
𝐺𝑖𝑛𝑖
(
𝑦
)
=
―
𝐾
𝑘
=
1
𝑝
𝑘
(
1
―
𝑝
𝑘
)
=
1
―
𝐾
𝑘
=
1
𝑝
2
𝑘
在实际使用中经常采用经验基尼系数来进行估计:
𝐺𝑖𝑛𝑖
(
𝑦
)
=
𝐺𝑖𝑛𝑖
(
𝐷
)
=
1
―
𝐾
𝑘
=
1
(
𝐶
𝑘
)
(𝐷)
2
与信息熵类型,同样可以证明,当
𝑝
1
=
𝑝
2
=
…
𝑝
𝑘
=
1
𝐾
是,
𝐺𝑖𝑛𝑖(𝑦)
取得最大值
1
―
1
𝐾
;当存在
𝑘
∗
使得
𝑘
∗
=
1
、
𝐺𝑖𝑛𝑖
(
𝑦
)
=
0
。
这里再次以上述二分类为例子,即当
𝐾
=
2
时可以导出:
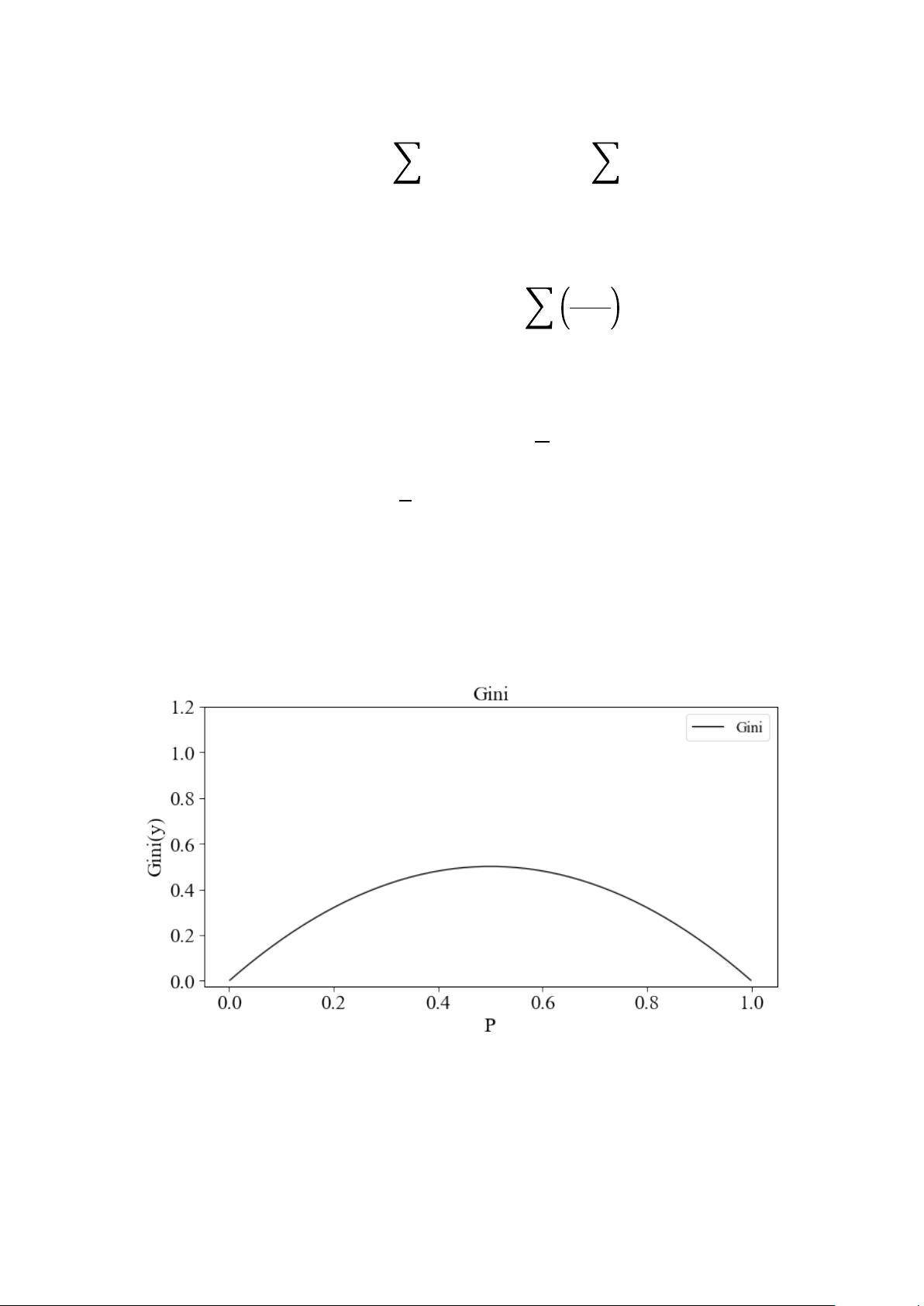
𝐺𝑖𝑛𝑖
(
𝑦
)
=
2𝑝
(
1
―
𝑝
)
此时
𝐺𝑖𝑛𝑖
(
𝑦
)
随
𝑝
变化的函数曲线如下图所示。
同理,基尼系数也可以作为信息的度量方法。
剩余20页未读,继续阅读

自在极意功登峰造极
- 粉丝: 586
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新型矿用本安直流稳压电源设计:双重保护电路
- 煤矿掘进工作面安全因素研究:结构方程模型
- 利用同位素位移探测原子内部新型力
- 钻锚机钻臂动力学仿真分析与优化
- 钻孔成像技术在巷道松动圈检测与支护设计中的应用
- 极化与非极化ep碰撞中J/ψ的Sivers与cos2φ效应:理论分析与COMPASS验证
- 新疆矿区1200m深孔钻探关键技术与实践
- 建筑行业事故预防:综合动态事故致因理论的应用
- 北斗卫星监测系统在电网塔形实时监控中的应用
- 煤层气羽状水平井数值模拟:交替隐式算法的应用
- 开放字符串T对偶与双空间坐标变换
- 煤矿瓦斯抽采半径测定新方法——瓦斯储量法
- 大倾角大采高工作面设备稳定与安全控制关键技术
- 超标违规背景下的热波动影响分析
- 中国煤矿选煤设计进展与挑战:历史、现状与未来发展
- 反演技术与RBF神经网络在移动机器人控制中的应用
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


