CFMS血栓弹力图:心内科应用的突破与进展
版权申诉
90 浏览量
更新于2024-07-18
收藏 1.86MB PPT 举报
CFMS血栓弹力图心内科应用的PPT介绍了血栓弹力图(Thromboelastography, TEG)这一在心内科中日益重要的诊断工具。血栓弹力图是一种动态、实时检测血液凝固过程的技术,它能够全面评估血液的凝固和纤维蛋白溶解能力,从而提供对凝血全貌的深入理解。
该报告首先回顾了血栓弹力图的发展历程,从TEG的发明(1948年)到在肝移植中的早期应用(1980年代),再到心血管手术中的推广(1995-1996年),TEG® 5000系统的专利获得以及诊断树和血小板图的专利申请。血栓弹力图逐渐成为了肝移植的标准化临床治疗手段,并在全球范围内得到广泛应用,中国也在2012年引进并发展了国产西芬斯产品。
血栓弹力图功能主要包括以下几个方面:
1. **凝血途径**:通过监测血小板聚集(GPIIb/IIIa+纤维蛋白原)、纤维蛋白网形成以及血栓发展,血栓弹力图能够揭示凝血途径的多个关键步骤,如血小板激活和凝血活酶的生成。
2. **与常规凝血检测对比**:相较于传统的APTT(活化部分凝血活酶时间)、PT(凝血酶时间)、FIB(纤维蛋白原)、TT(凝血酶原时间)等项目,血栓弹力图提供了更全面的凝血状态评估,它能同时观察内源性和外源性凝血系统,以及血小板功能,而常规检测往往难以全面反映这些。
3. **图形与报告单**:血栓弹力图产生的结果通常表现为曲线图,包括R时间(凝血时间)、K值(血小板激活指标)、MA(最大振幅)等参数,直观显示血液凝固速度和强度。报告单会详细解读这些数据,帮助医生做出更精确的诊断。
4. **临床应用**:血栓弹力图广泛应用于心内科的多种场景,例如心血管疾病(如冠心病、心梗)、手术前评估、抗凝治疗监控、血栓性疾病诊断及管理,以及血栓预防和溶栓治疗决策支持。
