提升性能:集成学习详解—多样性和Bagging与Boosting
需积分: 0 120 浏览量
更新于2024-08-05
收藏 1.59MB PDF 举报
本章深入探讨了机器学习工程师面试中的一个重要主题——集成学习。集成学习是一种策略,它通过组合多个学习器(个体或基学习器)的预测结果,以提高整体模型的性能。这种技术特别关注于实现多样性和减少过拟合风险,这是设计高效集成算法的关键因素。
首先,我们明确了集成学习的定义,将其划分为同质集成(所有个体学习器类型相同)和异质集成(包含不同类型的个体学习器)。集成学习的优势主要体现在三个层面:统计上的多样性可以降低过拟合风险,因为多个学习器可能从不同的角度逼近真实模型;计算上,通过多次迭代和组合,减少了陷入糟糕局部最优的可能性;表示上,当单个学习器的假设空间不足以覆盖问题时,集成能够利用多种方法的优势。
在众多集成学习方法中,本章重点介绍了两大代表性的技术:Bagging(自助采样法)和Boosting。Bagging通过随机抽样训练数据并构建多个独立的学习器,它们的预测结果通过投票或平均得到最终决策,降低了模型之间的相关性。而Boosting系列,尤其是AdaBoost和GradientBoosting,通过逐步调整样本权重和学习器,强调了弱学习器的组合,从而形成强大且精确的整体模型。
值得注意的是,作者在讲解过程中注重保持内容的易读性,尽量避免复杂的数学知识,仅要求基本的微积分、线性代数和概率论基础。同时,每一步的推导都配有详尽的解释和背景知识,使得初学者也能理解。由于机器学习领域的广泛性,本章并未涵盖所有细节,而是选择了关键流派进行介绍。
为了帮助读者更好地理解和应用这些知识,文中穿插了大量问题,引导读者思考和实践。最后,章节以“快问快答”的形式提供了总结和答疑,便于读者巩固所学内容并进一步探索相关领域。
本章是机器学习工程师面试中关于集成学习理论和实践的重要参考,深入浅出地讲解了集成学习的基本概念、关键原理和常见方法,为面试者提供了扎实的基础知识和理解框架。
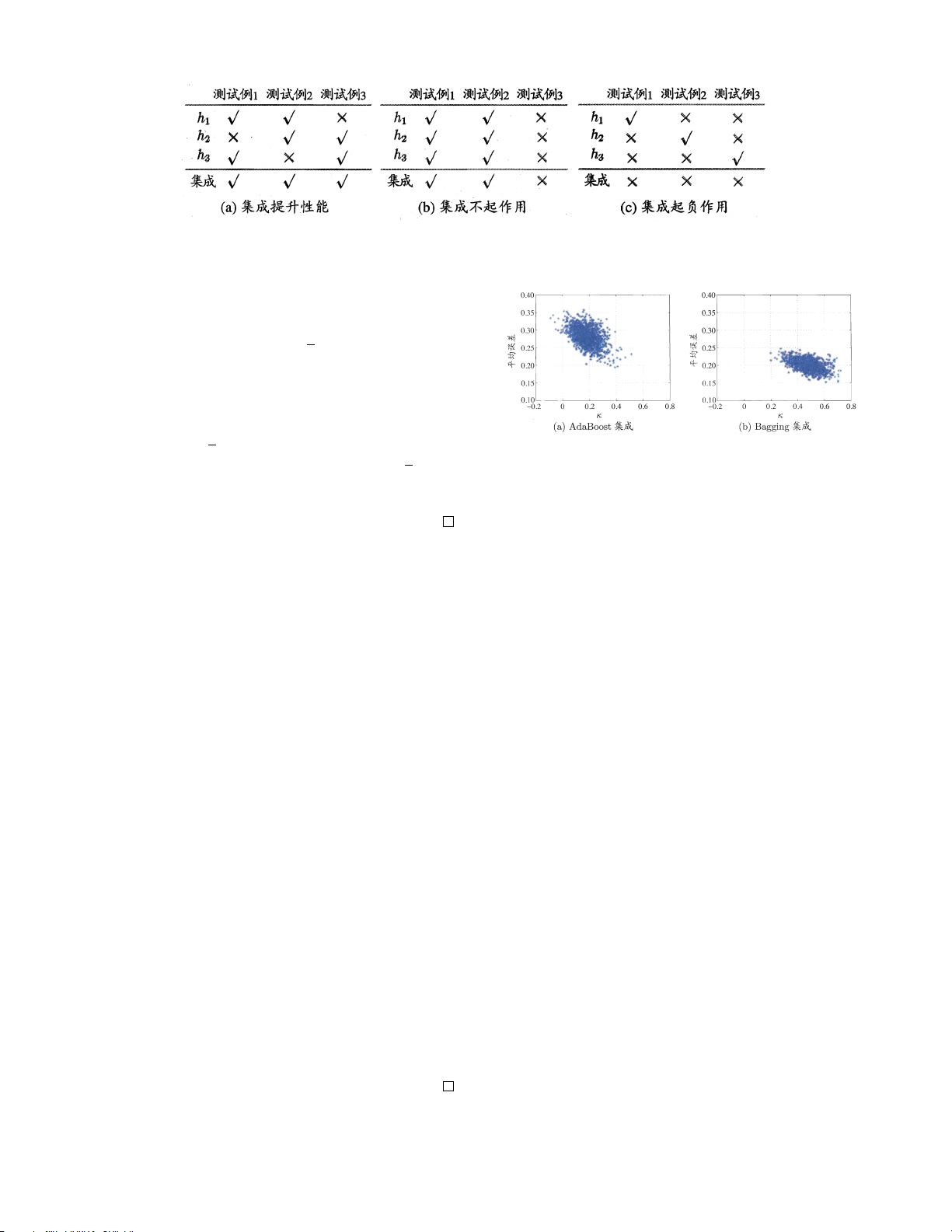
Figure 1: 集成个体应 “好而不同”. 图中 h
i
表示第 i 个分类器,
√
表示分类正确, × 表示分类错误. 本图源于 [32].
