边缘计算优化链路追踪:按需存储,降低成本
需积分: 0 4 浏览量
更新于2024-08-05
收藏 2.79MB PDF 举报
"链路追踪(Tracing)其实很简单——全量存储?No!按需存储?YES!"
在IT行业中,链路追踪(Tracing)是一种关键的监控和故障诊断技术,它记录了服务间的调用关系和请求流转的详细信息。然而,全量存储链路追踪数据会带来高昂的成本和性能问题。本文作者夏明(涯海海)通过讨论边缘计算和冷热数据分离策略,提出了更有效的链路追踪解决方案。
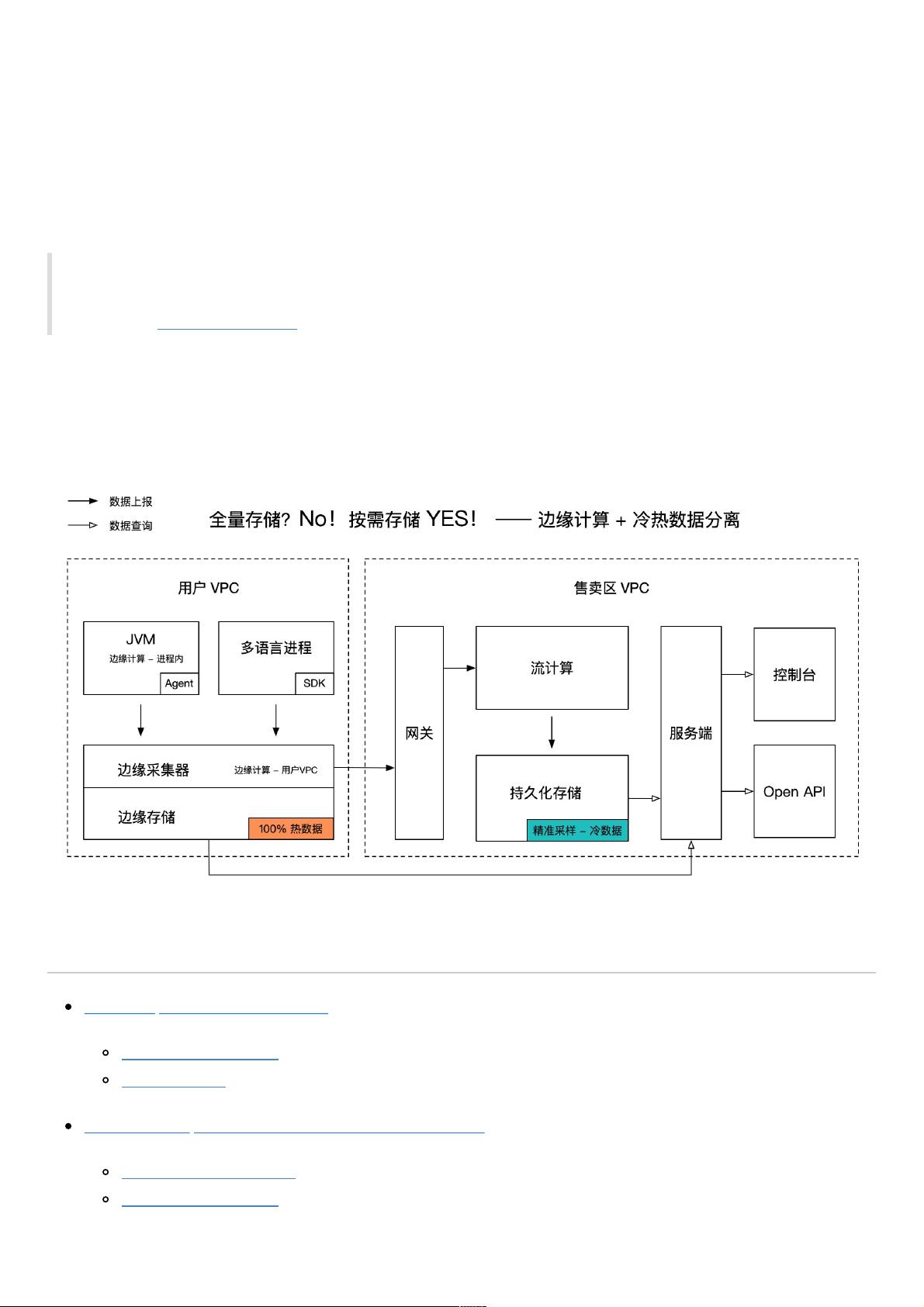
边缘计算在Tracing中的应用主要体现在对用户进程内的数据进行过滤和分析,尤其在公有云环境中,可以避免大量的公网传输开销,减轻全局数据处理的压力。这种计算方式能够在数据源头筛选出有价值的信息,同时通过加工提升数据的附加值,以较低的成本存储最关键的数据。
链路数据的价值分布具有高度的不均匀性,大部分数据可能并不需要被频繁查询。因此,采用采样策略成为降低成本的有效手段。常见的采样策略包括基于数据特征的调用链采样(如错误或慢调用全采,每秒前N次采样等)和在异常场景下自动保留关联数据,以支持问题的快速定位和解决。
文章提到了阿里云ARMS的自定义采样配置页面,用户可以根据业务需求定制存储策略,这通常能使实际存储成本降低至原始数据的5%以下。这种按需存储的方式既能满足分析需求,又降低了存储成本。
冷热数据分离是另一种优化策略,它将数据分为高频访问的热数据和低频访问的冷数据。热数据通常进行实时全量分析,以满足快速响应和决策的需求;而冷数据则进行持久化存储和定期采样分析,以支持后期的深度挖掘和历史数据分析。这样的分离方式使得系统能够以低成本满足个性化的后聚合分析需求。
文章虽然没有深入探讨具体的实现细节,但这些概念和策略为读者提供了一个理解如何在链路追踪中实施成本效益分析和优化的框架。对于面临链路追踪存储成本过高或者采样后查询不准确问题的IT从业者,这篇文章提供了宝贵的思考方向。
结语部分并未给出,但从文章内容来看,作者可能强调了采用边缘计算和冷热数据分离策略对于优化链路追踪系统的有效性,并鼓励读者根据自身的业务场景灵活应用这些方法,以实现更高效且经济的链路追踪解决方案。文章最后可能还邀请读者加入相关的社区或讨论,共同探讨和学习这些技术的应用。
