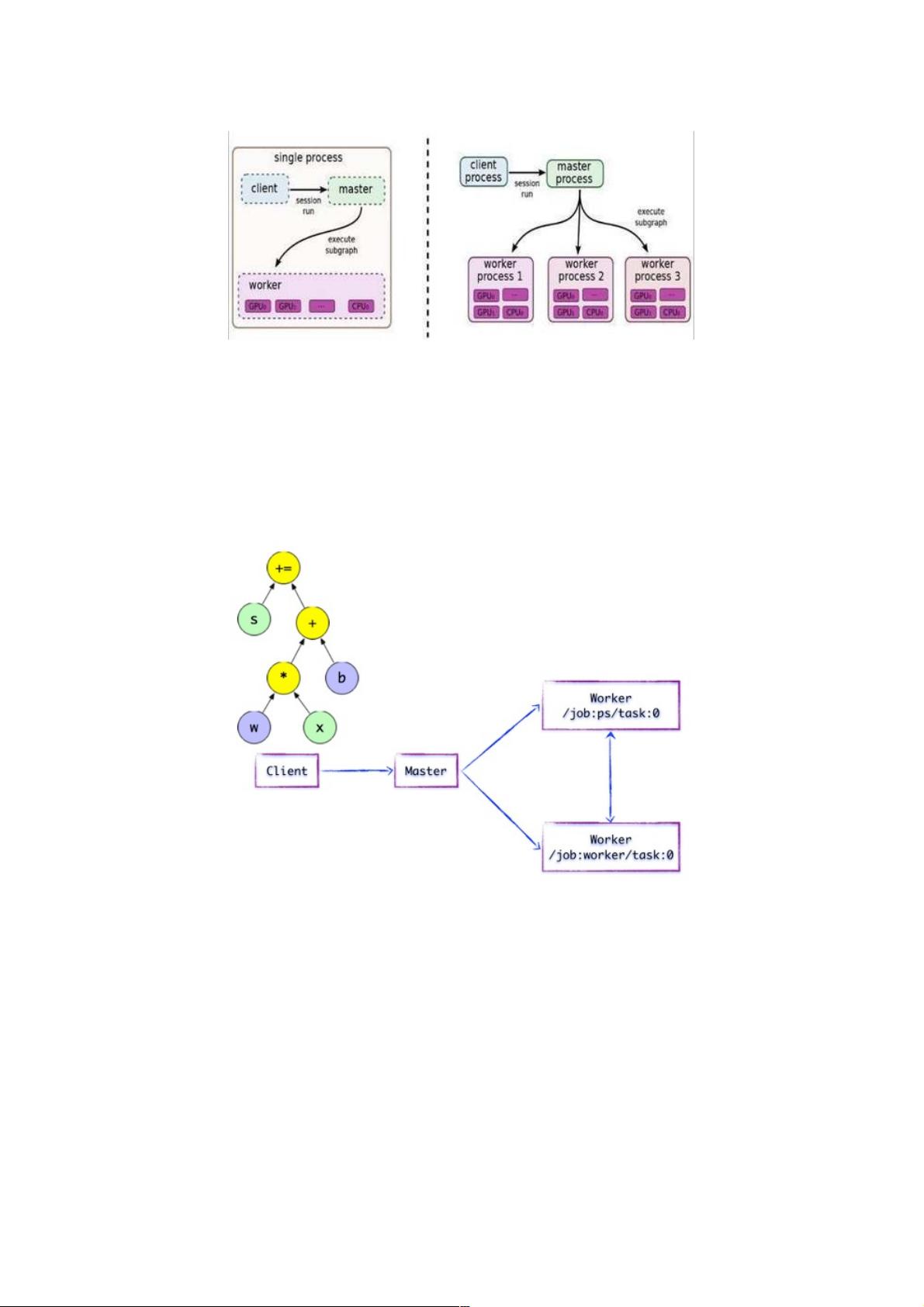
图1.1展示了TensorFlow单机模式下,客户端(用户编写代码)构造计算图,而分布式环境下,客户端与后台运行时通过Session的建立,将GraphDef发送至分布式Master。客户端的求值操作触发了Master对计算图的执行。
2. **计算图的运行机制**:
在分布式情况下,Master首先根据`Session.run`中的参数反向遍历计算图,找出依赖的最小子图。然后,这些子图被分解为多个“子图片段”,分配到不同的进程和硬件设备上执行,减少重复计算。
3. **任务分工与协调**:
- Master负责优化计算子图,通过公共表达式消除、常量折叠等技术提高性能。
- 参数相关的操作(如变量更新)通常被放在Parameter Server(PS)任务中,其他运算则在Worker任务中执行。
4. **数据传输**:
如果计算图的边跨越任务节点,Master会在任务间插入SEND和RECV操作,确保数据在不同节点之间的有效传递。
5. **执行流程**:
分配到任务中的“子图片段”作为本地子图被执行,Master在整个过程中起到协调和管理的角色,确保分布式环境下的计算流程顺利进行。
通过理解这些原理,开发者可以更好地设计和优化TensorFlow模型在分布式环境下的训练过程,提升系统的吞吐量和效率。这对于处理大规模数据和扩展到多台服务器的机器学习项目至关重要。
Tensorflow分布式原理理解分布式原理理解
实现原理
图1.1 TensorFlow单机版本和分布式版本的示例图
TensorFlow计算图的运行机制
客户
客户端基于TensorFlow的编程接口,构造计算图。此时,TensorFlow并未执行任何计算。直至建立会议会话,并以会议为桥
梁,建立客户端与后端运行时的通道,将的Protobuf格式的GraphDef发送至分布式Master。也就是说,当客户对OP结果进行
求值时,将触发Distributed Master的计算图的执行过程。如下图所示,Client构建了一个简单计算图。它首先将w与x进行矩阵
相乘,再与截距b按位相加,最后更新至第
图1.2简单的TensorFlow计算图分布式主
