
pytorch学习学习2
1、过拟合和欠拟合、过拟合和欠拟合
训练误差和泛化误差在解释上述现象之前,我们需要区分训练误差(training error)和泛化误差(generalization error)。通俗来讲,前者指模型在训练数据集上表现出的误差,后者
指模型在任意一个测试数据样本上表现出的误差的期望,并常常通过测试数据集上的误差来近似。计算训练误差和泛化误差可以使用之前介绍过的损失函数,例如线性回归用到的平
方损失函数和softmax回归用到的交叉熵损失函数。机器学习模型应关注降低泛化误差。K折交叉验证由于验证数据集不参与模型训练,当训练数据不够用时,预留大量的验证数据显
得太奢侈。一种改善的方法是K折交叉验证(K-fold cross-validation)。在K折交叉验证中,我们把原始训练数据集分割成K个不重合的子数据集,然后我们做K次模型训练和验证。
每一次,我们使用一个子数据集验证模型,并使用其他K-1个子数据集来训练模型。在这K次训练和验证中,每次用来验证模型的子数据集都不同。最后,我们对这K次训练误差和验
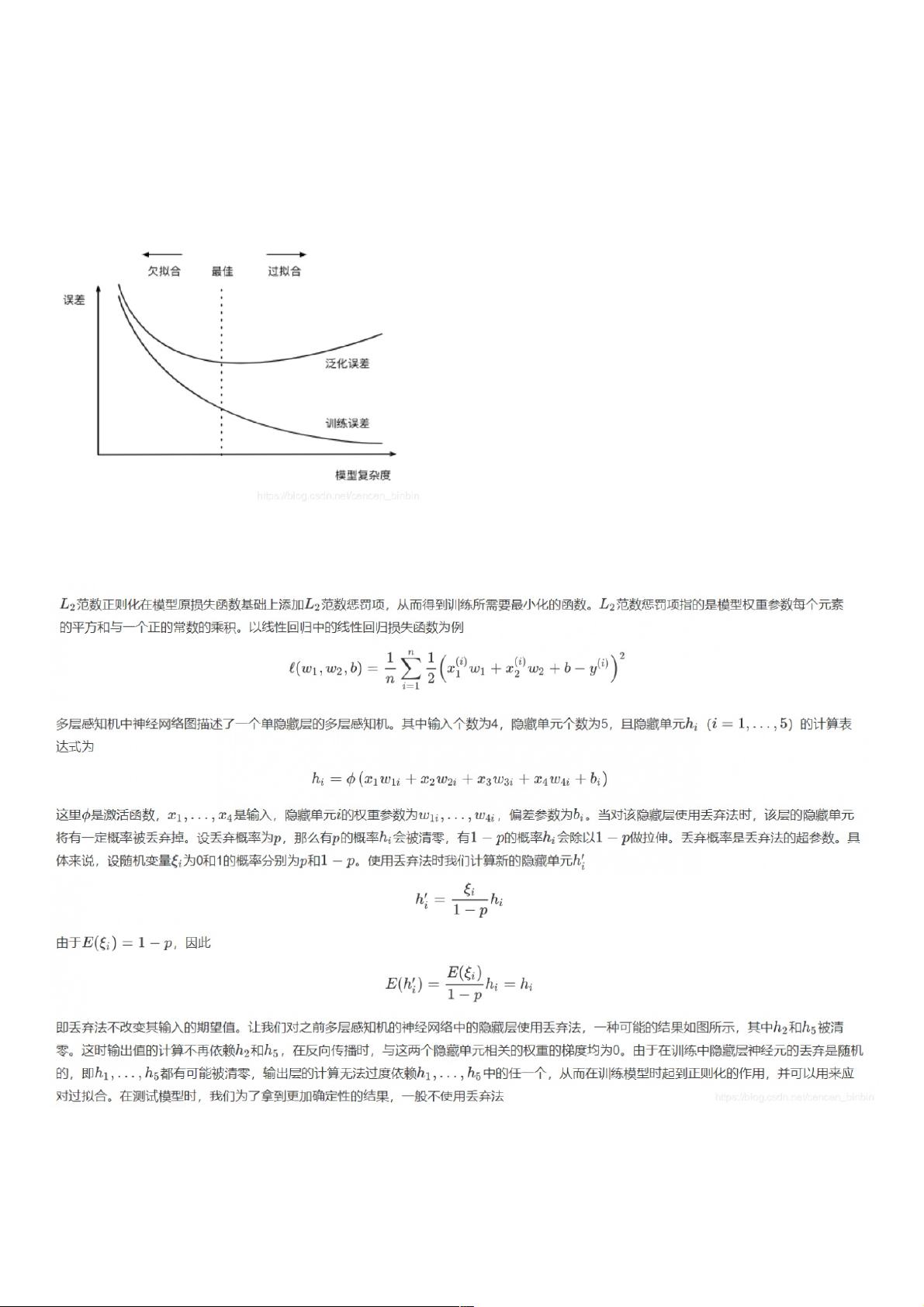
证误差分别求平均。过拟合和欠拟合接下来,我们将探究模型训练中经常出现的两类典型问题:
* 一类是模型无法得到较低的训练误差,我们将这一现象称作欠拟合(underfitting);
* 另一类是模型的训练误差远小于它在测试数据集上的误差,我们称该现象为过拟合(overfitting)。 在实践中,我们要尽可能同时应对欠拟合和过拟合。虽然有很多因素可能导致这
两种拟合问题,在这里我们重点讨论两个因素:模型复杂度和训练数据集大小。
给定训练数据集,模型复杂度和误差之间的关系:
训练数据集大小训练数据集大小
影响欠拟合和过拟合的另一个重要因素是训练数据集的大小。一般来说,如果训练数据集中样本数过少,特别是比模型参数数量(按元素计)更少时,过拟合更容易发生。此外,泛
化误差不会随训练数据集里样本数量增加而增大。因此,在计算资源允许的范围之内,我们通常希望训练数据集大一些,特别是在模型复杂度较高时,例如层数较多的深度学习模
