深度学习新纪元:ZerO初始化挑战传统方法
版权申诉
198 浏览量
更新于2024-08-04
收藏 1.38MB PDF 举报
"忘掉Xavier初始化吧!最强初始化方法ZerO来了"
在深度学习领域,模型的训练过程通常涉及多个关键步骤,其中之一便是权重参数的初始化。随机初始化是标准做法,因为梯度下降算法需要一个起始点,而全零初始化可能导致梯度消失问题。Xavier初始化和He初始化是两种广泛使用的规范化初始化技术,它们旨在保持神经网络层间的激活输出方差恒定,从而帮助模型更好地收敛。
Xavier初始化,又称为Glorot初始化,由Glorot和Bengio在2010年提出,它的目标是平衡输入层和输出层的方差,适用于具有sigmoid和tanh激活函数的全连接层。它通过计算输入节点和输出节点的数量来调整权重的初始分布,以确保前向传播中的信号不会过快衰减或增强。
He初始化,由He等人在2015年提出,更侧重于ReLU激活函数。由于ReLU的非饱和特性,其导数值通常更大,因此He初始化会使用更大的权重初始化值,以保持每一层的激活值方差不变,从而适应ReLU的特性。
然而,尽管这些初始化方法在一定程度上解决了稳定性问题,但它们仍然依赖于随机数生成,这意味着不同的随机种子可能会导致模型训练的不同结果。这使得随机性成为一个潜在的超参数,需要额外的调整和实验来优化。
文章提到的新方法——ZerO初始化,是一种完全确定的初始化策略,它试图消除随机初始化的不确定性,同时满足模型训练中的关键要求,如信号传播和梯度下降。ZerO方法的创新之处在于它提供了一种不依赖于随机数种子的初始化方式,理论上可以提高模型的性能和训练的可重复性。
ZerO初始化的具体细节可能包括对权重和偏置的特定计算,以确保在模型的每一层中都有合适的初始值,从而在训练初期就能达到理想的梯度传播状态。这种方法可能涉及到对网络结构、激活函数和损失函数的深入理解,以及对优化过程的数学分析。
ZerO初始化代表了初始化技术的一种进步,它尝试克服现有初始化方法的局限性,为深度学习模型提供更稳定、更可预测的训练起点。这种方法的引入,对于减少训练中的超参数敏感性、提高模型的泛化能力和训练效率都可能具有重要意义。然而,任何新的初始化方法都需要经过广泛的实验验证,以证明其在各种任务和网络架构上的有效性。
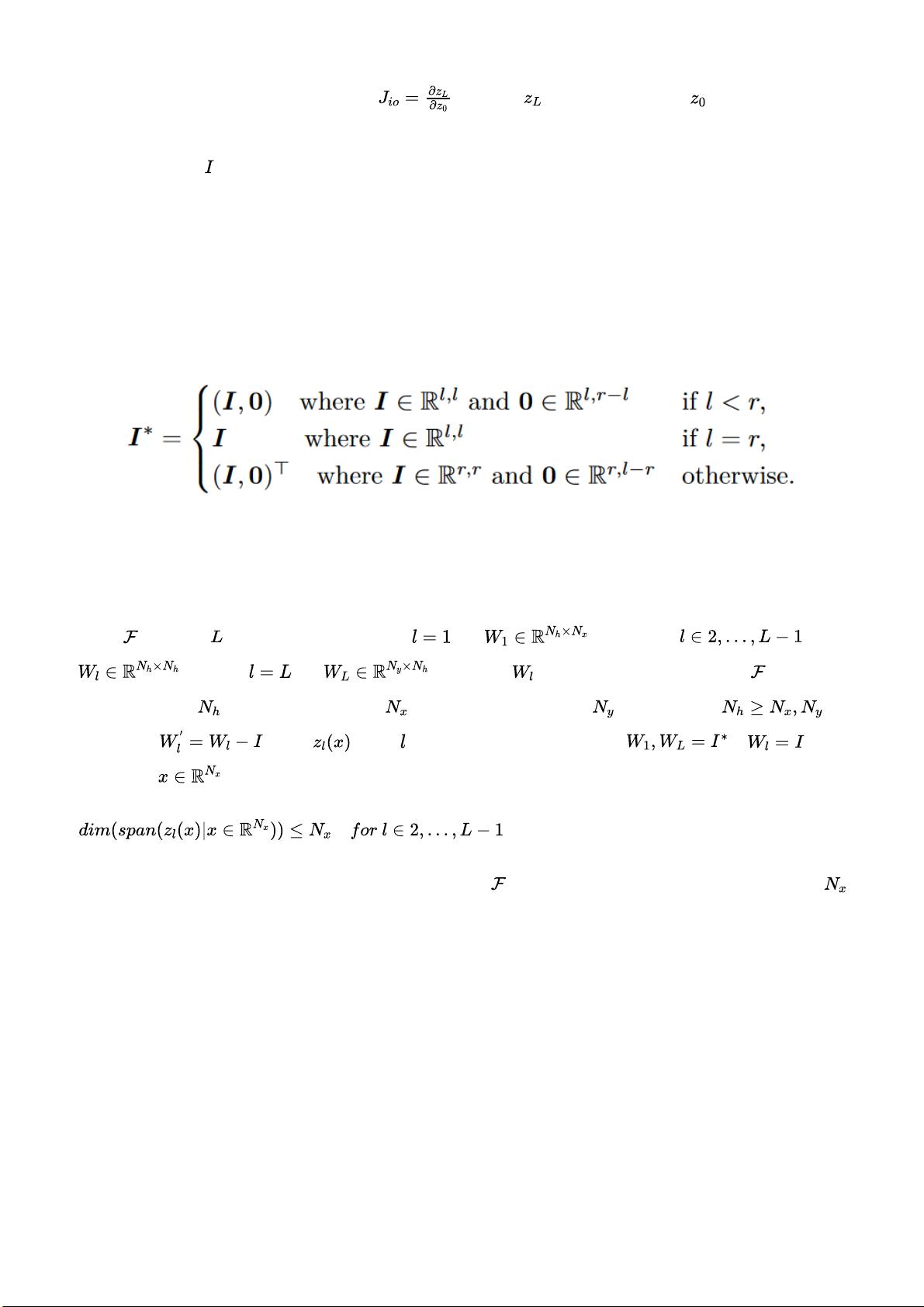
2023/6/28 16:44
忘掉Xavier初始化吧!最强初始化方法ZerO来了
https://mp.weixin.qq.com/s/jDyqQfdyRbJ81-Z24OyMYw
3/11
(Dynamical Isometry),最早由 Saxe 等人在2014年提出,它描述了当输入输出的雅可比矩阵
的奇 异值分 布 全部在 1 附 近时, 即 ( 这 里 表 示 输出向 量, 表 示 输入向 量)
