
Author's personal copy
example, in the IEEECS collection, abbreviations are generally used in tags (e.g atl) and their meanings (e.g. abstract)
can be hard to guess. In addition, the XML document samples analyzed manually may not cover all distinct tags/paths
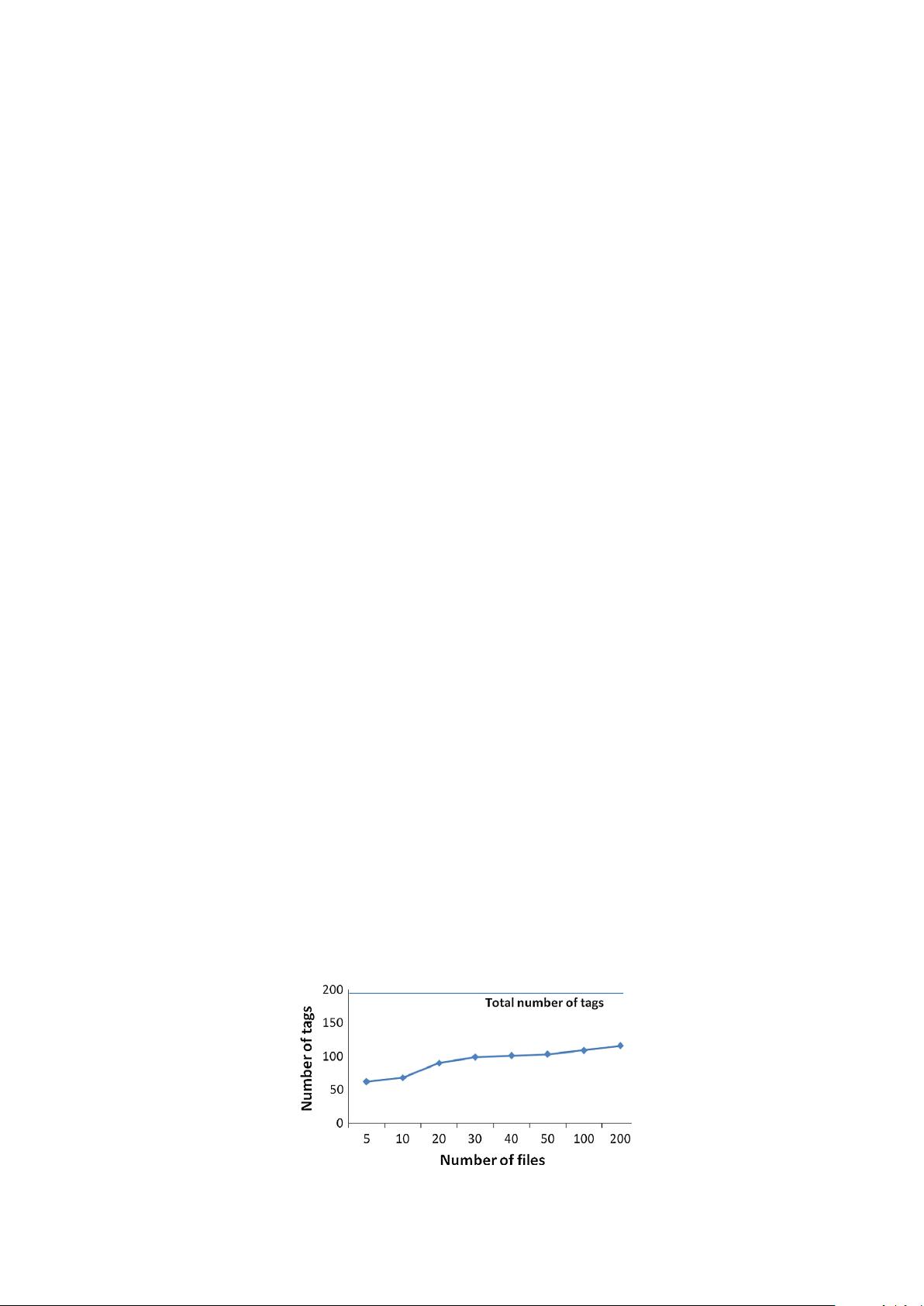
in the collection. As a result, there is always the risk of missing some tags. Fig. 2 shows the number of distinct tags that
can be observed with respect to the number of documents in the IEEECS collection. If 200 documents are analyzed
manually, only about 60% of the distinct tags out of 189 are seen. We can observe that, if we want to cover all the tags,
the process involves a great amount of manual operations, which are tedious and inefficient. As we mentioned earlier,
paths could provide more accurate information than tags on the meaning/role of the elements. If different paths have
to be analyzed by experts, there will be even a much larger number of them, as Fig. 3 shows.
