Hadoop集群配置与HA高可用实践
需积分: 10 99 浏览量
更新于2024-07-15
收藏 680KB PDF 举报
"这份文档是关于HBase和Hive在海量数据管理中的安装与使用的参照手册,涵盖了Hadoop高可用性验证以及MapReduce历史记录的查看。"
在大数据处理领域,HBase和Hive是两个重要的组件。HBase是一个基于Hadoop的分布式列式数据库,适合实时读写操作,尤其适合于大数据的存储。而Hive则是基于Hadoop的数据仓库工具,它提供了SQL-like的语言(HQL)用于数据查询和分析,适用于离线批处理场景。
在Hadoop集群中,MapReduce是进行大规模数据处理的核心计算框架。实验中提到了如何查看MapReduce运行的历史记录。通过运行`mapred--daemonstart historyserver`命令启动JobHistoryServer,这台服务器会记录所有MapReduce作业的执行历史。用户可以通过访问http://c0:19888来查看这些历史记录,以便于监控和分析作业性能。关闭JobHistoryServer则使用`mapred--daemonstop historyserver`命令。
高可用性(High Availability, HA)是Hadoop集群的关键特性,确保单点故障不会影响整个系统的正常运行。在上述实验中,演示了Hadoop HA的验证过程。当在c1节点上手动kill掉NameNode进程后,由于Hadoop HA的配置,系统会自动将NameNode的角色切换到其他活动节点,这里是c0。通过`hdfs haadmin -getAllServiceState`命令可以查看所有服务的状态,可以看到c0成为active状态,而c1无法连接,表明了HA的自动故障转移功能。
在HA环境中,通常会有多个NameNode实例,其中一个处于active状态,处理所有的客户端请求,另一个或多个处于standby状态,实时同步active NameNode的数据。当active NameNode故障时,standby NameNode会接替其角色,保证服务不间断。
HBase与Hive的集成使得用户可以利用Hive的查询能力分析存储在HBase中的数据,这对于需要混合OLAP(在线分析处理)和OLTP(在线事务处理)场景的企业非常有用。安装和配置HBase和Hive通常涉及设置Hadoop环境、安装相关软件包、配置集群参数以及创建必要的表和分区等步骤。
这个参照手册详细介绍了HBase和Hive在大数据环境下的部署和使用,以及Hadoop HA的验证方法,对于理解大数据基础设施的搭建和运维有着重要的指导意义。
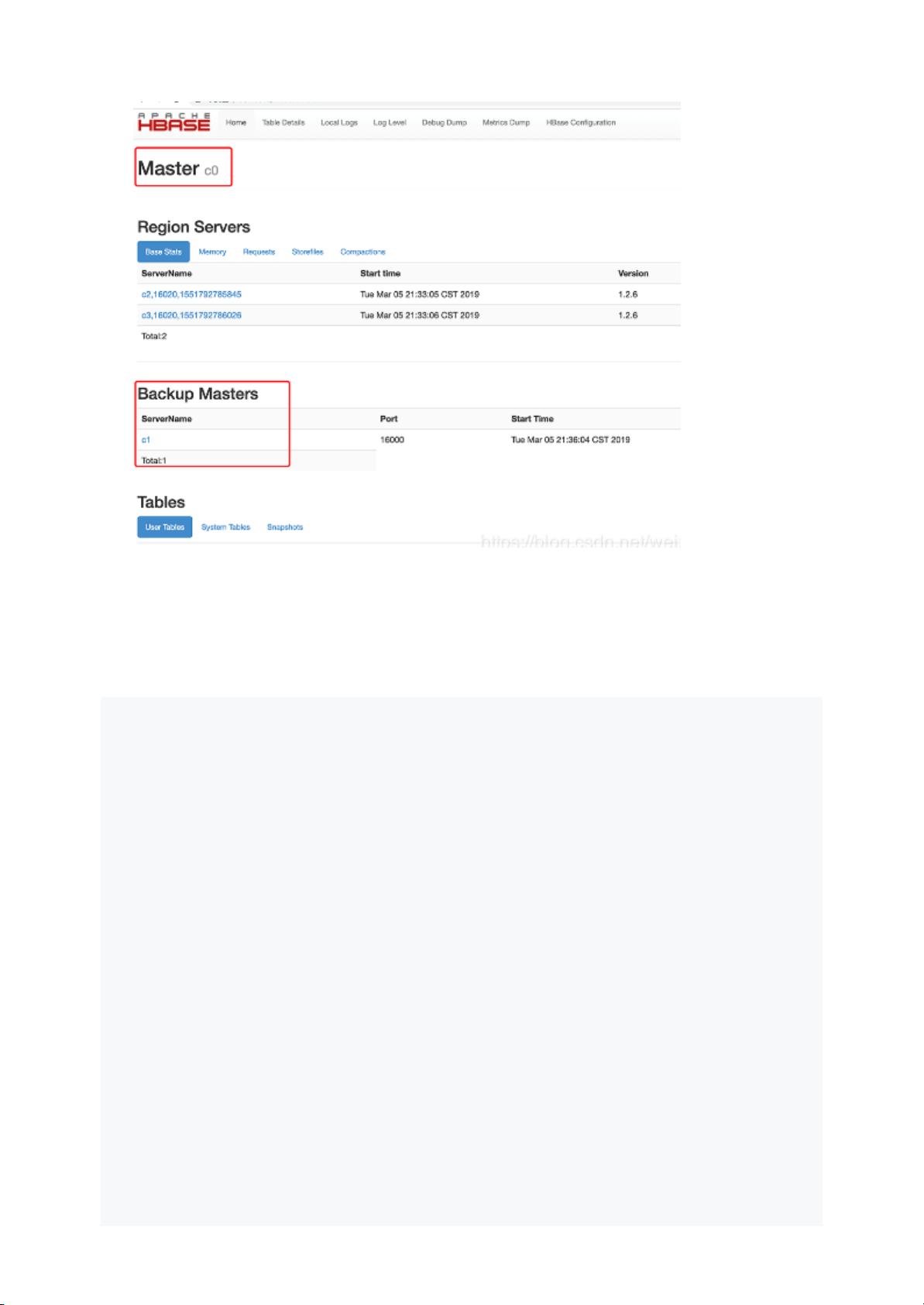
2.启动后浏览http://c0:16010,可以看到c0是Master而c1是BackupMaster
13.2.1用Shell测试连接Hbase
在c0上用shell测试连接Hbase,然后依次执行代码中的命令
命令前有类似hbase(main):001:0>的语句
[root@c0~]#hbaseshell
HBaseShell
Use"help"togetlistofsupportedcommands.
Use"exit"toquitthisinteractiveshell.
Version1.4.9,rd625b212e46d01cb17db9ac2e9e927fdb201afa1,WedDec511:54:10PST2018
hbase(main):001:0>list
TABLE
0row(s)in0.2440seconds
=>[]
hbase(main):002:0>version
1.4.9,rd625b212e46d01cb17db9ac2e9e927fdb201afa1,WedDec511:54:10PST2018
hbase(main):003:0>create'mshk_top','uid','name'
0row(s)in1.4720seconds
=>Hbase::Table‐mshk_top
hbase(main):004:0>list
TABLE
mshk_top
1row(s)in0.0090seconds
=>["mshk_top"]
hbase(main):005:0>put'mshk_top','10086','name:mshk.top‐name','mshk.top‐value'
剩余24页未读,继续阅读
2019-07-24 上传
2021-07-14 上传
2021-03-31 上传
2024-05-10 上传

xinxin_xz
- 粉丝: 0
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







