SQL执行顺序详解:从基础到聚合函数应用
需积分: 0 115 浏览量
更新于2024-08-03
收藏 488KB PDF 举报
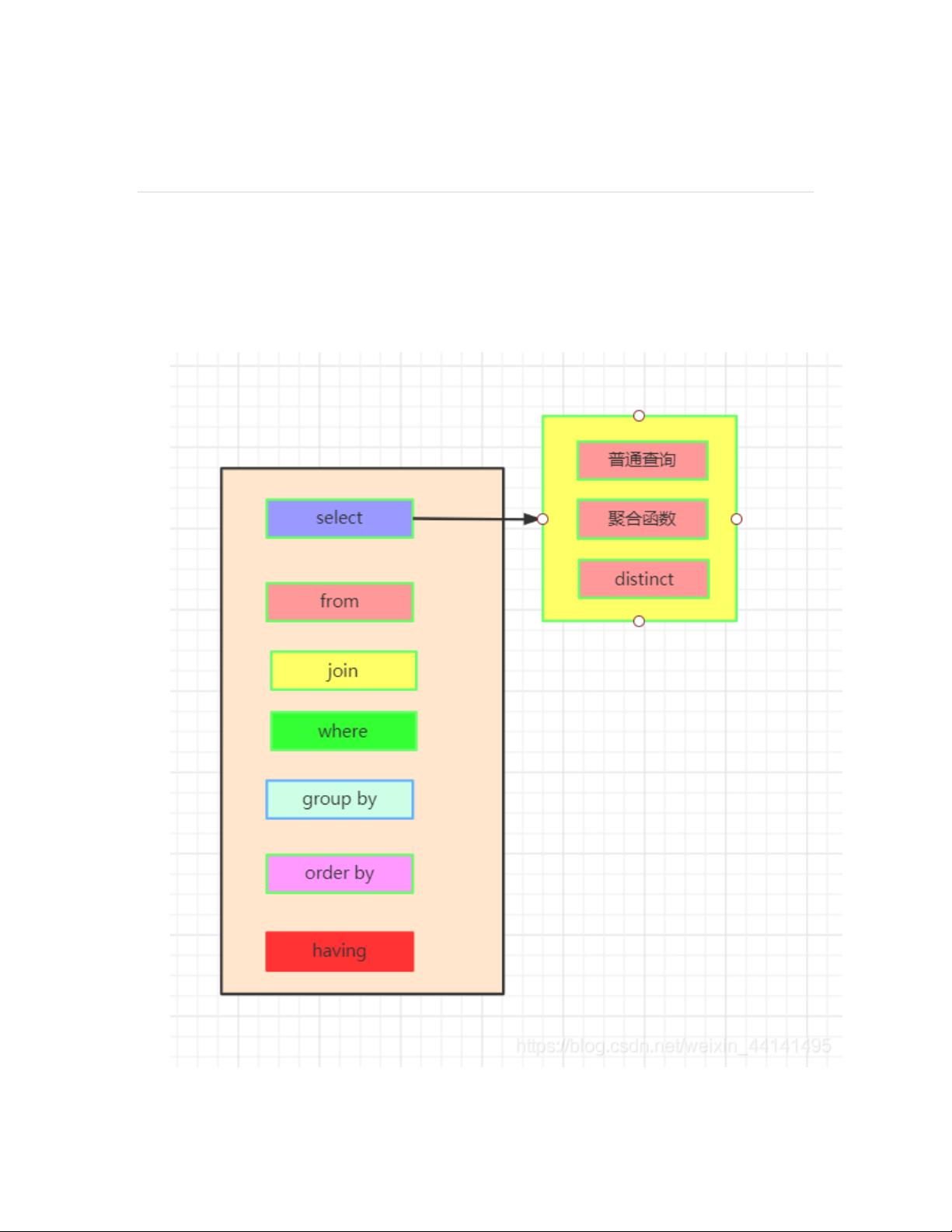
本文档深入解析了SQL执行顺序及其在处理数据时的关键步骤。首先,当面对一个标准查询时,SQL执行的基本顺序如下:
1. **FROM & JOIN**:执行从(FROM)和连接(JOIN)语句,确定表之间的连接关系,建立初步数据集。这包括单表查询(如`from table1`)和多表连接(如`from table1 jointable2 on table1.id=table2.id`),以明确查询范围。
2. **WHERE**:应用过滤条件,对初步数据进行初步筛选,只保留符合特定条件的记录,避免笛卡尔积(不加关联条件时,两表的所有组合)。
3. **GROUP BY**:按指定的列或表达式对数据进行分组,但并不执行筛选,只是为后续操作准备数据结构。
4. **HAVING**:对分组后的数据进行筛选,允许使用普通条件和聚合函数。相比于WHERE,HAVING可以在分组后应用条件,且支持聚合函数,这是WHERE所不能实现的高级特性。
5. **SELECT**:选择所需字段,可能是基础字段、聚合函数的结果,甚至是使用聚合函数生成的新字段。对于分组查询,可能会出现新字段以表示每个组的统计信息。
6. **DISTINCT**:去重操作,确保返回的结果中没有重复的行。
7. **ORDER BY**:根据指定的列对查询结果进行排序。
8. **数据关联过程**:在处理多个表时,通过JOIN操作关联数据,确保查询结果只包含满足关联条件的行。
9. **where vs having**:WHERE在数据筛选之前执行,而HAVING则针对已经分组的数据进行筛选。虽然二者都能实现基本条件筛选,但在分组后使用HAVING可以利用聚合函数实现更复杂的条件。
10. **示例说明**:通过实例说明,即使在分组后,只要筛选条件不变,WHERE和GROUP BY(再having)的操作顺序变化对结果的影响微乎其微,关键在于筛选条件的适用性。
理解这些步骤对于编写高效、准确的SQL查询至关重要,特别是当处理大量数据或复杂业务逻辑时,正确的执行顺序能够优化查询性能并确保结果的准确性。
下载后可阅读完整内容,剩余9页未读,立即下载
2020-05-28 上传
2021-09-03 上传
2023-08-24 上传
2024-07-20 上传
2023-08-30 上传
2024-07-31 上传
2023-06-07 上传
2024-04-19 上传

毕业小助手
- 粉丝: 2737
- 资源: 5598
 我的内容管理
展开
我的内容管理
展开







最新资源
- Hadoop生态系统与MapReduce详解
- MDS系列三相整流桥模块技术规格与特性
- MFC编程:指针与句柄获取全面解析
- LM06:多模4G高速数据模块,支持GSM至TD-LTE
- 使用Gradle与Nexus构建私有仓库
- JAVA编程规范指南:命名规则与文件样式
- EMC VNX5500 存储系统日常维护指南
- 大数据驱动的互联网用户体验深度管理策略
- 改进型Booth算法:32位浮点阵列乘法器的高速设计与算法比较
- H3CNE网络认证重点知识整理
- Linux环境下MongoDB的详细安装教程
- 压缩文法的等价变换与多余规则删除
- BRMS入门指南:JBOSS安装与基础操作详解
- Win7环境下Android开发环境配置全攻略
- SHT10 C语言程序与LCD1602显示实例及精度校准
- 反垃圾邮件技术:现状与前景
