Hadoop:海量分布式存储与实战部署
需积分: 13 135 浏览量
更新于2024-07-18
收藏 945KB PDF 举报
Hadoop海量级分布式存储是一种针对大数据处理的开源软件框架,它最初由Apache Software Foundation在2005年推出,旨在模仿Google的MapReduce和Google File System (GFS) 技术。Hadoop的核心构成包括Hadoop Distributed File System (HDFS) 和MapReduce模型,这两个组件共同解决了大数据处理中的存储和计算问题。
一、Hadoop简介
大数据时代的概念强调了数据量巨大、增长速度快、类型多样且价值密度较低的特点,通常需要使用全量数据而非抽样分析来获取深入洞见。Hadoop的设计初衷就是为了解决这些大规模数据处理难题,它能够在廉价硬件上提供高度可靠性和可扩展性。Hadoop的项目起源于Nutch搜索引擎的子项目,并在随后独立发展,成为云计算基础设施服务的基石,尤其是用于搜索和数据分析。
二、Hadoop构成
1. **Hadoop Distributed File System (HDFS)**: HDFS是一个分布式文件系统,它将数据分布在网络上的多个节点上,以实现数据的高可用性和容错性。HDFS的设计目标是处理PB级别的数据,支持大量的小文件,同时提供高效的数据读写操作。通过将数据复制到多个节点,即使部分节点故障,数据仍可继续访问。
2. **MapReduce**: 这是Hadoop的核心计算模型,将复杂的计算任务分解为一系列简单的Map和Reduce操作。Map阶段将输入数据分成小块,对每个块执行自定义函数(Map函数),生成中间结果;Reduce阶段则将这些中间结果合并,生成最终结果。这种并行处理方式极大地提高了大数据处理的速度。
三、案例 - 部署Hadoop分布式存储集群
在实际应用中,部署Hadoop集群通常包括以下步骤:
- **硬件准备**:选择廉价的商业服务器或云计算资源,构建多节点的集群。
- **软件安装**:安装Hadoop发行版,如Hadoop 2.x或Hadoop 3.x,包含HDFS和MapReduce。
- **配置**:设置HDFS的名称节点和数据节点,以及MapReduce的JobTracker和TaskTracker。
- **数据分片和复制**:在HDFS中配置数据块的大小和副本数量,以提高数据冗余和可用性。
- **测试和调优**:通过运行测试工作负载来验证集群性能,根据需要调整参数以优化性能。
Hadoop的优点:
- **高可靠性**:通过数据冗余和自动故障恢复机制,确保数据安全。
- **高扩展性**:通过添加更多节点轻松扩展存储和处理能力,适应不断增长的数据需求。
- **成本效益**:利用廉价硬件,降低整体IT成本。
- **处理大规模数据**:无论是搜索索引还是实时分析,Hadoop都能应对复杂的大数据挑战。
总结,Hadoop作为一个强大的分布式存储和计算框架,对于现代企业处理海量数据至关重要,尤其在大数据时代的企业决策和业务流程优化中扮演着关键角色。通过理解Hadoop的构成和原理,企业可以更好地利用这个技术优势,驱动其数字化转型和创新。
资源由 www.eimhe.com 美河学习在线收集分享
大,而这些的元数据都会存放在 namenode 节点;
二、Hadoop 构成:HDFS+MapReduce:
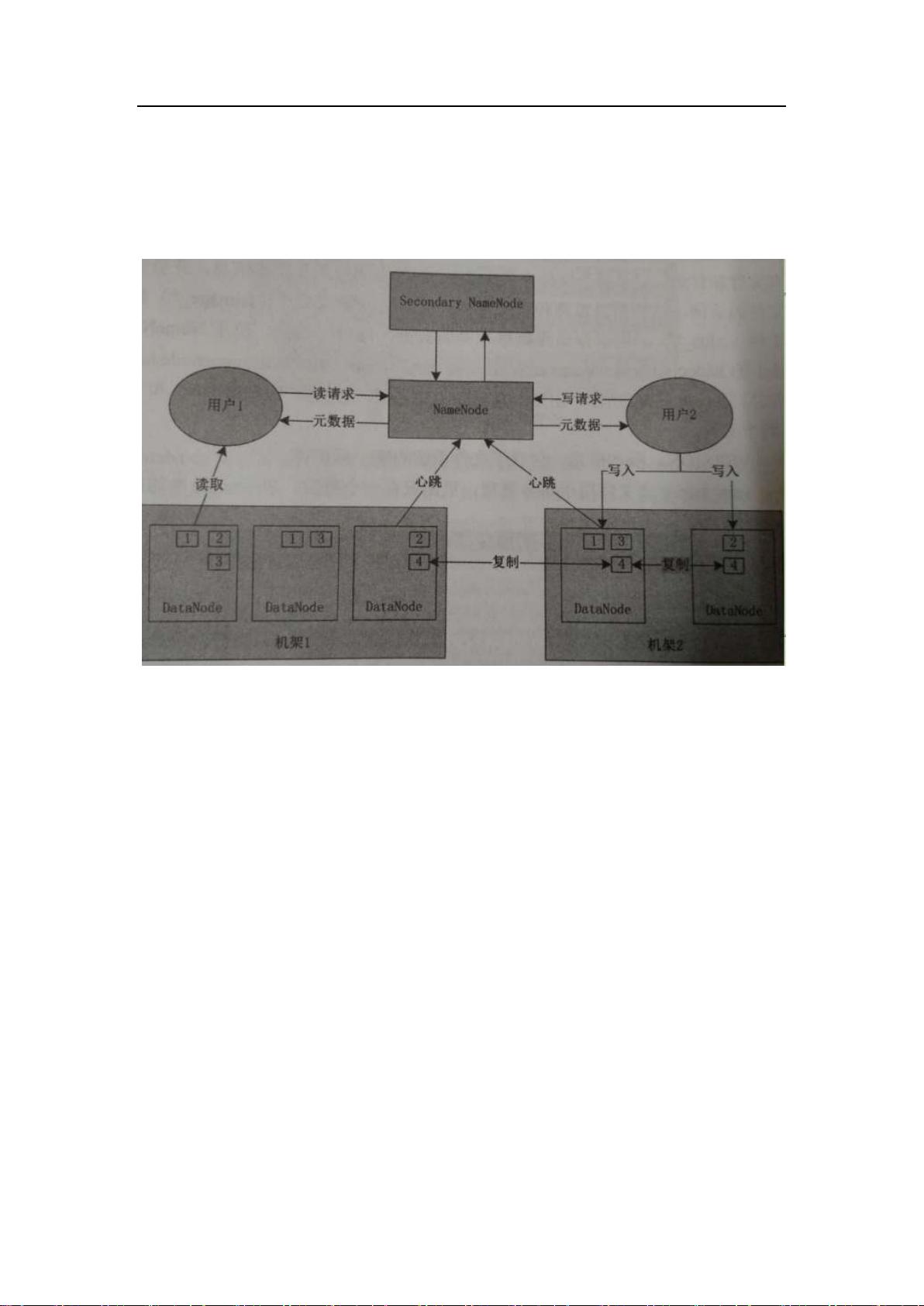
1.HDFS 引擎结构:
1)Hadoop Distributed File System(HDFS)引擎:包括 namenode(名称空间节点)和 datanode
(数据节点);
https://www.cnblogs.com/liango/p/7136448.html
基础概念:
1)文件块:Block,datanode 中存放数据最小逻辑单元,默认块大小为 64M,便于管理,不
受磁盘限制,数据可在 datanode的总 block中进行冗余备份,存储的副本数量要少于 datanode
节点的数量,当一个或多个块出现故障,用户可以直接去其他地方读取数据副本;
2)NameNode:管理文件系统的命名空间,属于管理者角色,维护文件系统树内所有文件
和目录,记录每个文件在各个 DataNode 上的位置和副本信息,并协调客户端对文件的访问;
3)DataNode:负责处理文件系统客户端的文件读写请求,存储并检索数据块,并定期向
NameNode 发送所存储的块的列表,属于工作者角色。负责所在物理节点的存储管理,按照
一次写入,多次读取的原则,存储文件按照 Block 块进行存储;
4)Secondary NameNode:相当于 NameNode 的快照,也称之为二级 NameNode,能够周期
性的备份 NameNode,记录 NameNode 上的元数据等。为防止 NameNode 进程出现故障,
起到备份作用;
2. MapReduce 引擎构成:
1)MapReduce 引擎:是用于并行处理计算大数据集的软件框架,是 HDFS(对于本文)的
上一层,与 hadoop 结合工作,将用户的任务分发到上千台商用机器组成的集群上。最简单
的 MapReduce 应用程序至少包含 2 个部分:一个 Map (映射)函数、一个 Reduce (归
纳)函数,Map 负责将任务分解成多个子任务,reduce 负责把分解后的多任务的处理结果
进行汇总;
JobTrackers :是一个 master 进程,用于作业的调度和管理工作,一个 Hadoop 集群中只有
剩余17页未读,继续阅读
2017-09-05 上传
2021-08-11 上传
2022-07-07 上传
2021-08-08 上传
2022-07-13 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

machen_smiling
- 粉丝: 509
- 资源: 1984
 我的内容管理
展开
我的内容管理
展开







最新资源
- 电子功用-有机电致发光二极管有机材料蒸镀用掩模装置
- 管理系统系列--在线项目管理系统-PHP编写的Web项目BUG管理系统.zip
- EnHome
- DSA_PRACTICE_PEP
- type-kana:一个测验应用程序,可帮助您学习日语的平假名和片假名
- ES6-Immutable-React:React 0.13 with ES6, Immutable.js 和 Flux, Isomorphic
- 以太网 web 智能家居demo板(原理图、PCB源文件、源码、文档)-电路方案
- 百度地图-导航 demo,以及性能测试
- M68K to i386-开源
- 管理系统系列--医院门诊管理系统.zip
- Python库 | imgtool-1.2.0.tar.gz
- 开源智能设备—真正的无线机械键盘,OLED显示屏-电路方案
- web50-projects-2020-x-0:项目0
- Day24
- 消灭JavaScript怪兽第三季ES6/7/8新特性(18-19)
- Android Google Maps网络地图程序源代码
