MapReduce实战:邮件自动分类与特征工程
需积分: 0 33 浏览量
更新于2024-08-05
2
收藏 512KB PDF 举报
在这个MapReduce课程设计中,主要目标是利用Hadoop框架实现邮件的自动分类,通过实践来理解和掌握MapReduce编程在大数据处理中的应用。以下是该课程设计的关键知识点:
1. **Hadoop与第三方Jar包**:
在Hadoop环境下,课程要求学生使用第三方的Jar包作为工具,这可能包括一些数据分析或文本处理库,如Apache Mahout或NLTK (Natural Language Toolkit),以辅助邮件处理和特征提取。学生需要了解如何集成这些库,并确保其与MapReduce作业的交互顺畅。
2. **MapReduce算法设计**:
- **文本特征选择算法**:学生需设计一个算法来从邮件文本中挑选出关键特征词,去除无关的停用词,例如数字和标点符号,这有助于提高分类精度。
- **文本特征权重计算**:基于特征选择后的词频或TF-IDF(Term Frequency-Inverse Document Frequency)等方法,计算每个特征词在邮件中的重要性权重。
- **文本分类算法**:课程要求学生至少使用两种常见的文本分类算法,如朴素贝叶斯、支持向量机(SVM)、决策树或神经网络等,进行邮件分类模型的构建和比较。
3. **邮件自动分类流程**:
- **任务1:特征选择** - 邮件预处理步骤,包括分词和特征提取。
- **任务2:特征向量权重计算** - 计算每个邮件样本的特征词权重,用于表示其内容特征的重要性。
- **任务3:文本分类** - 应用选定的分类算法对邮件进行自动分类。
- **任务4:样本预测** - 使用训练好的模型对测试邮件进行分类,评估模型性能,计算预测正确率。
4. **提交要求**:
学生需要提交完整的程序源代码,包括项目的目录结构,以及详细的编译和运行指南。此外,还需要提供邮件训练样本全集(未分词)和停用词表作为输入数据,以及邮件文本特征和预测结果作为输出。
在整个设计过程中,学生将深化对MapReduce编程的理解,学习如何处理大规模数据,同时还能应用到实际的文本挖掘问题中,提升数据处理和机器学习技能。