型。防止过拟合的方法:
(1)增加训练数据
(2)L2正则化
(3)丢弃法(dropout)
torch.cat(input1,,input2,1) #按列合并并
pow(input,exponent)#求张量input的exponent次值
torch.zeros_like(X) #用于生成和输入tensor大小相同的全零tensor的。
model.train() #启用 BatchNormalization 和 Dropout
model.eval() #不启用 BatchNormalization 和 Dropout
pd.get_dummies(all_features, dummy_na=True) #将离散数值改为特征
*2
、梯度消失、梯度爆炸、梯度消失、梯度爆炸
下载后可阅读完整内容,剩余3页未读,立即下载

weixin_38679839
- 粉丝: 4
- 资源: 975
 我的内容管理
展开
我的内容管理
展开







最新资源
- 李兴华Java基础教程:从入门到精通
- U盘与硬盘启动安装教程:从菜鸟到专家
- C++面试宝典:动态内存管理与继承解析
- C++ STL源码深度解析:专家级剖析与关键技术
- C/C++调用DOS命令实战指南
- 神经网络补偿的多传感器航迹融合技术
- GIS中的大地坐标系与椭球体解析
- 海思Hi3515 H.264编解码处理器用户手册
- Oracle基础练习题与解答
- 谷歌地球3D建筑筛选新流程详解
- CFO与CIO携手:数据管理与企业增值的战略
- Eclipse IDE基础教程:从入门到精通
- Shell脚本专家宝典:全面学习与资源指南
- Tomcat安装指南:附带JDK配置步骤
- NA3003A电子水准仪数据格式解析与转换研究
- 自动化专业英语词汇精华:必备术语集锦
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