在分布式的运行时环境中,Distributed Master根据Session.run的Fetching参数,从计算图中反向遍历,找到所依赖的最小子
图。然后Distributed Master负责将该子图再次分裂为多个「子图片段“,以便在不同的进程和设备上运行这些”子图片段“。最
后,分布式大师将这些图片段派发给工作服务。随后工作服务启动「本地子图」的执行过程.Distributed Master将会缓存「子
图片段」,以便后续执行过程重复使用这些「子图片段」,避免重复计算。
下载后可阅读完整内容,剩余4页未读,立即下载
2022-07-11 上传
2022-07-11 上传
2020-09-18 上传
2019-08-09 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2020-09-18 上传
点击了解资源详情

weixin_38559866
- 粉丝: 1
- 资源: 903
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言实现ATM.zip
- mysql视频.zip
- 余烬延迟类修饰符
- LFA_14_04
- lambda-webhook-demo:用Rust编写的示例AWS Lambda函数以处理GitHub Webhooks
- k3-query-field
- break-all-pieces:(1kyu算法)网址
- FortyTwo:四十二是生命,宇宙和万物的终极问题的答案。 它也是一个很棒的库,可在Android应用程序中显示多项选择答案
- WPF 导航界面悬浮两行之间的卡片 漂亮的卡片导航界面 WPF漂亮渐变颜色 WPF漂亮导航头界面 UniformGrid漂亮展现
- ios-networkLayerArticle:2k21中用于iOS应用的网络层
- 参考资料-基于51单片机的12864LCD显示驱动.zip
- beamerthemeEdinburgh:爱丁堡大学的乳胶投影仪主题
- Interrobang-crx插件
- 啊~真香系列之 Yapi 浏览器扩展插件
- 基于java的开发源码-Message-Driven Bean EJB实例源代码.zip
- 罗萨林德
