K-Means聚类算法详解:原理、优缺点及应用
版权申诉
170 浏览量
更新于2024-06-26
收藏 1.14MB PDF 举报
本文档主要总结了k-means聚类算法(K-Means Clustering Algorithm)的相关知识。k-means是一种迭代的、基于密度的无监督学习方法,其目标是将数据集划分为K个簇,使得同一簇内的数据点彼此相似,而不同簇的数据点之间差异较大。算法的基本步骤如下:
1. **定义与原理**:
- k-means通过随机选择K个初始聚类中心,然后逐次将每个数据点分配到与其距离最近的中心,更新中心点为新加入的数据点的均值,直到达到终止条件(如停止改变簇分配或中心点不再移动)。
2. **算法流程**:
- 初始化阶段:随机选取K个样本作为聚类中心。
- 分配阶段:计算每个数据点与中心的距离,将其归入最近的簇。
- 更新阶段:根据簇内数据点重新计算中心点。
- 重复上述过程,直到达到收敛。
3. **特点与优缺点**:
- 优点:易于理解和实现,对于小规模数据集有很好的效果。
- 缺点:容易陷入局部最优,对初始聚类中心的选择敏感,对大规模数据集的处理效率低,且对异常值不敏感。
4. **实现细节**:
- 簇中心的初始化通常是随机的,随着算法迭代,如果发现某点归属改变,就需要重新计算中心点。
- 通常采用迭代法,直到所有数据点的归属不再改变或满足预设的迭代次数。
5. **总结与讨论**:
- 虽然k-means算法简便,但它依赖于随机性和初始条件,可能导致不同的运行结果。此外,对于非凸形状的簇,k-means可能无法捕捉到复杂的结构。因此,选择合适的K值和改进算法(如DBSCAN、谱聚类等)以适应不同场景是必要的。
k-means聚类算法是数据挖掘和机器学习领域常用的基本工具,对于数据的初步分群和理解数据分布有重要作用,但在实际应用中需结合其他方法以提高性能和稳定性。
d
j
i1
d
W
ji
2
x
i
7
)
其中,
j
是神经元
j
的权重与输入
X
之间的距离,最小距离的神经元是胜者。
第二步,调整获胜神经元及其邻域神经元的权重, 以确保如果下一次是相同的输入, 则胜者
确定哪些邻域神经元权重需要修改,通常使用
还是同一个神经元。网络采用邻域函数
高斯墨西哥帽函数作为邻域函数,数学表达式如下:
r
d
2
e 2
2
8
)
其中,
σ
是随时间变化的神经元影响半径,
d