时,神经 网络具 有稳 定的信 号传 播以及 梯度下 降的 行为, 可以 期待具 有良好 的训 练表现 。显
然,单位矩阵 天然的满足动力等距的条件,但是恒等初始化优美的理论推导却都建立在各
层 的 维 度 是 相 等 的 假设之上,但显然在实际中,这种假设有些过强使得它没法真正用于实际
工作之中。
从 恒 等 初 始 化 的 思 想 出 发 , 一 种 显 然 的 改 进 方 式 是 部 分 单 位 矩 阵 ( Partial Identity
Matrix) ,它的定义十分自然,对于行列中“超出”的部分补零即可:
然而,当使用部分单位矩阵在训练诸如 ResNet 等经典结构中时,往 往 将 会 出 现 一 种 所 谓 “训
练 衰 减 ( Training D egeneracy) ”的 现 象 ,这种现象可以做如下描述:
假设 是 一 个 层 的 神 经 网 络 , 对 于 有 , 而 对 于 , 有
,对于 有 。这里的 是神经网络的参数矩阵, 具有相同
的隐藏层维度 ,输入数据维度为 ,输出数据的维度为 ,此处假设 ,
定义余项 ,令 为第 层的激活函数,当初始化 , 时,
对于任意 ,将有:
这即表明,无 论 隐 藏 层 维 度 有 多 高 , 神 经 网 络 的 维 度 仅 仅 依 赖 于 输 入 数 据 的 维 度
, 从 而 极 大 的 限 制 了 神 经 网 络 的 表 达 能 力 。
剩余10页未读,继续阅读
2023-10-18 上传
2023-08-12 上传
2023-06-13 上传
2023-07-17 上传
2023-05-26 上传
2023-05-31 上传
2023-06-13 上传
2023-06-12 上传
2023-06-11 上传

地理探险家
- 粉丝: 1212
- 资源: 5516
 我的内容管理
展开
我的内容管理
展开







最新资源
- 解决Eclipse配置与导入Java工程常见问题
- 真空发生器:工作原理与抽吸性能分析
- 爱立信RBS6201开站流程详解
- 电脑开机声音解析:故障诊断指南
- JAVA实现贪吃蛇游戏
- 模糊神经网络实现与自学习能力探索
- PID型模糊神经网络控制器设计与学习算法
- 模糊神经网络在自适应PID控制器中的应用
- C++实现的学生成绩管理系统设计
- 802.1D STP 实现与优化:二层交换机中的生成树协议
- 解决Windows无法完成SD卡格式化的九种方法
- 软件测试方法:Beta与Alpha测试详解
- 软件测试周期详解:从需求分析到维护测试
- CMMI模型详解:软件企业能力提升的关键
- 移动Web开发框架选择:jQueryMobile、jQTouch、SenchaTouch对比
- Java程序设计试题与复习指南
