Python多进程编程详解:突破GIL限制,利用多核CPU
58 浏览量
更新于2024-08-30
收藏 118KB PDF 举报
"深入理解Python多进程编程,利用多核CPU资源,克服GIL限制,实现高效并发执行。Python的多进程编程与多线程类似,但数据不共享,需通过特殊结构交换信息。核心概念包括Process类,以及如何创建、启动和管理进程。"
在Python编程中,多进程是一种重要的并发执行方式,尤其在处理多核CPU资源时,能够有效提高程序的执行效率。Python的多线程由于全局解释器锁(GIL)的存在,无法充分利用多核优势,因此多进程成为了实现并行计算的选择。多进程编程允许每个进程独立地运行在各自的内存空间,互不影响,这样可以避免线程间的竞态条件和同步问题。
Python提供了`multiprocessing`模块来支持多进程编程。在该模块中,有一个关键的类——`Process`,它类似于`threading`模块中的`Thread`类。通过`Process`类,我们可以创建进程对象,并指定要执行的函数(target)和参数(args)。以下是一个简单的`Process`类使用示例:
```python
from multiprocessing import Process
import os
import time
def func(name):
print('Start a process')
time.sleep(3)
print('The process parent id:', os.getppid())
print('The process id:', os.getpid())
if __name__ == '__main__':
processes = []
for i in range(2):
p = Process(target=func, args=(i,))
processes.append(p)
for i in processes:
i.start() # 启动进程
print('Start all processes')
for i in processes:
i.join() # 等待进程结束
print('All subprocesses are done!')
```
在这个例子中,我们创建了两个进程,每个进程都会调用`func`函数。`start`方法用于启动进程,而`join`方法则用于等待进程执行完成。值得注意的是,`__name__ == '__main__'`判断确保了只有在直接运行脚本时才会执行多进程代码,避免了作为模块导入时意外创建进程。
在多进程环境下,进程间的数据共享不同于多线程。由于进程间的内存是隔离的,直接的数据共享是不可行的。若需要数据交换,可以通过以下几种方式:
1. **管道(Pipe)**:提供单向或双向的数据通信,可以将数据从一个进程传递到另一个进程。
2. **队列(Queue)**:多进程安全的共享数据结构,支持先进先出(FIFO)的队列操作,适合于任务分发和结果收集。
3. **共享内存**:通过映射同一块内存区域,进程间可以直接访问共享数据,但需要额外的同步机制如锁来确保数据一致性。
4. **信号量(Semaphore)**:用于控制对共享资源的访问权限,防止多个进程同时访问导致的问题。
5. **文件**:通过读写磁盘文件进行进程间通信,简单易用,但效率较低。
了解这些基本概念后,开发者可以根据实际需求选择合适的进程间通信(IPC)机制,设计出高效的多进程应用。在处理大量计算任务、大数据分析或I/O密集型任务时,Python的多进程编程能力能显著提升程序性能。
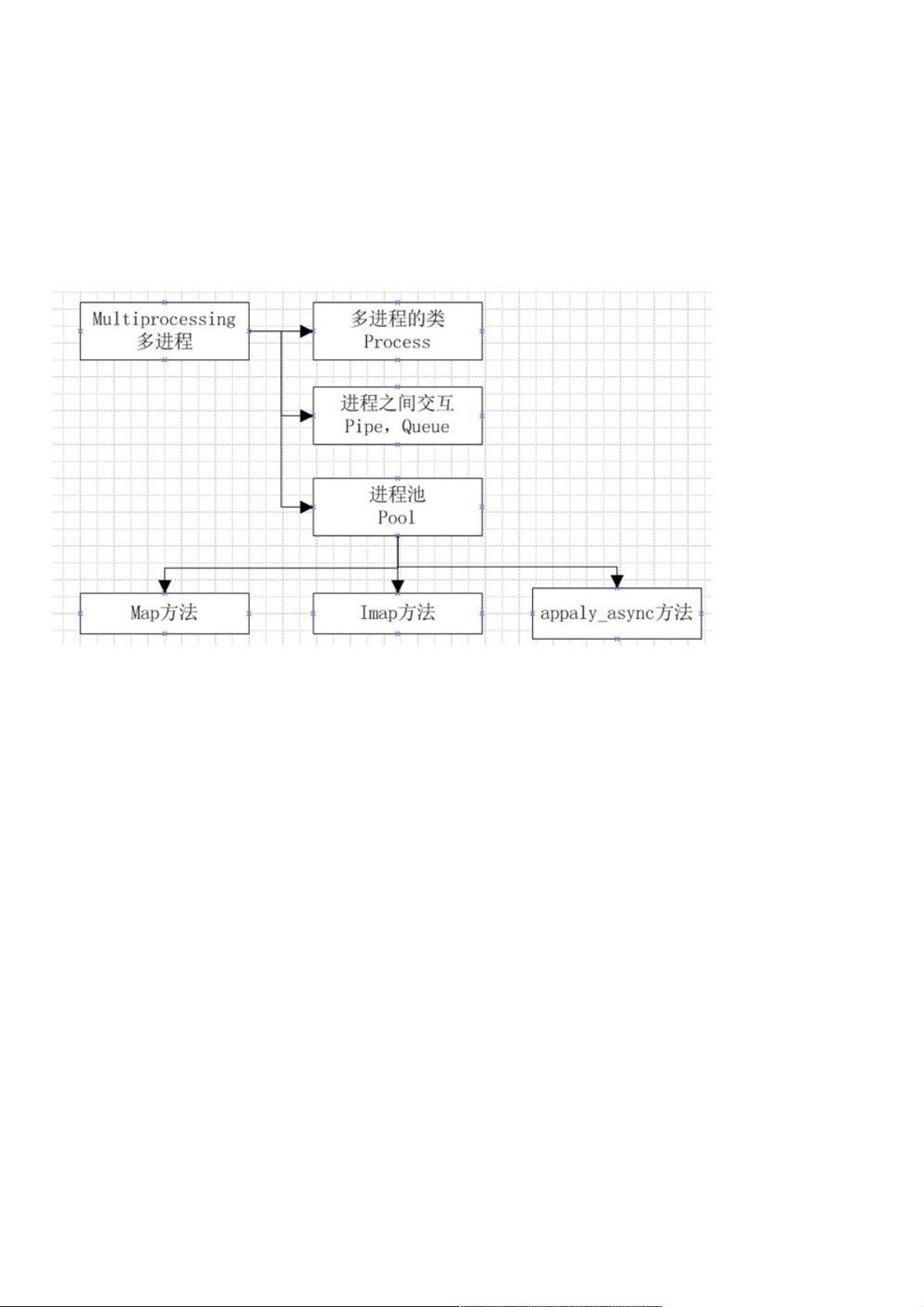
深入理解深入理解python多进程编程多进程编程
1、、python多进程编程背景多进程编程背景
