Hadoop源码精析:HDFS模块详解与关键功能研究
在本篇文章中,作者深入剖析Hadoop源代码,专注于HDFS(Hadoop分布式文件系统)部分的讲解。首先,作者明确分析目标:简化复杂性,专注于构建一个能够运行的基本HDFS版本,不涉及系统升级细节,同时强调理解和模块间交互关系,从外部接口和内部实现两方面进行探讨。文章旨在帮助读者从使用者的角度理解模块功能,并寻找具有研究价值的代码段,如块放置策略和MapReduce调度策略。
文章详细介绍了Hadoop的主要包及其功能:
1. `tool` 包提供了实用的命令行工具,如DistCp和archive,用于数据管理和操作。
2. `mapreduce` 是Hadoop的MapReduce实现模块,支持并行计算任务的调度和执行。
3. `filecache` 用于提高MapReduce对HDFS数据的访问速度,通过本地缓存优化性能。
4. `fs` 提供了文件系统的抽象接口,支持多种文件系统的一致性访问。
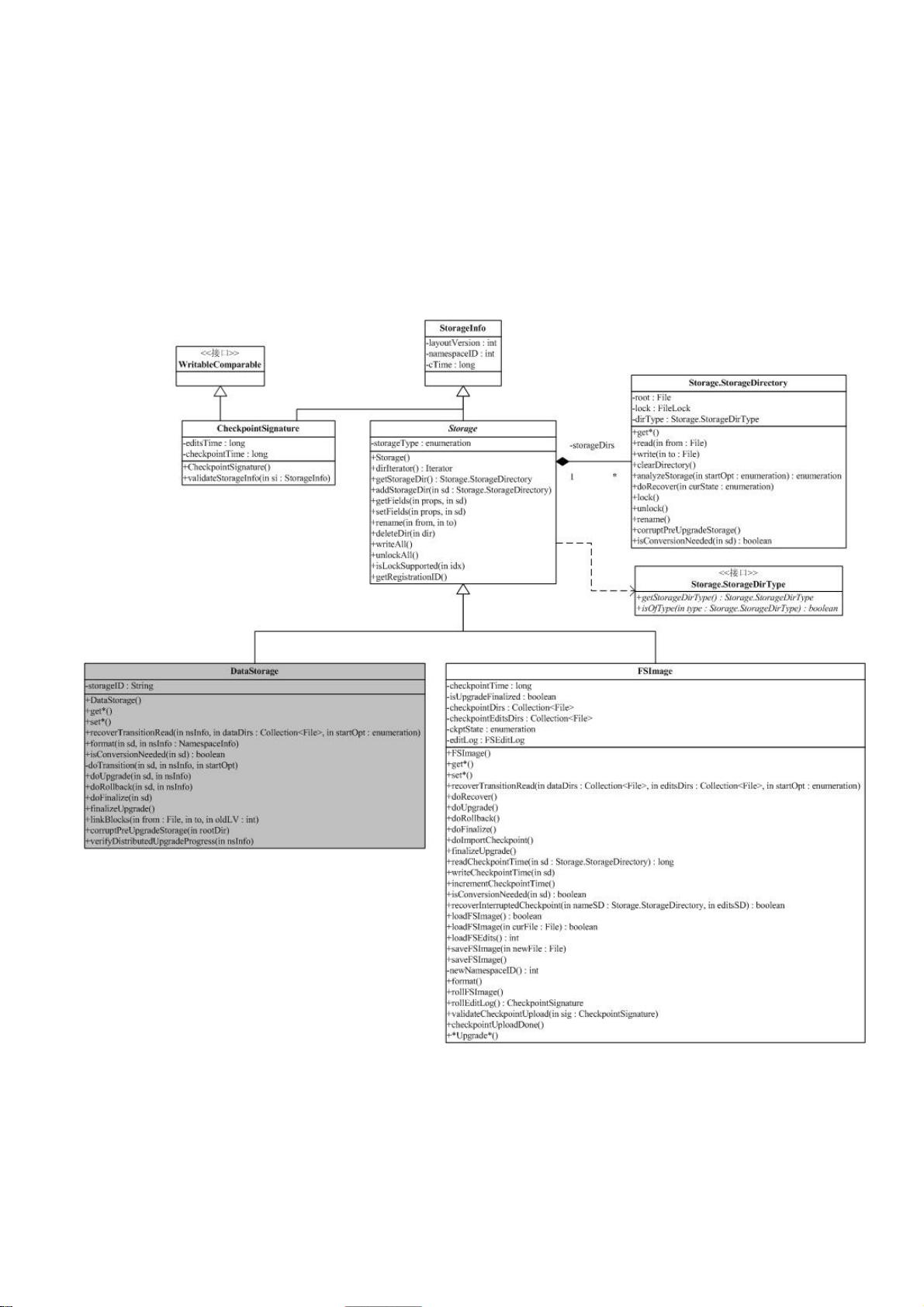
5. `hdfs` 实现了Hadoop的核心分布式文件系统功能,负责存储和管理大量数据。
6. `ipc` 是一个简单的RPC(远程过程调用)实现,利用io包的编码和解码功能。
7. `io` 包负责数据的序列化和网络传输,确保数据在不同节点间的高效交换。
8. `net` 模块封装网络功能,如DNS查询和套接字通信。
9. `security` 管理用户和用户组信息,涉及权限管理和认证。
10. `conf` 存储系统的配置参数,允许灵活调整系统行为。
11. `metrics` 收集和展示系统运行统计信息,有助于监控和管理。
12. `util` 包含各种工具类,简化开发者的日常任务。
13. `record` 自动根据DDL生成编解码函数,支持C++和Java编程。
14. `http` 基于Jetty的HTTPServlet,提供Web界面,让用户查看文件系统状态和日志。
文章参考了LinuxIDC.com网站的一些技术博客,但并未详述所有细节,特别是NameNode部分的分析仍处于初级阶段。总体上,本文是对Hadoop HDFS源代码的深入解读,旨在帮助读者理解系统架构和关键组件的工作原理,为后续的研究和开发提供有价值的信息。

