Spark性能优化:深度解析数据倾斜调优
"Spark性能优化:数据倾斜调优"
在Spark的大数据处理中,性能优化是一项至关重要的任务。本文聚焦于数据倾斜调优,这是解决高级性能问题的关键环节。数据倾斜通常表现为部分task执行时间过长,严重影响整体作业的效率,甚至可能导致内存溢出(OOM)错误。数据倾斜的根本原因在于shuffle过程中,某些key对应的数据分布不均,导致部分task负载过重。
调优策略主要包括识别和处理数据倾斜。当发现task执行速度差距悬殊或者作业突然出现OOM异常时,应考虑是否存在数据倾斜问题。例如,997个task能在短时间内完成,但有三两个task耗时极长,这通常是数据倾斜的典型表现。
要定位导致数据倾斜的代码,可以关注那些涉及shuffle操作的Spark算子,如`groupByKey`、`reduceByKey`、`join`、`sortByKey`等。这些操作会导致数据根据key进行重新分布,如果key的分布不均匀,就会产生数据倾斜。例如,一个key对应大量数据,而其他key仅对应少量数据,那么处理大量数据的task就会成为性能瓶颈。
解决数据倾斜的方法多样,包括但不限于以下几种:
1. 数据预处理:对数据进行预处理,比如哈希分桶、范围分区,以减少倾斜key的出现概率。
2. 增加并行度:增大partition数量,使数据更均匀地分配到task中,但要注意这可能会增加内存压力。
3. 倾斜key处理:对于已知的倾斜key,可以使用`bucketBy`或`coalesce`等方法,手动控制其分布。
4. 随机扰动key:在shuffle前对key进行轻微的随机化,避免特定key的数据过于集中。
5. 动态分区裁剪:在join操作中,通过设置` spark.sql.shuffle.partitions`和`spark.sql.autoBroadcastJoinThreshold`,限制分区数量和广播join的大小,减轻倾斜。
在实践中,通常需要结合具体场景,综合运用以上策略来解决数据倾斜问题。同时,监控和日志分析也是定位和解决数据倾斜的重要手段,通过分析task的执行时间和内存使用情况,可以找出问题所在,并针对性地优化。
Spark的数据倾斜调优是一项复杂但必要的工作,它涉及到对shuffle操作的理解,以及对数据分布特性的深入洞察。只有通过细致的分析和合理的优化,才能确保Spark作业的高效稳定运行。
Spark性能优化:数据倾斜调优性能优化:数据倾斜调优
前言
继《Spark性能优化:开发调优篇》和《Spark性能优化:资源调优篇》讲解了每个Spark开发人员都必须熟知的开发调优与资
源调优之后,本文作为《Spark性能优化指南》的高级篇,将深入分析数据倾斜调优与shuffle调优,以解决更加棘手的性能问
题。
数据倾斜调优
调优概述
有的时候,我们可能会遇到大数据计算中一个最棘手的问题——数据倾斜,此时Spark作业的性能会比期望差很多。数据倾斜
调优,就是使用各种技术方案解决不同类型的数据倾斜问题,以保证Spark作业的性能。
数据倾斜发生时的
1、绝大多数task执行得都非常快,但个别task执行极慢。比如,总共有1000个task,997个task都在1分钟之内执行完了,但
是剩余两三个task却要一两个小时。这种情况很常见。