python中的多进程最大的好处就是充分利用多核cpu的资源,不像python中的多线程,受制于GIL的限制,从而只能进行cpu分
配,在python的多进程中,适合于所有的场合,基本上能用多线程的,那么基本上就能用多进程。
在进行多进程编程的时候,其实和多线程差不多,在多线程的包threading中,存在一个线程类Thread,在其中有三种方法来
创建一个线程,启动线程,其实在多进程编程中,存在一个进程类Process,也可以使用那集中方法来使用;在多线程中,内
存中的数据是可以直接共享的,例如list等,但是在多进程中,内存数据是不能共享的,从而需要用单独的数据结构来处理共
享的数据;在多线程中,数据共享,要保证数据的正确性,从而必须要有所,但是在多进程中,锁的考虑应该很少,因为进程
是不共享内存信息的,进程之间的交互数据必须要通过特殊的数据结构,在多进程中,主要的内容如下图:
2、多进程的类、多进程的类Process
多进程的类Process和多线程的类Thread差不多的方法,两者的接口基本相同,具体看以下的代码:
#!/usr/bin/env python
from multiprocessing import Process
import os
import time
def func(name):
print 'start a process'
time.sleep(3)
print 'the process parent id :',os.getppid()
print 'the process id is :',os.getpid()
if __name__ =='__main__':
processes = [] for i in range(2):
p = Process(target=func,args=(i,))
processes.append(p)
for i in processes:
i.start()
print 'start all process'
for i in processes:
i.join()
#pass
print 'all sub process is done!'
在上面例子中可以看到,多进程和多线程的API接口是一样一样的,显示创建进程,然后进行start开始运行,然后join等待进
程结束。
在需要执行的函数中,打印出了进程的id和pid,从而可以看到父进程和子进程的id号,在linu中,进程主要是使用fork出来
的,在创建进程的时候可以查询到父进程和子进程的id号,而在多线程中是无法找到线程的id,执行效果如下:
下载后可阅读完整内容,剩余4页未读,立即下载
2018-03-24 上传
2024-11-24 上传
2023-06-12 上传
2020-09-17 上传
2022-08-04 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38733333
- 粉丝: 4
- 资源: 922
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机控制系统 - pdf课件 - 第四章
- 计算机控制系统 - pdf 课件 - 第三章
- LVS手册,负载均衡的常用工具手册
- 计算机控制系统 - pdf 课件 - 第二章
- 计算机控制系统 - pdf课件 - 第一章
- 黑莓8100帮助文件
- cathedral_RL_v1.1.pdf
- Qt 嵌入式图形开发(入门篇)
- 音频 水印 学习 5656
- Qt编程初步(PDF格式)
- 南开出版的全国计算机二级C的习题
- <Adam品质保证>[原版][中文][官方手册]STC12C5A60S2(STC-51系列单片机)
- 常用SQL语句--全面
- 稳压电源基础 PDF
- wsbpel-v2.0
- TMS320DM642中文手册