总结来说,血栓弹力图作为一项先进的凝血功能检测手段,弥补了常规凝血检测的局限性,为临床提供了更为精准的血栓风险评估和个体化治疗策略,是现代心内科不可或缺的辅助诊断工具。随着技术的进步和研究的深入,其在国内的应用也将更加广泛和深入。
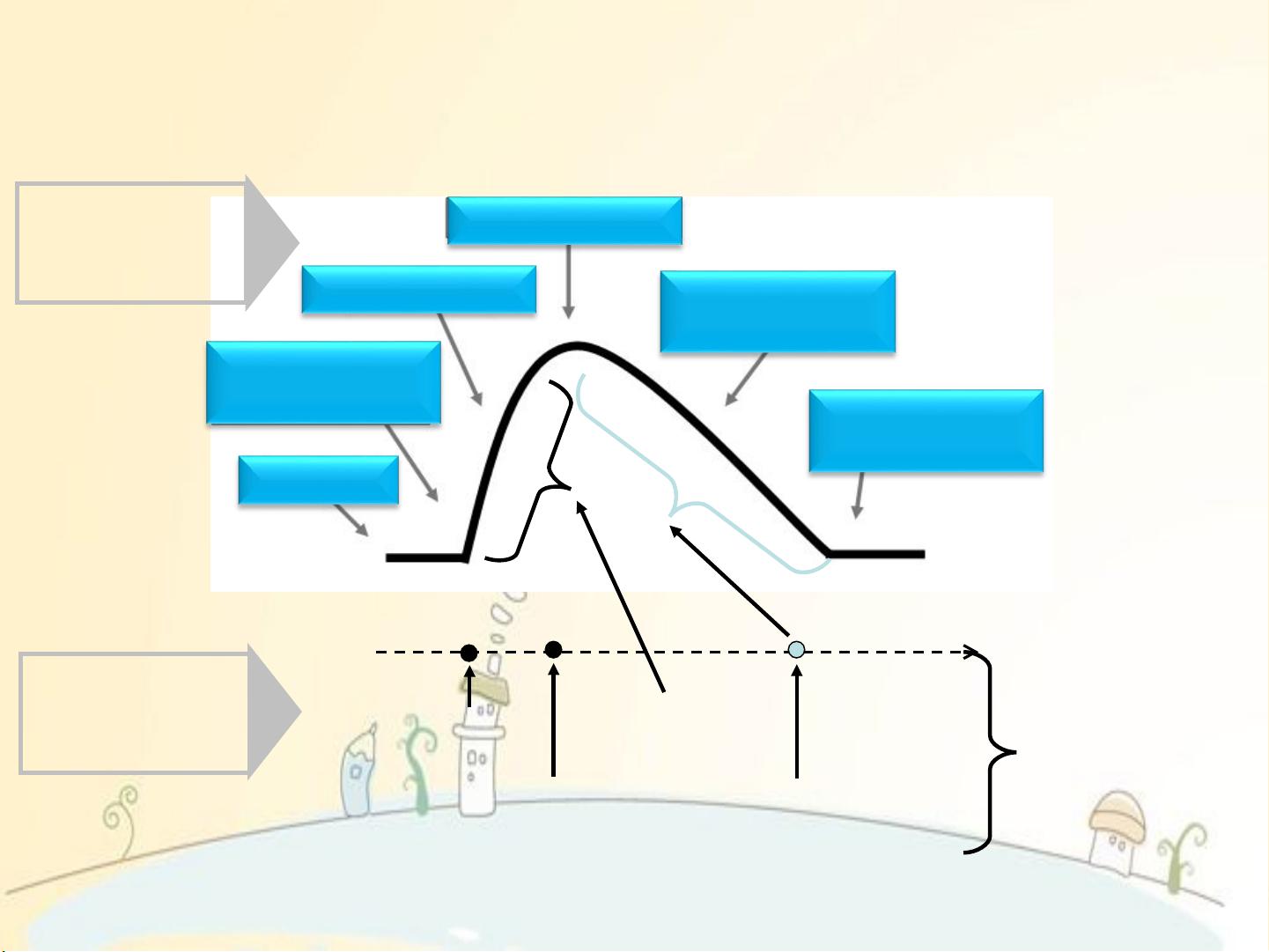
常规凝血检测
PT
APTT
纤维蛋白含量
D- 二聚体
FDP
血小板计数
难以评估
凝血全貌
血液凝固过程
启动
血小板栓子形成
纤维蛋白链形成
血凝块增多
最大血凝块
血凝块
降解
血凝块溶解
损伤修复
连续全貌全血检测
与传统凝血检测的区别

剩余54页未读,继续阅读
2021-09-30 上传
2023-05-25 上传
2024-09-06 上传
2024-09-06 上传
2024-09-06 上传

Dambulla
- 粉丝: 7
- 资源: 3万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机人脸表情动画技术发展综述
- 关系数据库的关键字搜索技术综述:模型、架构与未来趋势
- 迭代自适应逆滤波在语音情感识别中的应用
- 概念知识树在旅游领域智能分析中的应用
- 构建is-a层次与OWL本体集成:理论与算法
- 基于语义元的相似度计算方法研究:改进与有效性验证
- 网格梯度多密度聚类算法:去噪与高效聚类
- 网格服务工作流动态调度算法PGSWA研究
- 突发事件连锁反应网络模型与应急预警分析
- BA网络上的病毒营销与网站推广仿真研究
- 离散HSMM故障预测模型:有效提升系统状态预测
- 煤矿安全评价:信息融合与可拓理论的应用
- 多维度Petri网工作流模型MD_WFN:统一建模与应用研究
- 面向过程追踪的知识安全描述方法
- 基于收益的软件过程资源调度优化策略
- 多核环境下基于数据流Java的Web服务器优化实现提升性能
