
Python爬虫之爬虫之Scrapy(爬取(爬取csdn博客)博客)
本博客介绍使用Scrapy爬取博客数据(标题,时间,链接,内容简介)。首先简要介绍Scrapy使用,scrapy安装自行百度安装。
创建爬虫项目创建爬虫项目
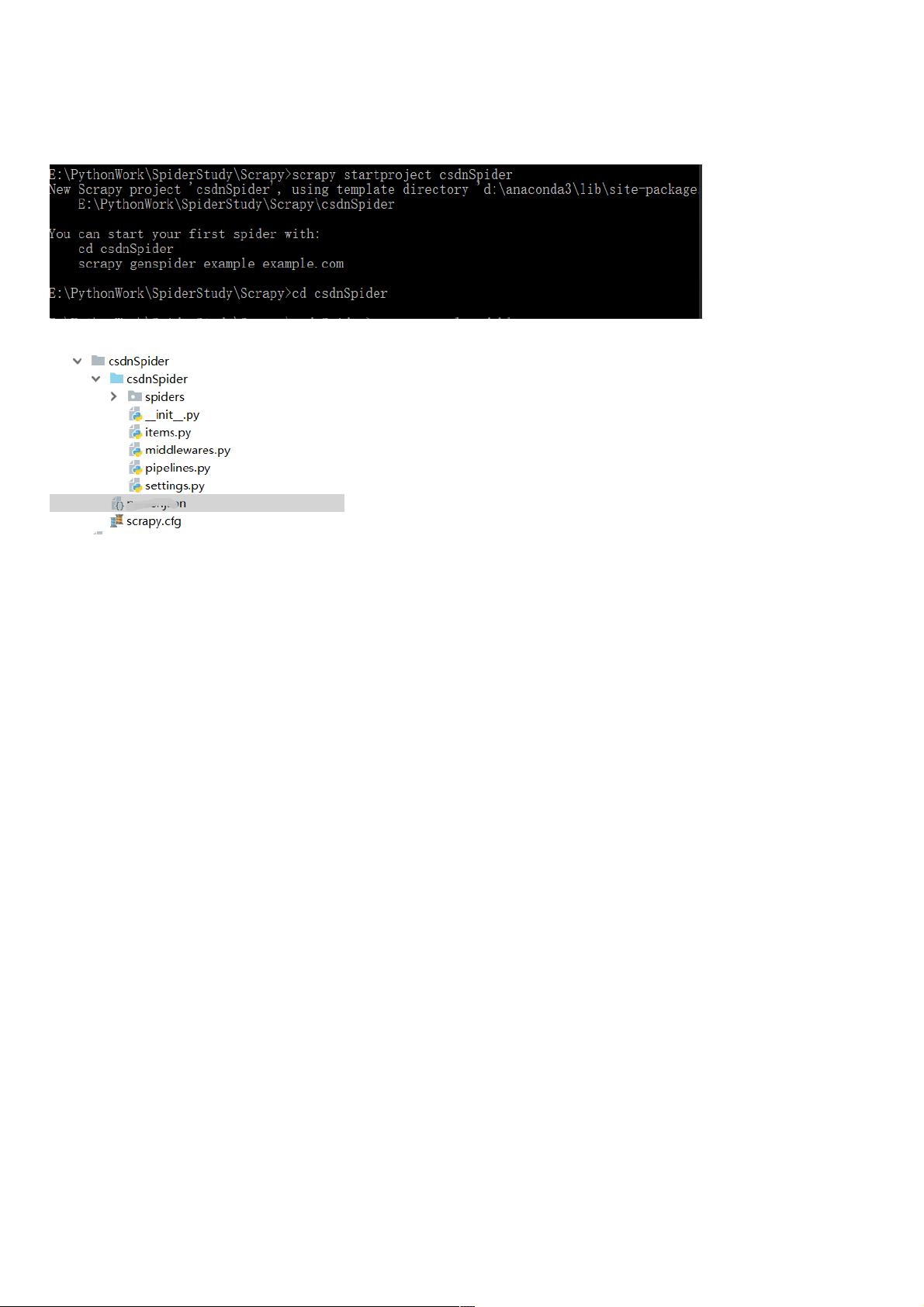
安装好scrapy之后,首先新建项目文件:scrapy startproject csdnSpider
创建项目之后会在相应的文件夹位置创建文件:
创建爬虫模块创建爬虫模块
首先编写爬虫模块,爬虫模块的代码都放置于spiders文件夹中 。 爬虫模块是用于从单个网站或者多个网站爬取数据的类,其应该包含初始 页面的URL, 以及跟
进网页链接、分析页 面内容和提取数据函数。 创建一个Spider类,需要继承scrapy.Spider类,并且定义以下三个属性:
1) name: 用于区别Spider。该名宇必须是唯一的,不能为不同的Spider设定相同的名字。
2) start_urls: 它是Spider在启动时进行爬取的入口URL列表。 因此,第一个被获取到 的页面的URL将是其中之 一 ,后续的URL则从初始的URL的响应中主动提
取 。
3) parse(): 它是Spider的一个方法。 被调用时,每个初始 URL 响应后返回的Response对象,将会作为唯 的参数传递给该方法。该方法负责解析返回的数据
(response data)、 提取数据(生成item)以及生成需要进一步处理的URL的Request对象。
现在创建CsdnSpider类,该类位于spiders下的csdn_spider.py中
#coding:utf-8
import scrapy
from ..items import CsdnspiderItem
class CsdnSpider(scrapy.Spider):
name = "csdnblogs"
allowed_domains = ["csdn.net"]#允许的域名
start_urls = [
"https://blog.csdn.net/qq_16669583/article/list/1",
"https://blog.csdn.net/qq_16669583/article/list/2",
"https://blog.csdn.net/qq_16669583/article/list/3"
]
def parse(self, response):
#实现网页的解析
#首先抽取所有的文章
papers = response.xpath(".//*[@id='mainBox']/main/div[2]/div")
#从每篇文章种提取数据
for paper in papers:
try:
title = paper.xpath("./h4/a/text()").extract()[1] url = paper.xpath("./h4/a/@href").extract()[0] time = paper.xpath("./div[1]/p/span[1]/text()").extract()[0] content =
paper.xpath("./p/a/text()").extract()[0] print(url, title, time, content)
except Exception:
print('数据格式不对')
continue
在爬虫的根目录运行:scrapy crawl csdnblogs结果如下:

weixin_38638596
- 粉丝: 3
- 资源: 984
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- RTL8188FU-Linux-v5.7.4.2-36687.20200602.tar(20765).gz
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
- SPC统计方法基础知识.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0