使用HTMLParser提取网页正文信息的方法
版权申诉
47 浏览量
更新于2024-07-02
收藏 311KB DOC 举报
"HTMLParser抽取Web网页正文信息"
在互联网领域,HTMLParser是一个强大的工具,用于解析和处理HTML文档。在浏览Web网页时,通常需要从众多的网页元素中抽取出主要内容,即网页的主题信息,以便快速获取核心内容,提高信息获取效率。网页中的“噪音”内容,如导航条、广告和版权信息等,往往会影响用户的浏览体验。
HTMLParser是一个快速且实时的HTML解析库,可以从SourceForge.net下载。首先,你需要下载htmlparser1_620050925.zip文件,解压得到htmlparser.jar,并将其添加到项目的classpath中。接着,在代码中引入相应的HTMLParser包,通过创建Parser对象来解析HTML文本或直接处理URL。
以下是一个基本的使用示例:
```java
Parser parser = new Parser("http://www.yahoo.com.cn");
```
初始化Parser实例后,你可以使用`extractAllNodesThatAre`方法来提取特定类型的HTML标签。这个方法接受一个HTML标签类作为参数,例如`LinkTag`, `ImageTag`, `FormTag`, `TableTag`等,它们都位于`org.htmlparser.tags`包内。这样,你可以方便地处理不同类型的HTML标签,并将结果存储在一个列表中。每个列表元素代表一个特定标签的实例,通过这个实例,你可以访问标签的起始和结束位置,以及其中的文本信息,甚至可以访问其父标签和所有子标签。
对于处理不规范的HTML,HTMLParser特别有用,因为它会自动修复未关闭的标签,确保生成的HTML字符串具有完整的结构,不会破坏原有的页面布局。例如,如果你有一个包含未关闭标签的HTML文件,HTMLParser会自动补充缺少的闭合标签,使得处理后的HTML字符串能够在页面上正确渲染。
