哈工大模式识别:无监督学习入门与应用
需积分: 25 47 浏览量
更新于2024-07-18
收藏 5.59MB PPT 举报
哈工大模式识别是一套深入讲解机器学习中两种关键方法——有监督学习和无监督学习的教育资源。针对初学者,它特别关注非监督学习的部分,这对于理解数据挖掘和模式识别的基础理论至关重要。
在课程的起始部分,通过"引言"章节,学生被引导进入机器学习的世界,区分了有监督学习和无监督学习的基本概念。有监督学习强调在已知类别标签的情况下,如通过训练样本计算概率分布或特征空间区域,目的是训练分类器以识别新的未知数据。这种方法需要明确的训练集和测试集,目标是将样本精确地分类。
相反,无监督学习则针对未标记的数据,目标是发现数据内在的结构和模式。例如,聚类(clustering)技术用于发现样本间的相似性,通过对数据集进行分组,可以揭示隐藏的信息,适用于诸如市场分析、土地使用分类、保险风险评估、城市规划、生物学分类甚至地震研究等领域。它更侧重于数据的组织和理解,而不是预设的标签匹配。
课程深入探讨了这两种方法的区别,有监督学习依赖于有标签的数据,它的目的是直接进行分类,而无监督学习则是在没有预先标签的情况下寻找数据内在规律,可能并不追求严格的类别划分,而是为了理解和探索数据的本质特征。举例来说,通过主成分分析(PCA)或Kullback-Leibler散度(KL变换)等技术,无监督学习能捕捉数据集的主要特征维度,从而为后续的数据分析提供基础。
哈工大的模式识别资源提供了一个全面且实践性强的学习框架,帮助学生建立起从数据驱动的角度理解和应用这两种核心的机器学习方法。无论是对学术研究还是实际项目开发,理解和掌握这些知识都是非常有益的。
11
直接
方法
1
argmin ( )
L
k
t
p k
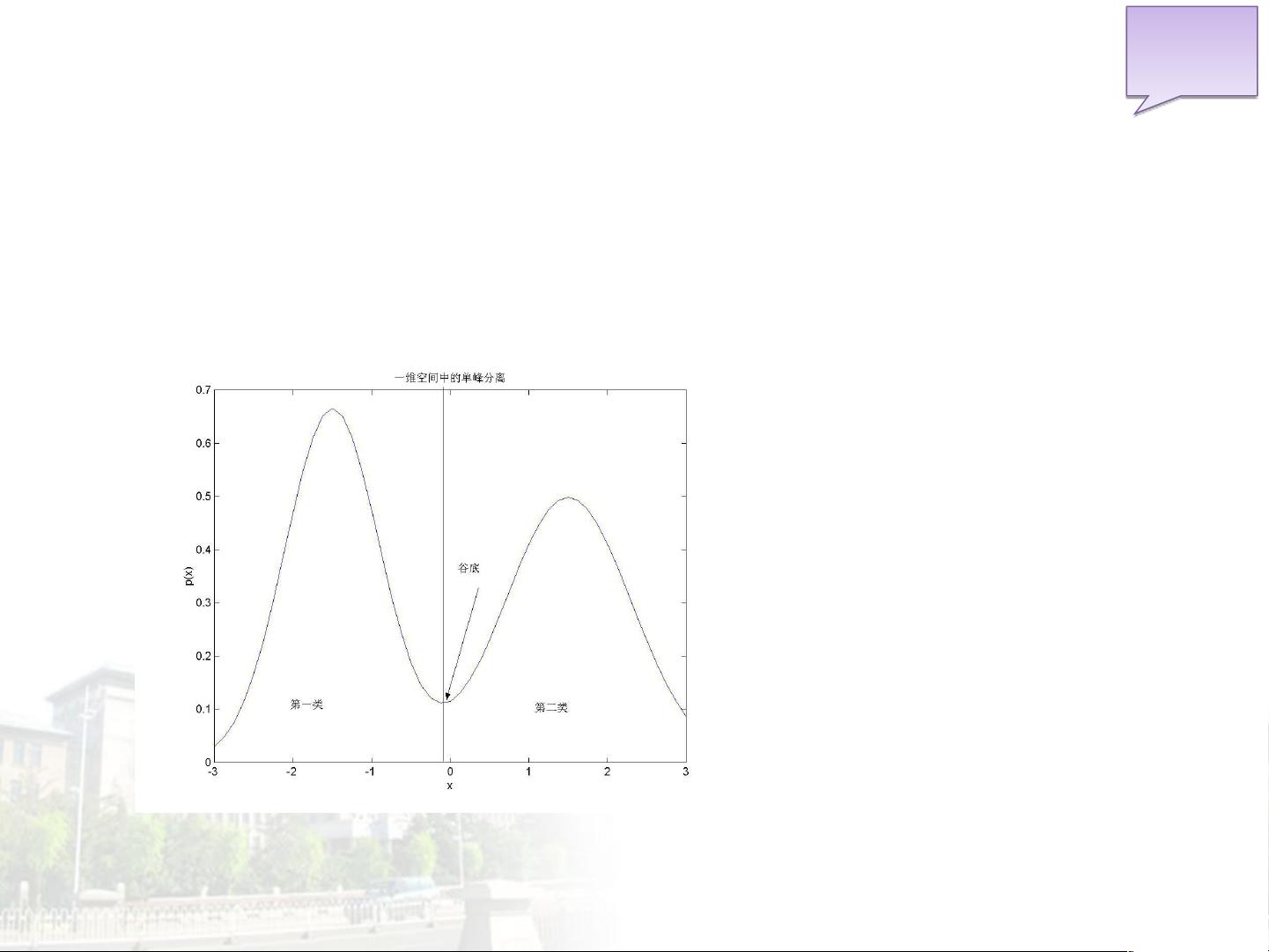
一维空间中的单峰分离 : 对样本集 KN={xi} 应用直
方图 /Parzen 窗方法估计概率密度函数,找到概率密度
函数的峰以及峰之间的谷底,以谷底为阈值对数据进行
分割。
【一维空间中的单峰子集分离】


剩余63页未读,继续阅读
2023-10-25 上传
2023-07-28 上传
2023-05-10 上传
2023-07-14 上传
2024-01-31 上传
2023-09-17 上传

wgm2001840
- 粉丝: 6
- 资源: 57
 我的内容管理
展开
我的内容管理
展开







最新资源
- Lombok 快速入门与注解详解
- SpringSecurity实战:声明式安全控制框架解析
- XML基础教程:从数据传输到存储解析
- Matlab实现图像空间平移与镜像变换示例
- Python流程控制与运算符详解
- Python基础:类型转换与循环语句
- 辰科CD-6024-4控制器说明书:LED亮度调节与触发功能解析
- AE particular插件全面解析:英汉对照与关键参数
- Shell脚本实践:创建tar包、字符串累加与简易运算器
- TMS320F28335:浮点处理器与ADC详解
- 互联网基础与结构解析:从ARPANET到多层次ISP
- Redhat系统中构建与Windows共享的Samba服务器实战
- microPython编程指南:从入门到实践
- 数据结构实验:顺序构建并遍历链表
- NVIDIA TX2系统安装与恢复指南
- C语言实现贪吃蛇游戏基础代码
