Python爬虫:利用多协程提升效率解决等待问题
105 浏览量
更新于2024-08-29
收藏 652KB PDF 举报
在Python爬虫开发中,传统的单线程模式可能会因为网络延迟和服务器响应时间导致效率低下,特别是在处理大量数据时,爬虫速度受限于单核CPU的处理能力,即每个任务需要争夺CPU资源,从而造成等待时间过长。为了解决这一问题,我们可以利用协程技术来提高爬虫的并发性能。
协程是一种轻量级的并发模型,不同于线程或多进程,它并不占用额外的系统资源,而是通过程序内部调度,实现了非抢占式的异步执行。Python中的`gevent`库是一个流行的用于实现协程的库,它利用了Greenlet这一概念,使得代码可以在同一线程内并发执行多个任务。
在`gevent`库的帮助下,我们可以重写爬虫代码,使用`monkey.patch_all()`函数将Python的全局解释器进行“猴子补丁”,使其支持协程。以下是一个简单的示例:
```python
from gevent import monkey
monkey.patch_all()
import gevent, time, requests
url_list = ['https://www.baidu.com/', 'https://www.sina.com.cn/', ...] # 包含多个URL的列表
def fetch_url(url):
r = requests.get(url)
print(f"{url}, {r.status_code}")
greenlets = [gevent.spawn(fetch_url, url) for url in url_list] # 创建协程任务
gevent.joinall(greenlets) # 阻塞直到所有协程完成
start_time = time.time()
gevent.spawn_later(0, lambda: print("All tasks done")) # 使用定时器等待所有任务完成后打印总耗时
end_time = time.time()
print("Total time:", end_time - start_time)
```
在这个示例中,我们首先导入必要的库并启用`gevent`。然后定义一个协程函数`fetch_url`,用于发起HTTP请求。通过`gevent.spawn()`创建多个协程任务,并将它们放入`greenlets`列表。`gevent.joinall()`函数会阻塞主线程,直到所有协程执行完毕。最后,我们通过定时器确保在所有任务完成后计算总耗时。