replication)
生成该块的元数据,BlockInfo 类型的对象。
DatanodeDescriptor
getDatanode(int index)
获得该块的第 index 个 Datanode 的信息,返回
DatanodeDescriptor 类型的对象
private int ensureCapacity(int
num)
private int getCapacity()
获的块的所有的副本个数,因为可能会增大副本个数
private int ensureCapacity(int
num)
多增加 num 个单元
上面的图,给出了类型是 object 的 triplets 数组,如果一个块设置的副本个数是 3,那么该块的 3 个相
应的元数据信息 BlockInfo 可以通过 triplets[index*3]来访问。
BlockInfo 类写得好像很怪异,不知道为什么这么写?应该很简单,用一个 list 结构保存块的所有的元数据
信息就可以了,好像在实现上用了一个内部的数组来实现链表的功能?
BlockMap 类
成员变量与方法 含义
private Map<Block, BlockInfo> map = new
HashMap<Block, BlockInfo>()
哈希表,key 是 block,value 是 BlockInfo,即块的元
数据。
类(从上到下依次继承) 用途 位置
DatanodeID 配置信息 org.apache.hadoop.hdfs.protocol 包下
DatanodeInfo 进一步,增加了一些动态信息 org.apache.hadoop.hdfs.protocol 包下
DatanodeDescriptor 再进一步,包含了 DataNode 上一
些 Block 的动态信息。
org.apache.hadoop.hdfs.server.namenode
包下
DatanodeDescriptor 类
保存指定 DataNode 的状态(如可用的存储空间大小、上次的更新时间等)、维护 DataNode 上的块。
内存中的数据结构,并不持久化到 fsImage 中,并且只在 NameNode 内部使用。
DatanodeDescriptor 类内部有两个内部类:BlockTargetPair 和 BlockQueue
BlockTargetPair 保存 Block 和对应 DatanodeDescriptor 的关联
成员变量 含义
public final Block block
public final DatanodeDescriptor[]
targets
BlockQueue 是 BlockTargetPair 队列。
private final Queue<BlockTargetPair> blockq = new LinkedList<BlockTargetPair>();
www.linuxidc.com
Linux公社(LinuxIDC.com) 是包括Ubuntu,Fedora,SUSE技术,最新IT资讯等Linux专业类网站。

剩余45页未读,继续阅读
相关推荐




haiyuanstick
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握JavaScript:经典实例全书源码解析
- VC++项目开发源代码精析:第一章至第四章
- 响应式FLAT商务宽屏Bootstrap项目源码下载
- TS文件解析:如何提取节目信息
- 专家推荐:PMP认证备考必备资料合集
- 虚幻引擎4构建RTS游戏的Agora项目介绍
- 绿色版jd-gui windows:Java反编译工具
- Apache Tomcat 7.0.65部署指南:跨平台Web服务器配置
- XiongFeiTan博客:Jekyll技术支持下的灵感与思考交流平台
- 绿色版驱动精灵单机版:简洁查看电脑设备
- ESP32-GUI-Flasher:全新GUI工具助力ESP32固件刷新
- SynToy:硬盘与U盘资源同步新工具
- 命令行工具wifi-password:跨平台获取wifi密码
- C# 双接口实现及定时器数据处理源码解析
- 细搜天气7.0.3黑莓免费版功能体验与更新问题
- Unreal Engine 4流映射燃烧效果Shader教程