在实际应用中,你可能需要对HTML内容进行更复杂的处理,例如提取特定类别的链接、图片或段落。这时,你可以结合使用`Tag`类的特定方法,如`getAttributes()`来获取标签的属性,或`getText()`来获取标签内的纯文本。
HTMLParser提供了一个强大而灵活的框架,帮助开发者有效地从HTML网页中抽取出所需的主题信息,减少噪音内容,提升Web应用的可用性和用户体验。通过熟练掌握HTMLParser的使用,开发者可以构建出能够智能处理和分析HTML文档的工具或服务。
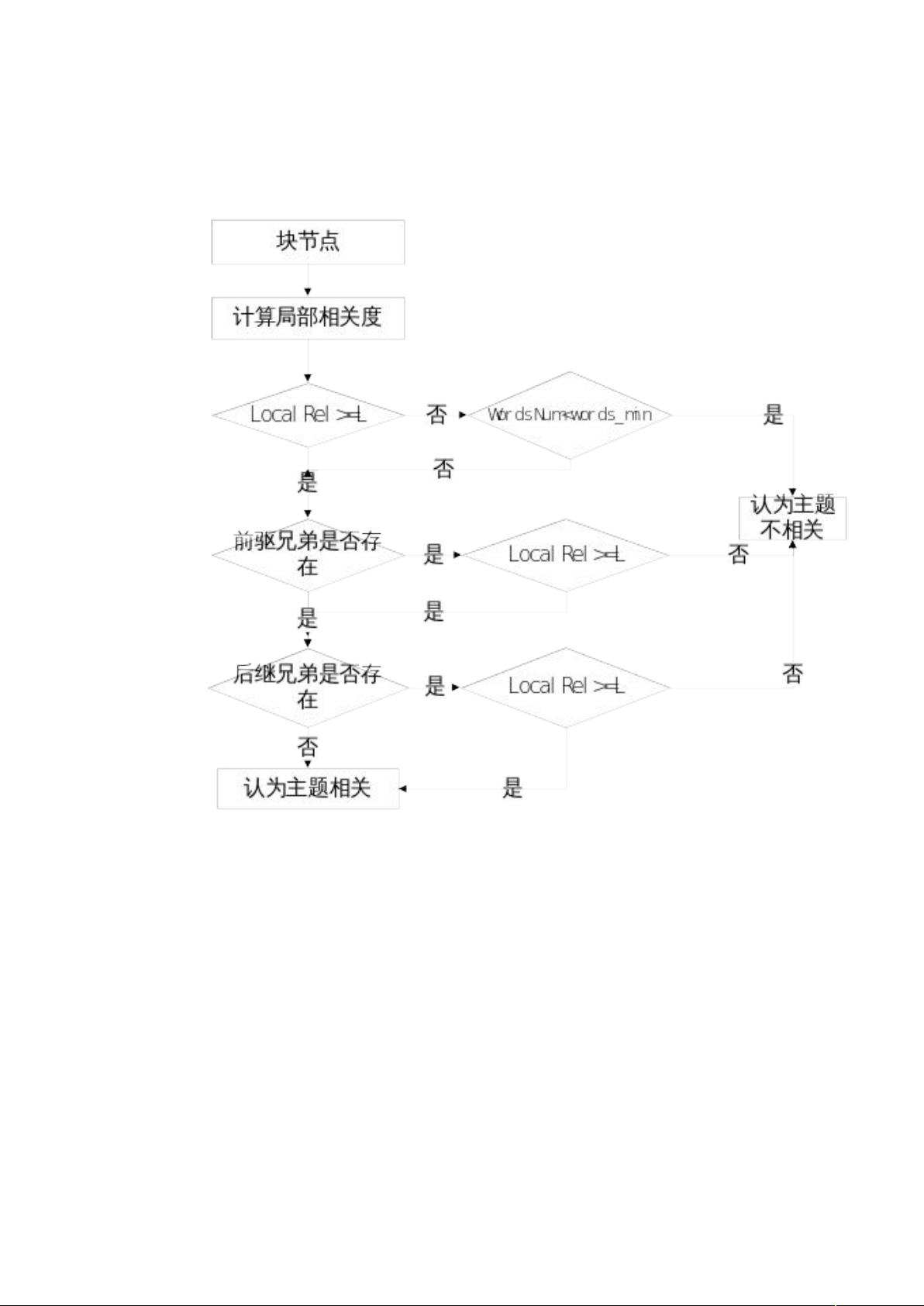
&52 为 " 且 +32 大于 C,认为局部相关)。上下文相关性即判定
该内容块节点的前驱兄弟和后继兄弟的主题相关性。前驱兄弟和后继兄弟必须
是包含有中文内容的结点。主题内容块的判定算法如图:
+3& 是规定内容块节点的非链接中文字符总数的最小值。一般情
况下,若 +32;+3&,则称该节点为空或没有内容,没有内容
的块节点是主题不相关的。当然,若 )<* 时,且 +32<*
+3& 时,此时并不能说明该块就是主题相关的。它只能说明该块是局部
相关的。原因基于如下观察:
a、一些局部相关度大的块,例如一些与主题无关的广告内容,它们可能
没有链 接或包含 较 少 的链 接,因此它们可能 )<* , 且
+32<*+3&。
b、 即使 +32;*+3&,也不能判断它是主题无关的。
因为一些小信息量的主题内容,如正文的标题或正文中的小信息
因此还要通过它前后的兄弟节点的主题相关性来判定是否主题相关。本系统对
;<节点是单独处理的,因此;<节点和;3&=<节点用于以上信息抽取
算法中。
剩余17页未读,继续阅读
2013-11-26 上传
2014-07-18 上传
2011-09-27 上传
2019-03-16 上传
2012-03-22 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

智慧安全方案
- 粉丝: 3807
- 资源: 59万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
