大数据技术入门:从Hadoop到HDFS解析
需积分: 9 57 浏览量
更新于2024-07-20
1
收藏 6.4MB PDF 举报
"大数据技术,包括Hadoop和Spark,适合初学者学习,涵盖了大数据平台架构、Hadoop的HDFS和MapReduce,以及大数据的4V特征。"
大数据技术是当前信息技术领域的重要组成部分,它主要涉及如何处理和分析海量的数据,以挖掘其中的价值。大数据的特点可以用4V来概括:Volume(大量)、Velocity(高速)、Variety(多样)和Value(价值)。这些数据可能来自各种源头,包括结构化、半结构化和非结构化的数据,如日志、图像、视频等。
Hadoop是大数据处理的关键技术之一,它是一个开源框架,旨在支持分布式存储和计算。Hadoop的核心设计包括两个主要组件:Hadoop Distributed File System(HDFS)和MapReduce。HDFS是一个高容错性的文件系统,它将大文件分布在多个节点上,确保数据的可靠性和可用性。当客户端需要读取文件时,首先向NameNode(HDFS的主节点)请求文件位置,NameNode返回文件所在DataNode的信息,然后客户端直接从DataNode读取数据。在写入文件时,NameNode会根据文件大小和配置策略决定数据块的分布,确保数据的安全和高效读写。
