
Speech and Language Processing. Daniel Jurafsky & James H. Martin. Copyright
c
2019. All
rights reserved. Draft of October 2, 2019.
CHAPTER
A
Hidden Markov Models
Chapter 8 introduced the Hidden Markov Model and applied it to part of speech
tagging. Part of speech tagging is a fully-supervised learning task, because we have
a corpus of words labeled with the correct part-of-speech tag. But many applications
don’t have labeled data. So in this chapter, we introduce the full set of algorithms for
HMMs, including the key unsupervised learning algorithm for HMM, the Forward-
Backward algorithm. We’ll repeat some of the text from Chapter 8 for readers who
want the whole story laid out in a single chapter.
A.1 Markov Chains
The HMM is based on augmenting the Markov chain. A Markov chain is a model
Markov chain
that tells us something about the probabilities of sequences of random variables,
states, each of which can take on values from some set. These sets can be words, or
tags, or symbols representing anything, like the weather. A Markov chain makes a
very strong assumption that if we want to predict the future in the sequence, all that
matters is the current state. The states before the current state have no impact on the
future except via the current state. It’s as if to predict tomorrow’s weather you could
examine today’s weather but you weren’t allowed to look at yesterday’s weather.
WARM
3
HOT
1
COLD
2
.8
.6
.1
.1
.3
.6
.1
.1
.3
charming
uniformly
are
.1
.4
.5
.5
.5
.2
.6
.2
(a) (b)
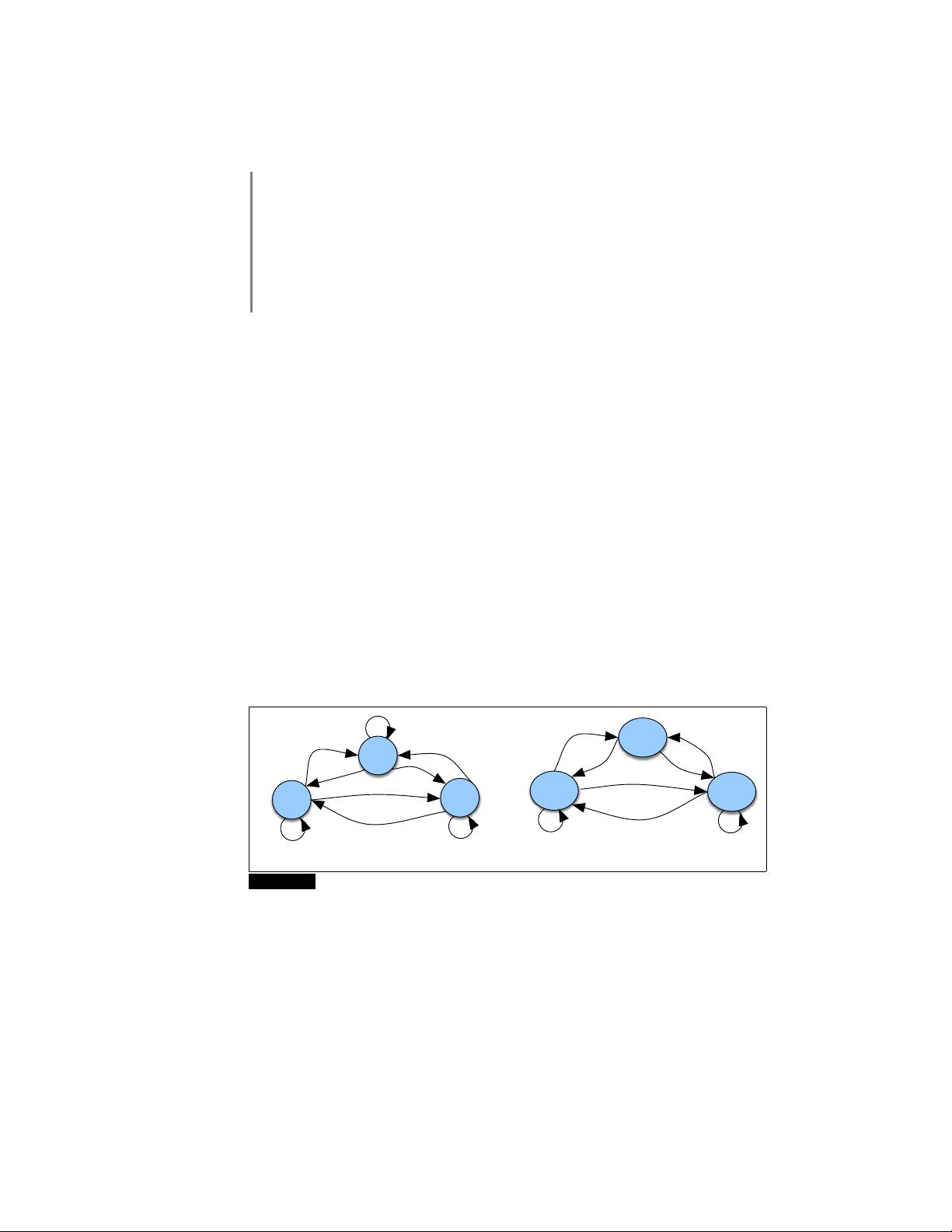
Figure A.1 A Markov chain for weather (a) and one for words (b), showing states and
transitions. A start distribution π is required; setting π = [0.1, 0.7, 0.2] for (a) would mean a
probability 0.7 of starting in state 2 (cold), probability 0.1 of starting in state 1 (hot), etc.
More formally, consider a sequence of state variables q
1
,q
2
,...,q
i
. A Markov
model embodies the Markov assumption on the probabilities of this sequence: that
Markov
assumption
when predicting the future, the past doesn’t matter, only the present.
Markov Assumption: P(q
i
= a|q
1
...q
i−1
) = P(q
i
= a|q
i−1
) (A.1)
Figure A.1a shows a Markov chain for assigning a probability to a sequence of
weather events, for which the vocabulary consists of HOT, COLD, and WARM. The
states are represented as nodes in the graph, and the transitions, with their probabil-
ities, as edges. The transitions are probabilities: the values of arcs leaving a given

剩余16页未读,继续阅读

小孩咋啦
- 粉丝: 0
- 资源: 1
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- RTL8188FU-Linux-v5.7.4.2-36687.20200602.tar(20765).gz
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
- SPC统计方法基础知识.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0