是距离获胜神经元的距离。 邻域函数的一个重 要特性是它的
半径随时间而减小, 这样刚开始时较多邻域神经元权重被修改, 但是随着网络 的学习,最终只有少量的神
经元的权重被修改 (有时只有一个或没有) 。权重的改变由下式 计算:
dW X W
按照这个方法继续处理输入, 重复执行给定的迭代次数。 在迭代过程中利用一个与迭代次数 相关
的因子来减少学习率和影响半径。
9
)
8.
分类算法
8.1.k-NN
(
k
近邻)
8.1.1 K-NN
算法的概念
K
近邻算法,即是给定一个训练数据集, 对新的输入实例,在训练数据集中找到与该实 例最邻近的
K
个实例,这
K
个实例的多数属于某个类,就把该输入实例分类到这个类中。 这就类似于现实生活中少数服
从多数的思想。
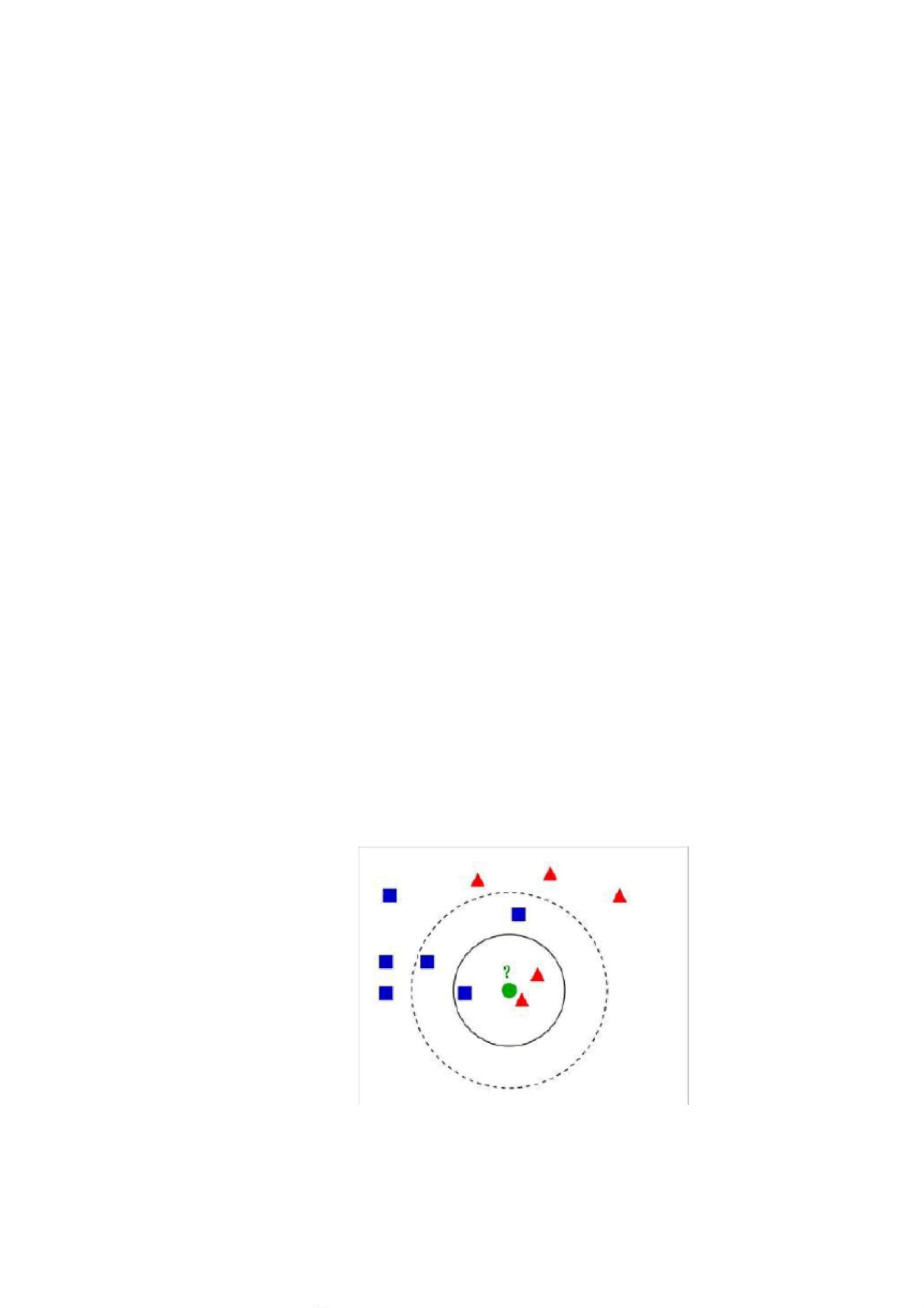
下面通过一个简单的例子说明一下:如下图,
图
8-1
样本数据图
剩余22页未读,继续阅读
2024-02-05 上传
2023-12-16 上传
2023-08-07 上传
2023-09-10 上传
2023-08-16 上传
2023-12-18 上传

若♡
- 粉丝: 6286
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 多模态联合稀疏表示在视频目标跟踪中的应用
- Kubernetes资源管控与Gardener开源软件实践解析
- MPI集群监控与负载平衡策略
- 自动化PHP安全漏洞检测:静态代码分析与数据流方法
- 青苔数据CEO程永:技术生态与阿里云开放创新
- 制造业转型: HyperX引领企业上云策略
- 赵维五分享:航空工业电子采购上云实战与运维策略
- 单片机控制的LED点阵显示屏设计及其实现
- 驻云科技李俊涛:AI驱动的云上服务新趋势与挑战
- 6LoWPAN物联网边界路由器:设计与实现
- 猩便利工程师仲小玉:Terraform云资源管理最佳实践与团队协作
- 类差分度改进的互信息特征选择提升文本分类性能
- VERITAS与阿里云合作的混合云转型与数据保护方案
- 云制造中的生产线仿真模型设计与虚拟化研究
- 汪洋在PostgresChina2018分享:高可用 PostgreSQL 工具与架构设计
- 2018 PostgresChina大会:阿里云时空引擎Ganos在PostgreSQL中的创新应用与多模型存储
