大型数据问题中的聚类方法比较与应用
需积分: 10 170 浏览量
更新于2024-09-12
收藏 432KB PDF 举报
本文档深入探讨了大型数据问题中的聚类方法在知识发现和数据挖掘(KDD)中的应用。作者David Wishart作为圣安德鲁斯大学管理系荣誉研究员,关注于将聚类分析与决策树技术进行比较,以展示其在发现数据库结构中的高效性。Clustan软件,适用于Windows 95/98或NT系统,将通过实例演示如何处理成千上万的数据案例或变量。
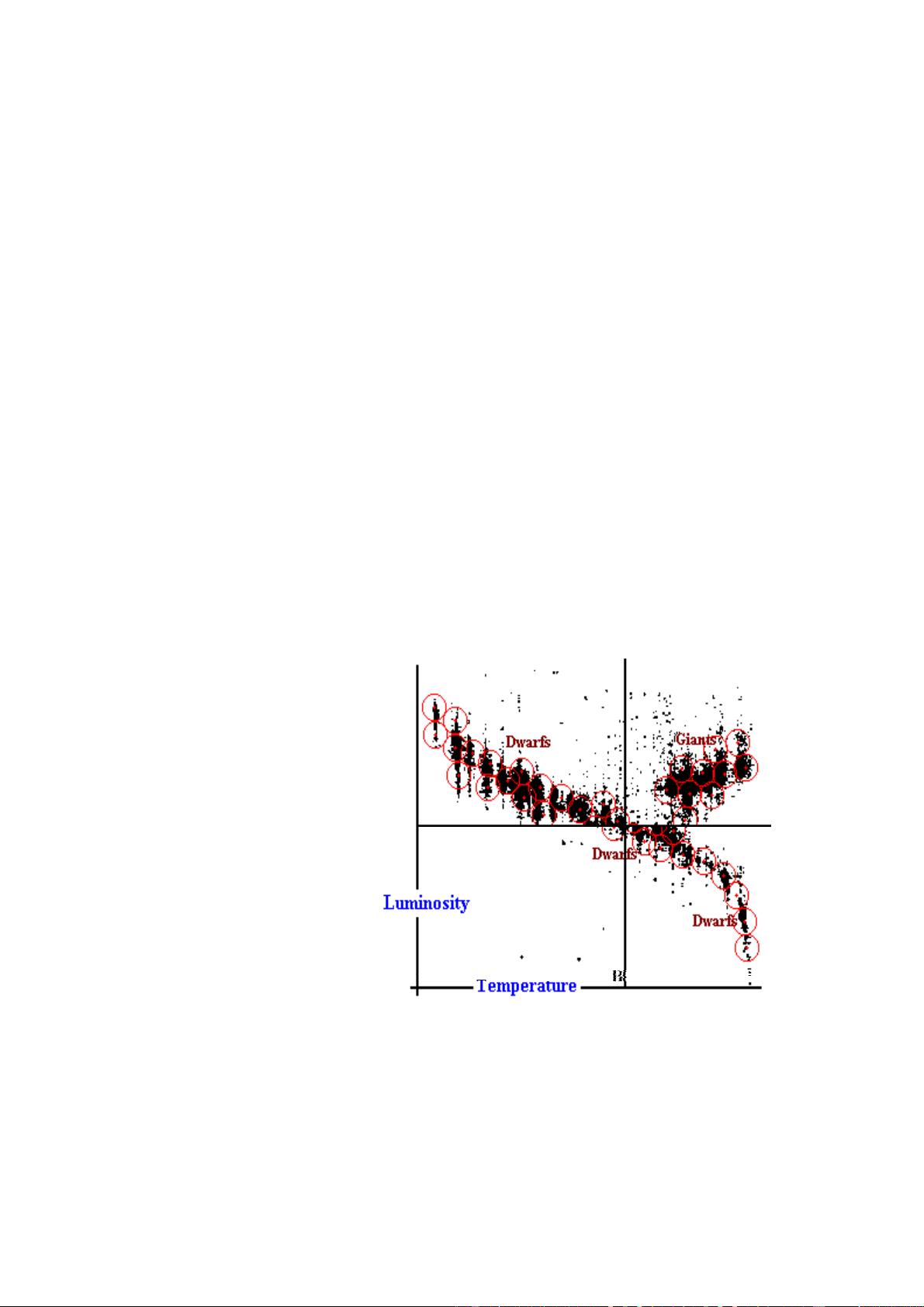
在数据挖掘领域,决策树是一种常见的技术,它基于决策规则,通过分割关键变量来划分数据集。图1展示了天文学中的一个经典二维散点图——视觉恒星的赫罗图,这显示了决策树如何帮助理解数据分布。然而,决策树常常被误解为能发现数据库中的同质化群体,如图2所示的CHAID类型方法构建的决策树示例。
实际上,如图1中的决策线A和B所示,决策树可能会在密集区域中产生分割,导致结果段落没有明确的边界。这意味着聚类方法对于大型数据集来说可能更为合适,因为它们可以识别出数据内部的非均匀结构,而不是简单地依赖于决策规则的单一路径。
聚类方法,如层次聚类、K-means、DBSCAN等,旨在根据数据对象之间的相似性或距离将它们分组,形成自然的类别。这些方法不依赖预先定义的规则,而是自动发现数据的内在模式。在处理大规模数据时,聚类可以提供更全面的群组洞察,尤其是在没有明确的预设分类标准时。
大型数据集往往包含噪声、异常值和复杂的关系,而聚类能够对这些复杂性进行建模,发现潜在的高维结构。例如,当数据维度很高时,传统的决策树可能难以表现出来,但聚类可以发现数据的低维表示,这在降维可视化和模式识别中尤其有用。
此外,聚类方法还可以用于数据预处理,通过将数据分组成相似的部分,简化后续分析,提高效率。它们也可以作为数据探索工具,帮助数据科学家了解数据分布的特征,为机器学习模型的选择和参数调整提供依据。
本文通过对比和展示Clustan软件的应用,强调了在大型数据问题中采用聚类方法的重要性,特别是在揭示数据内在结构和模式方面,其相对于决策树的适用性和优势。这对于理解和处理海量数据,尤其是在KDD任务中,具有实际操作价值。
Clustering Methods for Large Data Problems
David Wishart
Honorary Research Fellow, Department of Management
University of St. Andrews, Fife KY16 9AL, Scotland
Email: D.Wishart@St-Andrews.ac.uk Website: www.clustan.com
Summary
The paper discusses the use of clustering methods in knowledge discovery and data mining (KDD)
and compares cluster analysis to decision trees as an efficient means of finding structure in
databases. The latest Clustan software for Windows 95/98 or NT will be demonstrated with
examples of many thousands of cases or variables.
A popular data mining technique involves the construction of decision trees, based on
decision rules which define a partition of a dataset by splitting on key variables. Fig 1 reproduces a
classical 2-dimensional scatter from astronomy, the H-R diagram of visual stars, and Fig 2
illustrates a decision tree obtainable by CHAID-type methods.
It is often assumed that the decision tree finds homogeneous groups of cases from a