T 指数下降
E[I(H(x) = y)] ≤ exp
−
1
2
T (1 − 2e
2
)
. (2)
Proof. 若有超过半数的基分类器分类正确, 则集成分类
就正确. 利用 Hoeding 不等式,
Pr(H(x) = y) =
⌊
T
2
⌋
k=0
T
k
(1−e)
k
e
T −k
≤ exp(−
1
2
T (1−2e
2
)) .
(3)
引理 1 假设基学习器误差相互独立, 但在现实任务
中, 基学习器是为解决同一个问题训练出来的, 它们显
然不独立. 通过在学习过程引入随机性, 可以获得依赖
程度没有那么高的学习器.
定理 2 (误差-分歧分解 (error-ambiguity decomposi-
tion) [16] ). 假设使用加权平均法完成回归任务, 则
(H(x)−y)
2
=
T
t=1
α
t
(h
t
(x)−y)
2
−
T
t=1
α
t
(h
t
(x)−H(x))
2
.
(4)
可以看出, 个体学习器准确性越高、多样性越大, 则集
成越好.
Proof. 以下简记 H(x) 为 H, h
t
(x) 为 h
t
,
(H − y)
2
= y
2
− 2yH + H
2
=
T
t=1
α
t
h
2
t
− 2Hy + y
2
−
T
t=1
α
t
h
2
t
+ 2H
2
− H
2
=
T
t=1
α
t
h
2
t
− 2h
t
y + y
2
−
T
t=1
α
t
h
2
t
− 2h
t
H + H
2
=
T
t=1
α
t
(h
t
− y)
2
−
T
t=1
α
t
(h
t
− H)
2
.
Figure 2: 在 UCI 数据集 tic-tac-toc 上的 kappa-误差
图. 每个集成包含 50 棵 C4.5 决策树. 本图源于 [32] .
误差-分歧分解的启示? 为了得到使集成结果比单
一学习器更好, 个体学习器要做到 “好而不同”, 即个体
学习器至少不差于弱学习器, 并且要有多样性 (diver-
sity), 学习器之间具有差异, 如图 1 所示. 事实上, 个体
学习器的准确性和多样性本身就存在冲突. 一般的, 准
确性很高之后, 要增加多样性就需要牺牲准确性.
多样性的度量方法? 基本思路是考虑个体分类器两
两之间的相似性, 对二分类数据集 D, 根据分类器 h
t
和
h
k
的预测结果的不同, 定义
a :=
m
i=1
I(h
t
(x
i
) = +1 ∧ h
k
(x
i
) = +1) ; (5)
b :=
m
i=1
I(h
t
(x
i
) = +1 ∧ h
k
(x
i
) = −1) ; (6)
c :=
m
i=1
I(h
t
(x
i
) = −1 ∧ h
k
(x
i
) = +1) ; (7)
d :=
m
i=1
I(h
t
(x
i
) = −1 ∧ h
k
(x
i
) = −1) , (8)
它们满足 a + b + c + d = m. 常见的多样性度量如表 2
所示. 此外, 可以将个体学习器成对的平均误差和多样
性度量绘制成二维散点图, 如图 2 所示. 散点位置越低,
这对分类器的准确性越高; 散点位置越靠左, 这对分类
器的多样性越大. 事实上, 现有的多样性度量都存在显
3
剩余10页未读,继续阅读
2018-03-29 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-05-09 上传

有只风车子
- 粉丝: 37
- 资源: 329
 我的内容管理
展开
我的内容管理
展开







最新资源
- 解决本地连接丢失无法上网的问题
- BIOS报警声音解析:故障原因与解决方法
- 广义均值移动跟踪算法在视频目标跟踪中的应用研究
- C++Builder快捷键大全:高效编程的秘密武器
- 网页制作入门:常用代码详解
- TX2440A开发板网络远程监控系统移植教程:易搭建与通用解决方案
- WebLogic10虚拟内存配置详解与优化技巧
- C#网络编程深度解析:Socket基础与应用
- 掌握Struts1:Java MVC轻量级框架详解
- 20个必备CSS代码段提升Web开发效率
- CSS样式大全:字体、文本、列表样式详解
- Proteus元件库大全:从基础到高级组件
- 74HC08芯片:高速CMOS四输入与门详细资料
- C#获取当前路径的多种方法详解
- 修复MySQL乱码问题:设置字符集为GB2312
- C语言的诞生与演进:从汇编到系统编程的革命
