TensorFlow分布式详解:客户端、主控与工作节点的协同
2 浏览量
更新于2024-08-29
收藏 311KB PDF 举报
"Tensorflow分布式原理理解"
在深入探讨TensorFlow分布式原理之前,首先要理解TensorFlow的基本概念和架构。TensorFlow是一个强大的开源库,用于构建和训练机器学习模型。它的核心是构建计算图(Computational Graph),这是一个数据流图,其中节点代表操作(Ops),边代表数据(Tensors)。在TensorFlow中,程序主要由两部分组成:定义计算图和执行计算图。
1. **客户端(Client)**:
客户端是TensorFlow程序的起点,开发人员在这里编写代码,构建计算图。客户端通过Session接口与Master和Worker通信。客户端不直接执行计算,而是创建并初始化计算图,然后将这个图发送到服务器端。
2. **计算图执行**:
当客户端创建一个Session,它实际上是在与DistributedMaster建立连接。计算图被编码成GraphDef(Protobuf格式)并发送给DistributedMaster。客户端对运算结果进行求值时,DistributedMaster开始执行计算图。
3. **分布式Master**:
DistributedMaster是协调整个分布式系统的关键角色。它接收客户端的请求,根据需要反向遍历计算图以找到依赖的操作,并将其分解为更小的子图。这些子图会被分配到不同的Worker上执行。DistributedMaster还负责缓存子图,以提高效率,避免重复计算。
4. **Worker**:
Worker是实际执行计算图操作的实体,每个Worker可以连接到多个硬件设备,如CPU或GPU。Worker接收到DistributedMaster分发的子图后,在本地设备上执行相应的运算。
5. **单机模式与分布式模式**:
单机模式下,所有的Client、Master和Worker都在同一台机器的同一进程中运行,适合于小规模的实验和开发。而在分布式模式中,这些组件可以分布在不同的机器上,以利用多台机器的计算资源,适合大规模的训练任务。
6. **分布式策略**:
TensorFlow支持多种分布式策略,如数据并行、模型并行和混合并行。数据并行是将数据集分割,让不同Worker并行处理;模型并行则是将大型模型的不同部分放在不同的Worker上;混合并行结合了两者,以最大化资源利用率。
7. **集群配置**:
在分布式环境中,需要定义集群配置,声明每台机器的角色(如master或worker)以及它们的地址。集群配置通过`tf.train.ClusterSpec`对象传递给TensorFlow程序。
8. **会话管理**:
Session在分布式环境中扮演着关键角色,它负责协调计算图的执行。在分布式设置中,Session可能需要额外的参数,如目标字符串(指定Master的位置)和配置选项,以适应分布式环境。
9. **容错机制**:
TensorFlow的分布式系统具备一定的容错能力,如果某个Worker失败,系统可以重新调度其上的计算任务,确保训练的连续性。