1 / 4
MapReduce 课程设计 之
邮件自动分类
1 课程设计目标
本课程设计的目标是通过 MapReduce 编程来实现邮件的自动分类,通过本课程设计的学习,
可以体会如何使用 MapReduce 完成一个综合性的数据挖掘任务,包括全流程的数据预处理、样本
分类、样本预测等。
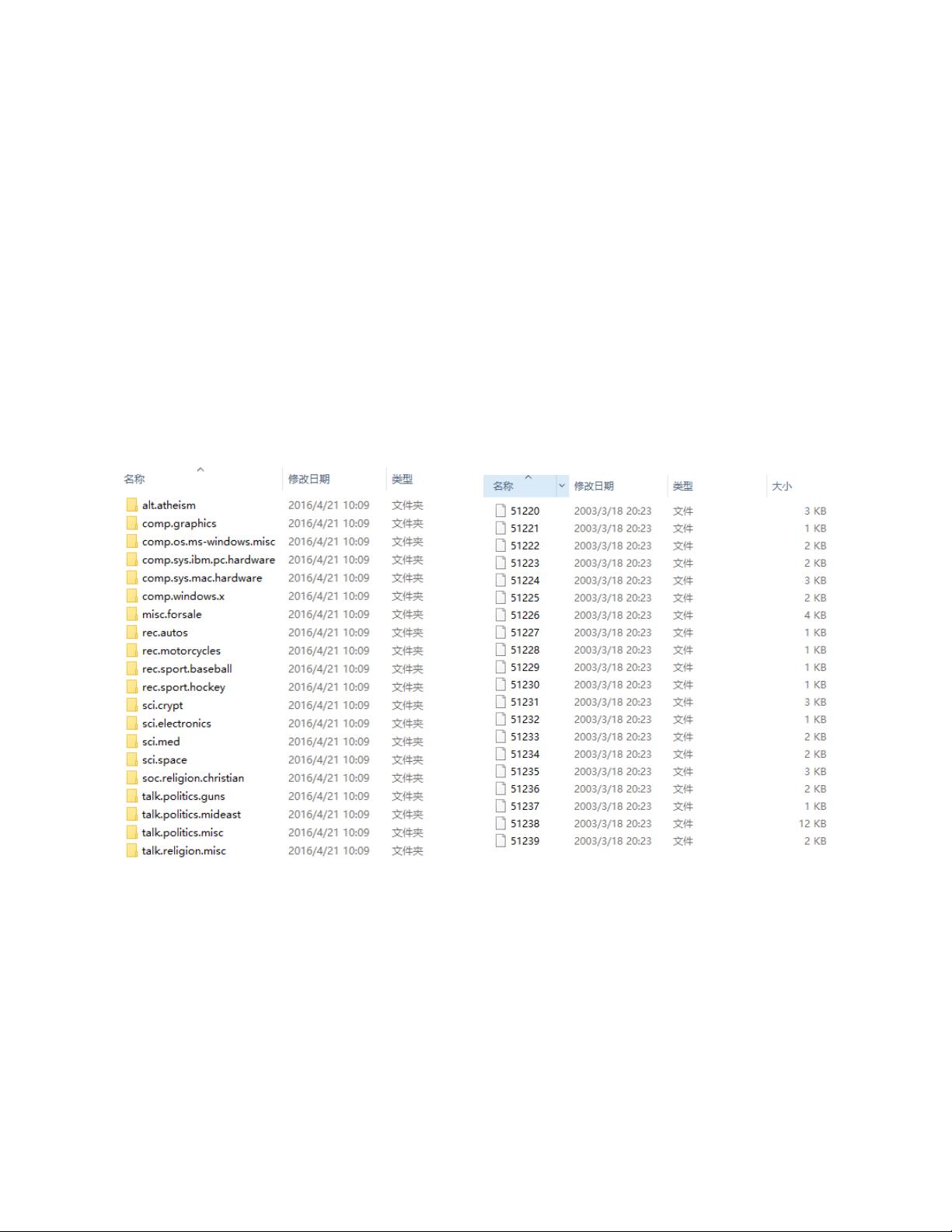
图 1 邮件分类。左边图是邮件类别,每个文件夹代表一个类别,右边图是每个类别下的邮件文本数据。
2 学习技能
通过本课程设计,可以熟悉和掌握以下 MapReduce 编程技能:
(1)在 Hadoop 中使用第三方的 Jar 包来辅助分析;
(2) 掌握 MapReduce 算法设计:
下载后可阅读完整内容,剩余3页未读,立即下载
2022-09-12 上传
2022-09-17 上传
2023-12-20 上传
2023-09-11 上传
2023-05-16 上传
2023-05-30 上传
2023-06-06 上传
2023-05-24 上传
2023-05-04 上传

小崔个人精进录
- 粉丝: 36
- 资源: 316
 我的内容管理
展开
我的内容管理
展开







最新资源
- 解决Eclipse配置与导入Java工程常见问题
- 真空发生器:工作原理与抽吸性能分析
- 爱立信RBS6201开站流程详解
- 电脑开机声音解析:故障诊断指南
- JAVA实现贪吃蛇游戏
- 模糊神经网络实现与自学习能力探索
- PID型模糊神经网络控制器设计与学习算法
- 模糊神经网络在自适应PID控制器中的应用
- C++实现的学生成绩管理系统设计
- 802.1D STP 实现与优化:二层交换机中的生成树协议
- 解决Windows无法完成SD卡格式化的九种方法
- 软件测试方法:Beta与Alpha测试详解
- 软件测试周期详解:从需求分析到维护测试
- CMMI模型详解:软件企业能力提升的关键
- 移动Web开发框架选择:jQueryMobile、jQTouch、SenchaTouch对比
- Java程序设计试题与复习指南