作者:夏明(涯)
创作期:2021-05-18
专栏地址:【稳定于切】
调链记录完整的请求状态及流转信息,是座巨的数据宝库。但是,其庞的数据带来的成本及性
能问题是每个实际应 Tracing 同学绕开的难题。如何以最低的成本,按需记录最有价值的链及其关联
数据,是本探讨的主要话题。 核关键词是:边缘计算 + 冷热数据分离。 如果你正临全存储调链
成本过,采样后查到数据或图表准等问题,请耐读完本,相信会给你带来些启发。
边缘计算,记录有价值的数据
筛选有价值的数据
提炼数据价值
冷热数据分离,低成本满个性化的后聚合分析需求
冷热数据分离案简述
热数据实时全分析
链追踪(Tracing)其实很简单——全存储? No!
按需存储?YES!
录
下载后可阅读完整内容,剩余6页未读,立即下载
2022-08-03 上传
2023-02-17 上传
2023-03-28 上传
2024-06-18 上传
2023-09-03 上传
2023-09-27 上传
2023-02-15 上传
2023-03-30 上传

白羊带你成长
- 粉丝: 25
- 资源: 328
 我的内容管理
展开
我的内容管理
展开







最新资源
- 解决Eclipse配置与导入Java工程常见问题
- 真空发生器:工作原理与抽吸性能分析
- 爱立信RBS6201开站流程详解
- 电脑开机声音解析:故障诊断指南
- JAVA实现贪吃蛇游戏
- 模糊神经网络实现与自学习能力探索
- PID型模糊神经网络控制器设计与学习算法
- 模糊神经网络在自适应PID控制器中的应用
- C++实现的学生成绩管理系统设计
- 802.1D STP 实现与优化:二层交换机中的生成树协议
- 解决Windows无法完成SD卡格式化的九种方法
- 软件测试方法:Beta与Alpha测试详解
- 软件测试周期详解:从需求分析到维护测试
- CMMI模型详解:软件企业能力提升的关键
- 移动Web开发框架选择:jQueryMobile、jQTouch、SenchaTouch对比
- Java程序设计试题与复习指南