总结起来,TensorFlow的分布式原理涉及客户端的计算图构建、DistributedMaster的图执行与分解、Worker的计算以及集群的协调。理解这些概念有助于在大规模的机器学习项目中有效地利用分布式计算资源,提升模型训练的效率和效果。
Tensorflow分布式原理理解分布式原理理解
1. Tensorflow 实现原理
实现原理
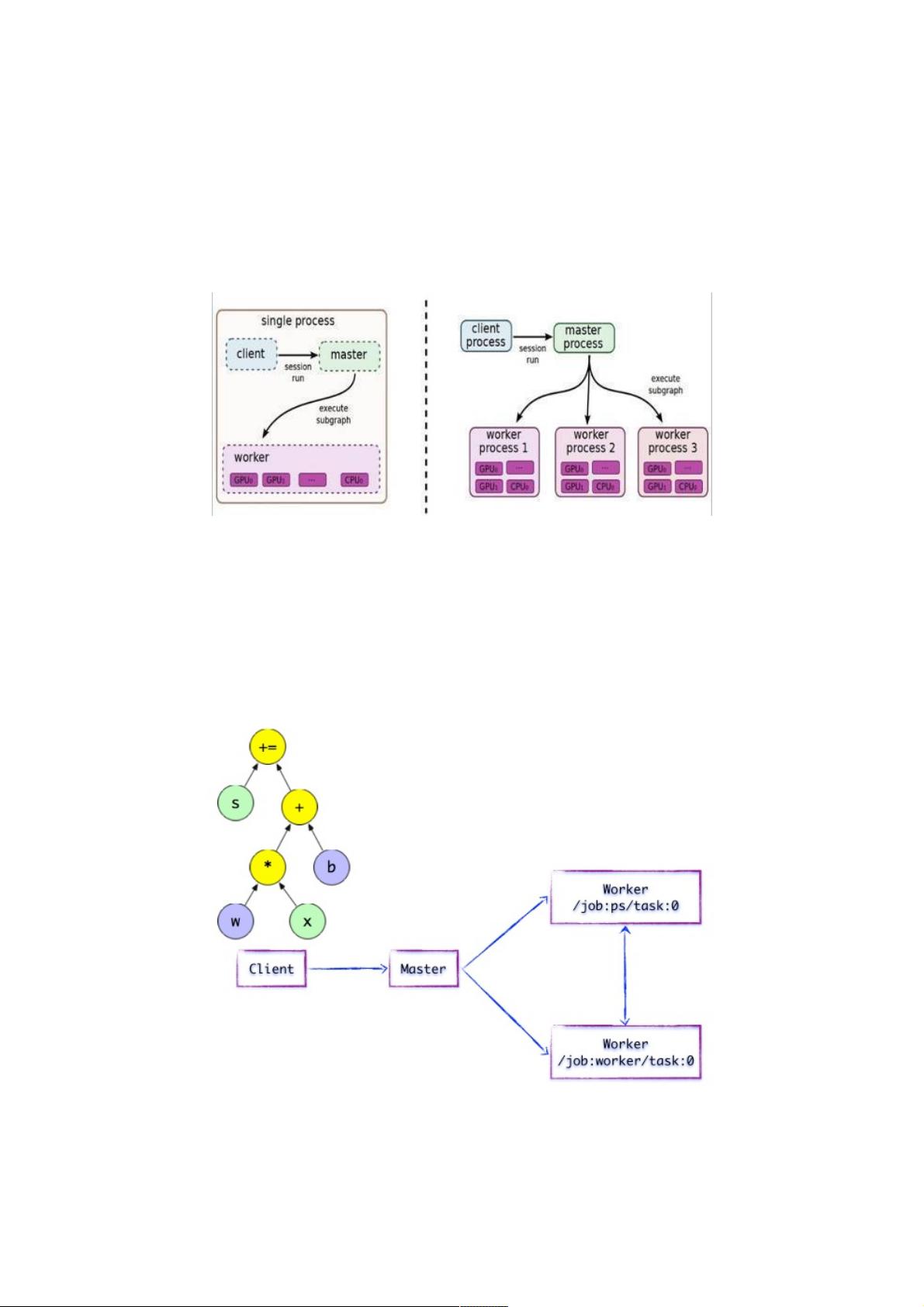
TensorFlow有一个重要组件client,顾名思义,就是客户端,它通过Session的接口与master及多个worker相连。其中每一个
worker可以与多个硬件设备(device)相连,比如CPU或GPU,并负责管理这些硬件。而master则负责指导所有worker按流
程执行计算图。TensorFlow有单机模式和分布式模式两种实现,其中单机指client、master、worker全部在一台机器上的同一
个进程中;分布式的版本允许client、master、worker在不同机器的不同进程中,同时由集群调度系统统一管理各项任务。
图1.1 TensorFlow单机版本和分布式版本的示例图
TensorFlow计算图的运行机制
Client
Client基于TensorFlow的编程接口,构造计算图。此时,TensorFlow并未执行任何计算。直至建立Session会话,并以
Session为桥梁,建立Client与后端运行时的通道,将Protobuf格式的GraphDef发送至Distributed Master。也就是说,当Client
对OP结果进行求值时,将触发Distributed Master的计算图的执行过程。如下图所示,Client构建了一个简单计算图。它首先
将w与x进行矩阵相乘,再与截距b按位相加,最后更新至s。
图1.2 简单的TensorFlow计算图
Distributed Master
在分布式的运行时环境中,Distributed Master根据Session.run的Fetching参数,从计算图中反向遍历,找到所依赖的最小子
图。然后Distributed Master负责将该子图再次分裂为多个「子图片段」,以便在不同的进程和设备上运行这些「子图片
段」。最后,Distributed Master将这些图片段派发给Work Service。随后Work Service启动「本地子图」的执行过程。
Distributed Master将会缓存「子图片段」,以便后续执行过程重复使用这些「子图片段」,避免重复计算。
下载后可阅读完整内容,剩余4页未读,立即下载
2022-07-11 上传
2022-07-11 上传
点击了解资源详情
2020-09-18 上传
2019-08-09 上传
点击了解资源详情
点击了解资源详情
2020-09-18 上传
点击了解资源详情

weixin_38499553
- 粉丝: 11
- 资源: 904
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
