SparkSQL Catalyst Optimizer深度解析
102 浏览量
更新于2024-08-28
收藏 196KB PDF 举报
"SparkSQLCatalyst源码分析之Optimizer"
SparkSQL中的Catalyst模块是其查询优化的关键组件,而Optimizer则是Catalyst的核心部分,它负责将解析后的LogicalPlan(逻辑计划)转换为更高效的执行形式。在深入探讨Optimizer之前,我们先回顾一下SparkSQL的处理流程:SqlParser解析SQL语句,Analyzer执行语义分析,生成Resolved的LogicalPlan,然后Optimizer接手进行优化。
Optimizer的主要任务是应用一系列的规则(Rules)和策略(Strategies),这些规则以Batches的形式组织起来,对LogicalPlan进行迭代改进。每个Batch都包含一组特定的规则,例如:
1. CombineLimits:此规则用于合并多个Limit操作,减少不必要的计算,提高效率。在数据流中,如果存在多个Limit操作,它们可以被合并为一个,避免重复计算。
2. ConstantFolding:常量折叠,这个规则会尽可能地计算出表达式的静态值,比如常量表达式和函数的组合,从而减少运行时的计算负担。
3. FilterPushdown:过滤器下推策略,旨在尽可能早地应用过滤条件,减少需要处理的数据量。这包括CombineFilters(合并过滤条件)、PushPredicateThroughProject(将过滤条件推过投影操作)和PushPredicateThroughJoin(推过连接操作)等。
4. NullPropagation、BooleanSimplification、SimplifyFilters、SimplifyCasts、SimplifyCaseConversionExpressions等其他规则,它们主要用于简化表达式,消除不必要的计算,比如处理空值、简化布尔表达式、优化过滤条件、简化类型转换和case表达式等。
在Catalyst中,所有这些规则都定义在Optimizer伴生对象的batches列表中,每个Batch都有一个固定的迭代次数(FixedPoint),以确保优化过程不会无限循环。RuleExecutor是执行这些规则的框架,它会按照Batches的顺序依次应用规则,直到满足固定迭代次数或者没有更多的优化可以做为止。
通过这种方式,Optimizer能够显著提升SparkSQL的性能,通过智能优化逻辑计划,减少不必要的计算,优化数据处理路径,使执行计划更加高效。这种基于规则的优化策略在大数据处理领域非常常见,因为它可以灵活适应不同的查询场景,并且易于扩展新的优化规则。
理解SparkSQL的Optimizer不仅有助于我们更好地理解查询执行的过程,还可以指导我们在实际开发中编写更高效的SQL语句,利用其内在的优化机制,提升大数据处理的效率。同时,对于想要深入了解SparkSQL源码或者进行二次开发的开发者来说,熟悉和研究Optimizer的实现细节是必不可少的。
SparkSQLCatalyst源码分析之源码分析之Optimizer
前几篇文章介绍了Spark SQL的Catalyst的核心运行流程、SqlParser,和Analyzer 以及核心类库TreeNode,本文将详细讲解Spark
SQL的Optimizer的优化思想以及Optimizer在Catalyst里的表现方式,并加上自己的实践,对Optimizer有一个直观的认识。
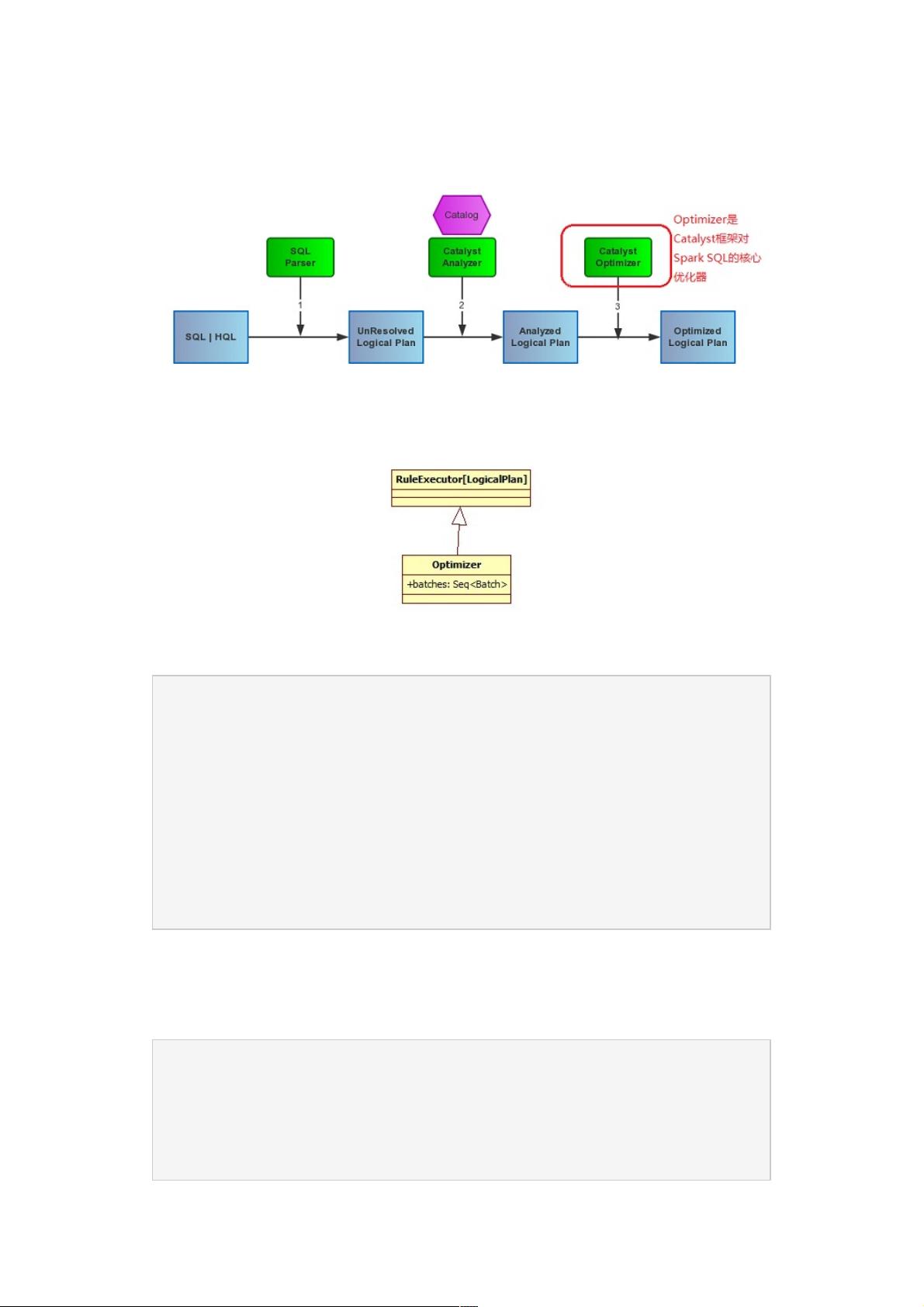
Optimizer的主要职责是将Analyzer给Resolved的Logical Plan根据不同的优化策略Batch,来对语法树进行优化,优化逻辑计划节点
(Logical Plan)以及表达式(Expression),也是转换成物理执行计划的前置。如下图:
一、Optimizer
Optimizer这个类是在catalyst里的optimizer包下的唯一一个类,Optimizer的工作方式其实类似Analyzer,因为它们都继承自
RuleExecutor[LogicalPlan],都是执行一系列的Batch操作:
Optimizer里的batches包含了3类优化策略:1、Combine Limits 合并Limits 2、ConstantFolding 常量合并 3、Filter Pushdown 过滤
器下推,每个Batch里定义的优化伴随对象都定义在Optimizer里了:
object Optimizer extends RuleExecutor[LogicalPlan] {
val batches =
Batch("Combine Limits", FixedPoint(100),
CombineLimits) ::
Batch("ConstantFolding", FixedPoint(100),
NullPropagation,
ConstantFolding,
BooleanSimplification,
SimplifyFilters,
SimplifyCasts,
SimplifyCaseConversionExpressions) ::
Batch("Filter Pushdown", FixedPoint(100),
CombineFilters,
PushPredicateThroughProject,
PushPredicateThroughJoin,
ColumnPruning) :: Nil
}
另外提一点,Optimizer里不但对Logical Plan进行了优化,而且对Logical Plan中的Expression也进行了优化,所以有必要了解一下
Expression相关类,主要是用到了references和outputSet,references主要是Logical Plan或Expression节点的所依赖的那些
Expressions,而outputSet是Logical Plan所有的Attribute的输出:
如:Aggregate是一个Logical Plan, 它的references就是group by的表达式 和 aggreagate的表达式的并集去重。
case class Aggregate(
groupingExpressions: Seq[Expression],
aggregateExpressions: Seq[NamedExpression],
child: LogicalPlan)
extends UnaryNode {
override def output = aggregateExpressions.map(_.toAttribute)
override def references =
(groupingExpressions ++ aggregateExpressions).flatMap(_.references).toSet
}
下载后可阅读完整内容,剩余7页未读,立即下载
2021-03-03 上传
2021-01-30 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-11-19 上传
2024-11-19 上传
2024-11-19 上传

weixin_38623000
- 粉丝: 5
- 资源: 925
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入浅出:自定义 Grunt 任务的实践指南
- 网络物理突变工具的多点路径规划实现与分析
- multifeed: 实现多作者间的超核心共享与同步技术
- C++商品交易系统实习项目详细要求
- macOS系统Python模块whl包安装教程
- 掌握fullstackJS:构建React框架与快速开发应用
- React-Purify: 实现React组件纯净方法的工具介绍
- deck.js:构建现代HTML演示的JavaScript库
- nunn:现代C++17实现的机器学习库开源项目
- Python安装包 Acquisition-4.12-cp35-cp35m-win_amd64.whl.zip 使用说明
- Amaranthus-tuberculatus基因组分析脚本集
- Ubuntu 12.04下Realtek RTL8821AE驱动的向后移植指南
- 掌握Jest环境下的最新jsdom功能
- CAGI Toolkit:开源Asterisk PBX的AGI应用开发
- MyDropDemo: 体验QGraphicsView的拖放功能
- 远程FPGA平台上的Quartus II17.1 LCD色块闪烁现象解析