database; however, this simple example shows this to be false. The decision lines A and B dissect
dense regions of the scatter and the resulting segments are unbounded. In particular, it is easy to
find points which are very similar but fall on either sides of a decision line. Also, because the
partitions are orthogonal to the co-ordinate axes, they fail to detect the internal covariance exhibited
by the scatter.
It is also apparent from this
example that the decision tree
approach characterises a dataset by
univariate “top down” splitting.
We argue from a classical
taxonomy analogue that
multivariate, or “bottom up”,
hierarchical clustering and
exemplification is a more
appropriate and versatile approach.
Cluster analysis partitions a
large dataset into homogeneous
subsets by grouping closely related
cases into tight clusters. These
core clusters, which map the main
density, can then be used to re-
construct the underlying model, for
segmentation analysis and for
exemplification.
)LJ 7KH +5 GLDJUDP IRU YLVXDO VWDUV
VKRZLQJ WZR UHFRJQLVHG FODVVHV RI JLDQWV DQG
GZDUIV /LQHV $ DQG % LQGLFDWH GHFLVLRQ WUHH
VSOLWVRQOXPLQRVLW\RUWHPSHUDWXUHDVLQ )LJ
7KHWHVVHOODWLRQRIVPDOOVSKHULFDOFOXVWHUVVKRZV
DQ DOWHUQDWLYH QRQRUWKRJRQDO PDSSLQJ RI JLDQW
DQGGZDUIVWDUV
下载后可阅读完整内容,剩余3页未读,立即下载
2023-05-27 上传
2023-06-12 上传
2023-05-27 上传
2023-05-26 上传
2023-05-30 上传
2023-05-20 上传
2023-11-04 上传
2023-05-26 上传
2023-05-03 上传

guokuihai
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- WebLogic集群配置与管理实战指南
- AIX5.3上安装Weblogic 9.2详细步骤
- 面向对象编程模拟试题详解与解析
- Flex+FMS2.0中文教程:开发流媒体应用的实践指南
- PID调节深入解析:从入门到精通
- 数字水印技术:保护版权的新防线
- 8位数码管显示24小时制数字电子钟程序设计
- Mhdd免费版详细使用教程:硬盘检测与坏道屏蔽
- 操作系统期末复习指南:进程、线程与系统调用详解
- Cognos8性能优化指南:软件参数与报表设计调优
- Cognos8开发入门:从Transformer到ReportStudio
- Cisco 6509交换机配置全面指南
- C#入门:XML基础教程与实例解析
- Matlab振动分析详解:从单自由度到6自由度模型
- Eclipse JDT中的ASTParser详解与核心类介绍
- Java程序员必备资源网站大全