通过使用协程和`gevent`,爬虫能够同时并发地发送多个请求,显著提高了数据抓取的效率。然而,需要注意的是,虽然协程有助于提升性能,但并非所有场景都适用,如处理I/O密集型任务时效果最好,对于CPU密集型任务,可能还需要考虑其他优化方法或使用多进程。此外,爬虫应当遵守网站的robots.txt规则,并确保不会对服务器造成过大压力。
爬虫爬虫——-多协程多协程
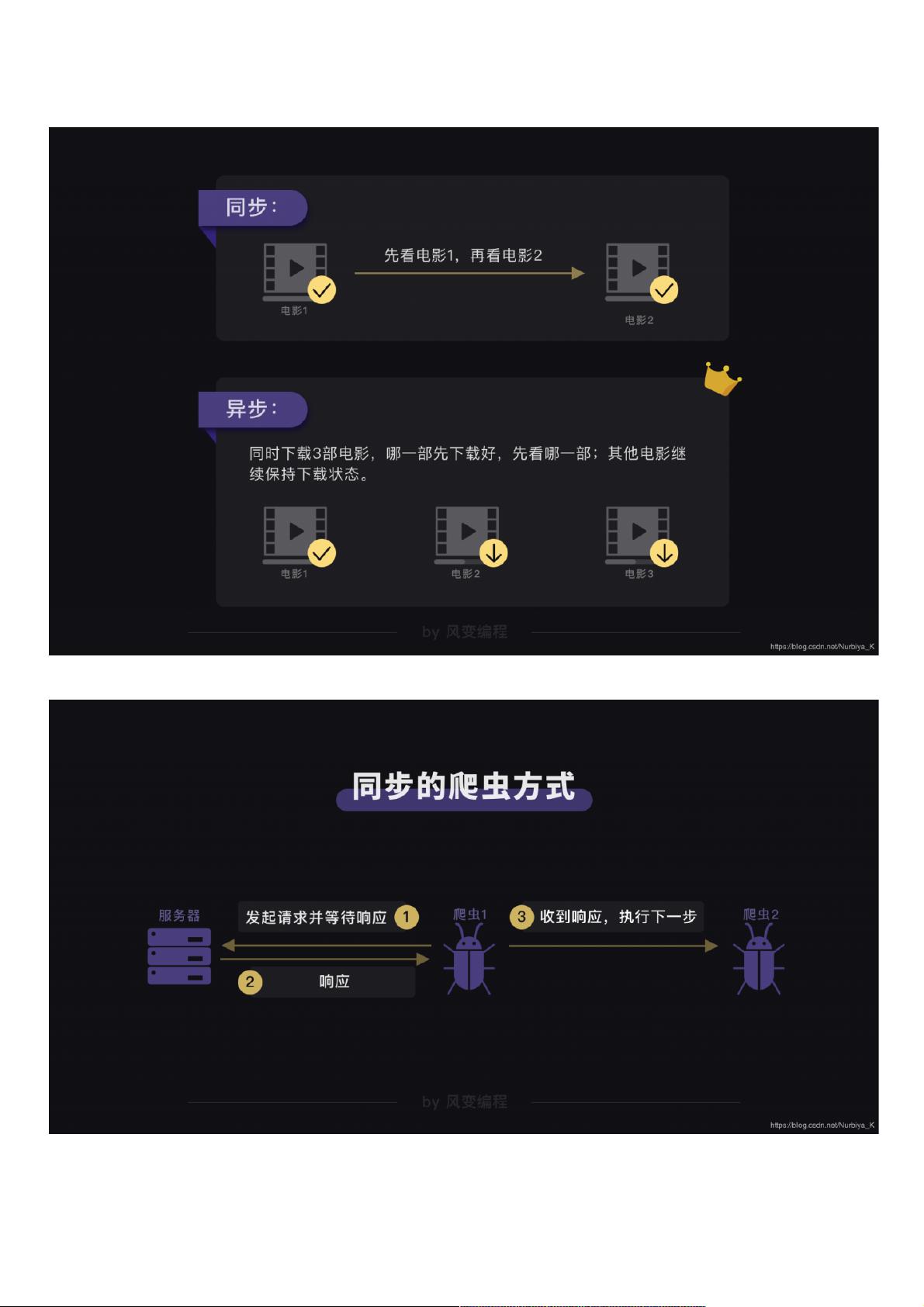
python 是一个脚本语言, 里面编写的代码是从头一行一行的执行,所以一般我们要等到它全部执行完,才能拿到我们要的数据。
一个爬虫爬取大量数据要爬很久,那我们能不能让多个爬虫一起爬取?
爬虫每发起一个请求,都要等服务器返回响应后,才会执行下一步。而很多时候,由于网络不稳定,加上服务器自身也需要响应时间,导致爬虫会浪费大量时间在等待上,这也是爬
取大量数据时,爬虫的速度会比较慢的原因。
每台计算机都靠着CPU(中央处理器)干活,单核CPU的计算机在处理多任务时,会出现一个问题:每个任务都要抢占CPU,执行完了一个任务才开启下一个任务。CPU毕竟只有一
个,这会让计算机处理的效率很低。
为了解决这个问题,一种非抢占式的异步技术创造了出来,这种方式叫多协程。
多协程——gevent库
import requests,time
#导入requests和time
start = time.time()
#记录程序开始时间
下载后可阅读完整内容,剩余5页未读,立即下载
2020-12-23 上传
2021-06-13 上传
2023-03-31 上传
2023-09-17 上传
2023-07-28 上传
2024-05-11 上传
2023-07-28 上传
2024-04-24 上传

weixin_38670949
- 粉丝: 8
- 资源: 983
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++多态实现机制详解:虚函数与早期绑定
- Java多线程与异常处理详解
- 校园导游系统:无向图实现最短路径探索
- SQL2005彻底删除指南:避免重装失败
- GTD时间管理法:提升效率与组织生活的关键
- Python进制转换全攻略:从10进制到16进制
- 商丘物流业区位优势探究:发展战略与机遇
- C语言实训:简单计算器程序设计
- Oracle SQL命令大全:用户管理、权限操作与查询
- Struts2配置详解与示例
- C#编程规范与最佳实践
- C语言面试常见问题解析
- 超声波测距技术详解:电路与程序设计
- 反激开关电源设计:UC3844与TL431优化稳压
- Cisco路由器配置全攻略
- SQLServer 2005 CTE递归教程:创建员工层级结构