2、原本能够正常执行的Spark作业,某天突然报出OOM(内存溢出)异常,观察异常栈,是我们写的业务代码造成的。这种
情况比较少见。
数据倾斜发生的原?/p>
数据倾斜的原理很简单:在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如
按照key进行聚合或join等操作。此时如果某个key对应的数据量特别大的话,就会发生数据倾斜。比如大部分key对应10条数
据,但是个别key却对应了100万条数据,那么大部分task可能就只会分配到10条数据,然后1秒钟就运行完了;但是个别task
可能分配到了100万数据,要运行一两个小时。因此,整个Spark作业的运行进度是由运行时间最长的那个task决定的。
因此出现数据倾斜的时候,Spark作业看起来会运行得非常缓慢,甚至可能因为某个task处理的数据量过大导致内存溢出。
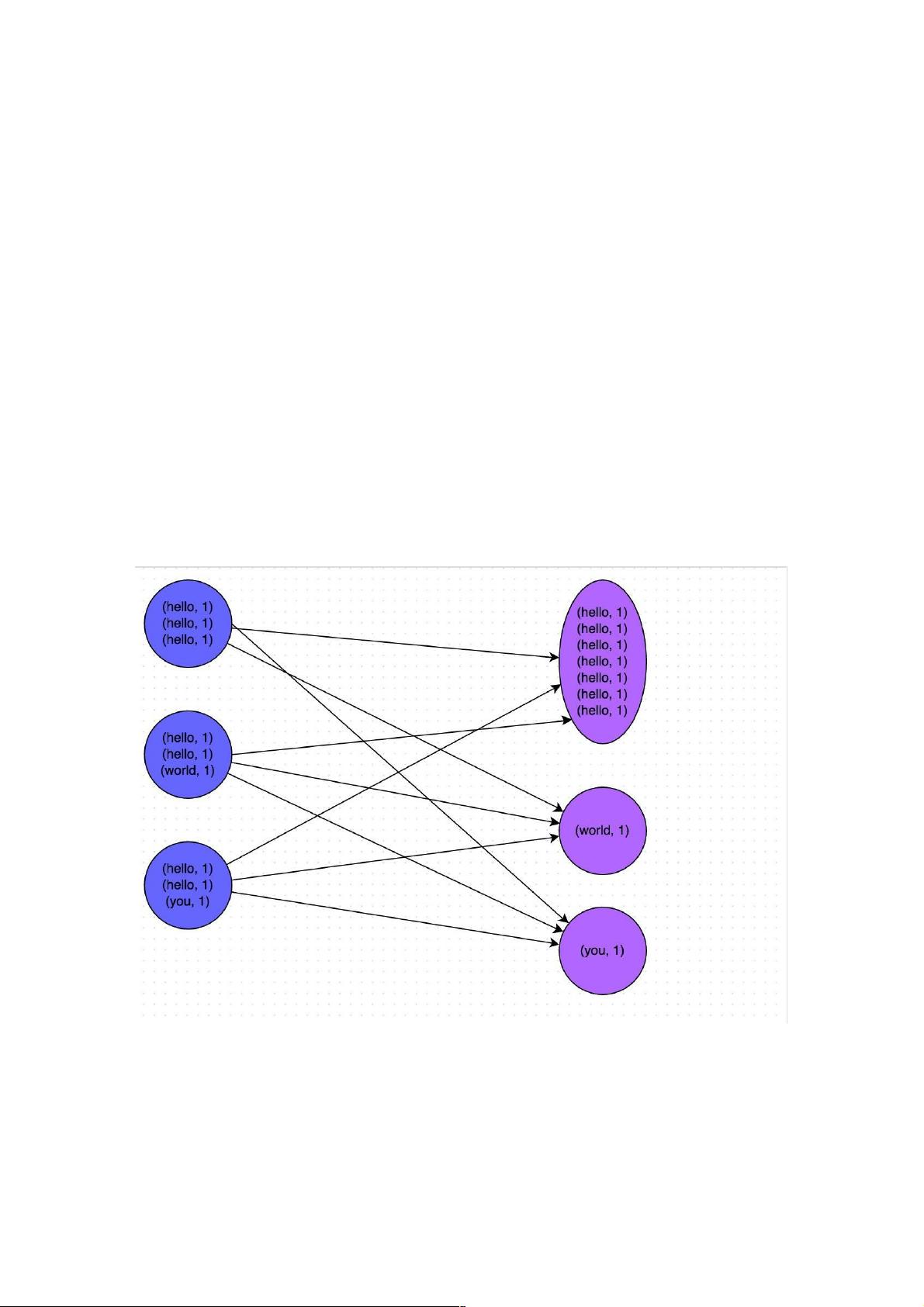
下图就是一个很清晰的例子:hello这个key,在三个节点上对应了总共7条数据,这些数据都会被拉取到同一个task中进行处
理;而world和you这两个key分别才对应1条数据,所以另外两个task只要分别处理1条数据即可。此时第一个task的运行时间
可能是另外两个task的7倍,而整个stage的运行速度也由运行最慢的那个task所决定。
数据倾斜原理
如何定位导致数据倾斜的代码
数据倾斜只会发生在shuffle过程中。这里给大家罗列一些常用的并且可能会触发shuffle操作的算子:distinct、groupByKey、
reduceByKey、aggregateByKey、join、cogroup、repartition等。出现数据倾斜时,可能就是你的代码中使用了这些算子中的
某一个所导致的。
下载后可阅读完整内容,剩余9页未读,立即下载
1026 浏览量
392 浏览量
516 浏览量
195 浏览量
146 浏览量
202 浏览量
135 浏览量
1366 浏览量
411 浏览量

weixin_38722052
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 多技术领域源码集锦:园林绿化官网企业项目
- 定制特色井字游戏Tic Tac Toe开源发布
- TechNowHorse:Python 3编写的跨平台RAT生成器
- VB.NET实现程序自动更新的模块设计与应用
- ImportREC:强大输入表修复工具的介绍
- 高效处理文件名后缀:脚本批量添加与移除教程
- 乐phone 3GW100体验版ROM深度解析与优化
- Rust打造的cursive_table_view终端UI组件
- 安装Oracle必备组件libaio-devel-0.3.105-2下载
- 探索认知语言连接AI的开源实践
- 微软SAPI5.4实现的TTSApp语音合成软件教程
- 双侧布局日历与时间显示技术解析
- Vue与Echarts结合实现H5数据可视化
- KataSuperHeroesKotlin:提升Android开发者的Kotlin UI测试技能
- 正方安卓成绩查询系统:轻松获取课程与成绩
- 微信小程序在保险行业的应用设计与开发资源包