(2) Subjective interpretation. The manual setting of tag/path weights is strongly influenced by experts’ background
knowledge and their understanding of the documents. Depending on the expert, the resulting weights can be very dif-
ferent. This can be reflected by an analysis on the correlation between the weights assigned by different experts. We
have conducted a simple experiment where three people working on XML retrieval were asked to assign weights
(from 0 to 5.0) to the tags in the IEEECS collection. The result on the Pearson Correlation Coefficient between the three
group of manual weights are only 0.637, 0.738 and 0.682, with an average of 0.686. As for the path weights set on the
Wikipedia collection, the correlation coefficients are 0.584, 0.766 and 0.681 respectively, and these coefficients shar-
ply declined to 0.556, 0.428 and 0.582 on the IEEECS collection. The results clearly show that it is very difficult to reach
consensus about the tag/path weights even among experts, and this issue becomes more serious when the collection
has more complex structures.
(3) Many false alarms. As a collection usually has a large number of XML documents, and in each document the number of
tags ranges from tens to hundreds, it is likely that the experts have misjudgments on the actual meanings of these tags.
For example, the tag atl in the IEEECS collection is found to mean article title. In our experiment, the experts are
inclined to assign the greatest weight (5.0) to atl. However, atl is also used as the tag of the title of article listed in
the reference. In this case, the experts are misguided because they ignore some other meanings of the tag. Even if
the experts understand all meanings of a tag, it is still a challenge to set tag weight because of the different meanings
of the same tag.
The above observations clearly indicate that a manual setting of tag/path weights is not tractable in large scale applica-
tions. In this paper, we propose an automatic method to determine the weights of tags and paths by taking advantage of the
contents of the corresponding fields. The general idea is to assign a large weight to a tag or path if the corresponding field can
summarize well the contents of the whole document. This is indeed the criterion implicitly used in human evaluation of tag/
path importance. Rather than relying on human subjective judgments, we propose a method based on the average potential
power that the content of the field can be generalized to the whole document. This measure is called Average Topic Gener-
alization (ATG), which is based on the similarity between the content of the field and that of the whole document.
Intuitively, the above approach can reflect well the human assignments. For example, the title, keywords, abstract, and
section title are generally believed to be more important than the paragraph, figure, table, and reference. The former fields
are also those that are more related to the document topic than the latter, thus have a higher ATG power. If a query-term
occurs in the nodes corresponding to title, keywords, abstract, or section title in some documents, these documents or nodes
should be considered more relevant to the query, compared with those documents or nodes where the query-term occurs in
other nodes.
In the ATG model, an important step is the estimation of topical similarity, which involves term weighting. Instead of
using the traditional term weighting methods, we propose a new term weighting strategy taking into account several fea-
tures proposed in the previous studies.
The approach has been tested on two collections, IEEECS and Wikipedia. On both collections, we observe increased effec-
tiveness for XML retrieval than the traditional keyword-based approach. In addition, the weights determined by the ATG
model are found to correlate more strongly with the human assignments, than those determined using other criteria.
The main contributions of this paper are summarized as follows:
Fig. 2. The number of observed tags increases with the number of documents in the IEEECS collection.
50 D. Liu et al. / Information Sciences 249 (2013) 48–66
剩余19页未读,继续阅读

weixin_38649091
- 粉丝: 6
- 资源: 933
 我的内容管理
展开
我的内容管理
展开







最新资源
- 多传感器数据融合手册:国外原版技术指南
- MyEclipse快捷键大全,提升编程效率
- 从零开始的编程学习:Linux汇编语言入门
- EJB3.0实例教程:从入门到精通
- 深入理解jQuery源码:解析与分析
- MMC-1电机控制ASSP芯片用户手册
- HS1101相对湿度传感器技术规格与应用
- Shell基础入门:权限管理与常用命令详解
- 2003年全国大学生电子设计竞赛:电压控制LC振荡器与宽带放大器
- Android手机用户代理(User Agent)详解与示例
- Java代码规范:提升软件质量和团队协作的关键
- 浙江电信移动业务接入与ISAG接口实战指南
- 电子密码锁设计:安全便捷的新型锁具
- NavTech SDAL格式规范1.7版:车辆导航数据标准
- Surfer8中文入门手册:绘制等高线与克服语言障碍
- 排序算法全解析:冒泡、选择、插入、Shell、快速排序
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