MapReduce是Hadoop中的计算模型,它将复杂的大规模数据处理任务分解为map和reduce两个阶段。map阶段将数据分片并分配到各个节点进行并行处理,而reduce阶段则负责汇总各个节点的结果,完成数据聚合。这种模型使得大规模数据的处理变得简单且高效。
Spark是另一个大数据处理框架,相比Hadoop更注重速度和易用性。Spark提供了内存计算功能,可以将中间结果缓存在内存中,大大减少了I/O操作,从而提高了处理速度。同时,Spark提供了丰富的API,支持多种编程语言,使得开发人员能更便捷地构建大数据应用。
在实际应用中,例如腾讯公司的大数据平台,可能会结合Hadoop和Spark等技术,构建出能够处理大量非结构化数据的架构,用于用户行为分析、推荐系统、实时监控等多种业务场景。通过这样的平台,公司能够从海量数据中获取洞察,优化业务决策,提升服务质量。
学习大数据技术,尤其是Hadoop和Spark,对于初学者来说是进入这个领域的良好起点。它们不仅提供了处理大数据的基础工具,还帮助理解大数据处理的原理和流程,为进一步深入研究大数据分析、机器学习等领域奠定了基础。
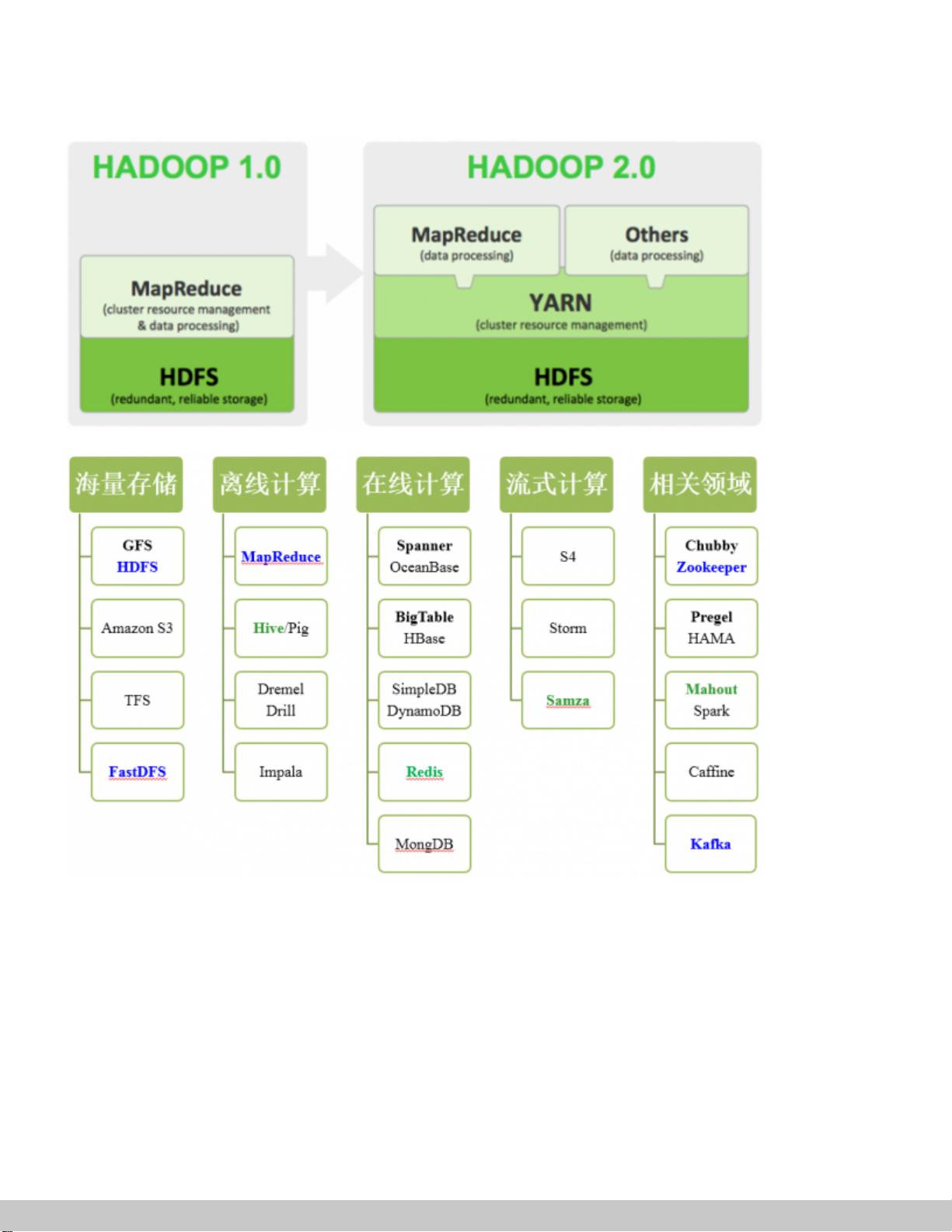
MapReduce:
JobTracker:协调作业的运行。
TaskTracker:运行作业划分后的任务。
大数据的技术领域
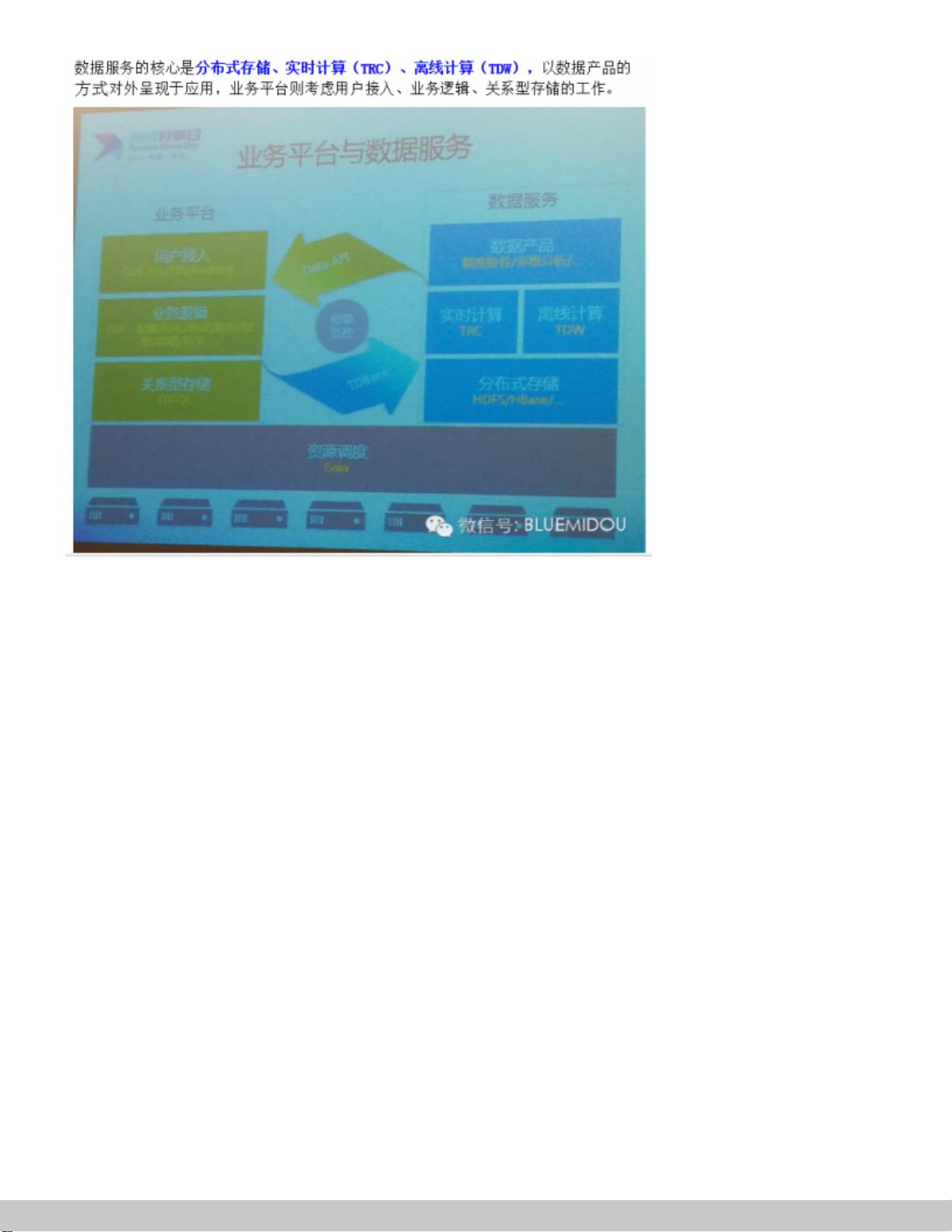
腾讯大数据现状(资料来自2014.4.11 腾讯分享日大会)
深入浅出解析大数据平台架构
第 11 页 /共
66 页


剩余65页未读,继续阅读
2020-03-06 上传
2016-09-28 上传
2023-12-07 上传
2023-06-03 上传
2023-07-13 上传
2024-01-22 上传
2024-01-21 上传
2023-06-08 上传

北极象
- 粉丝: 1w+
- 资源: 377
 我的内容管理
展开
我的内容管理
展开







最新资源
- 多模态联合稀疏表示在视频目标跟踪中的应用
- Kubernetes资源管控与Gardener开源软件实践解析
- MPI集群监控与负载平衡策略
- 自动化PHP安全漏洞检测:静态代码分析与数据流方法
- 青苔数据CEO程永:技术生态与阿里云开放创新
- 制造业转型: HyperX引领企业上云策略
- 赵维五分享:航空工业电子采购上云实战与运维策略
- 单片机控制的LED点阵显示屏设计及其实现
- 驻云科技李俊涛:AI驱动的云上服务新趋势与挑战
- 6LoWPAN物联网边界路由器:设计与实现
- 猩便利工程师仲小玉:Terraform云资源管理最佳实践与团队协作
- 类差分度改进的互信息特征选择提升文本分类性能
- VERITAS与阿里云合作的混合云转型与数据保护方案
- 云制造中的生产线仿真模型设计与虚拟化研究
- 汪洋在PostgresChina2018分享:高可用 PostgreSQL 工具与架构设计
- 2018 PostgresChina大会:阿里云时空引擎Ganos在PostgreSQL中的创新应用与多模型存储
