
prediction using paired sentences as input and predicting
whether the second sentence is the original one in the docu-
ment. After pre-training, BERT can be fine-tuned by adding
one output layer alone on a wide range of downstream tasks.
More specifically, When performing sequence level tasks
(e.g., sentiment analysis), BERT uses the representation of
the first token for classification; while for token-level tasks
(e.g., Name Entity Recognition), all tokens are fed into the
softmax layer for classification. At the time of release,
BERT achieves the state-of-the-art results on 11 natural lan-
guage processing task, setting up a milestone in pre-trained
language models. Generative Pre-Trained Transformer se-
ries (e.g., GPT [99], GPT-2 [100]) are another type of pre-
trained models based on the Transformer decoder architec-
ture, which uses masked self-attention mechanisms. The
major difference between GPT series and BERT lies in the
way of pre-training. Unlike BERT, GPT series are one-
directional language models pre-trained by Left-to-Right
(LTR) language modeling. Besides, sentence separator
([SEP]) and classifier token ([CLS]) are only involved in
the fine-tuning stage of GPT but BERT learns those embed-
dings during pre-training. Because the one-directional pre-
pretraining strategy of GPT, it shows superiority in many
natural language generation tasks. More recently, a gigantic
transformer-based model, GPT-3, with incredibly 175 bil-
lion parameters has been introduced [10]. By pre-training
on 45TB compressed plaintext data, GPT-3 claims the abil-
ity to directly process different types of downstream natural
language tasks without fine-tuning, achieving strong perfor-
mances on many NLP datasets, including both natural lan-
guage understanding and generation. Besides the aforemen-
tioned transformer-based PTMs, many other models have
been proposed since the introduction of Transformer. For
this is not the major topic in our survey, we simply list a
few representative models in Table 2 for interested readers.
Apart from the PTMs trained on large corpora for
general natural language processing tasks, transformer-
based models have been applied in many other NLP re-
lated domains or multi-modal tasks. BioNLP Domain.
Transformer-based models have outperformed many tra-
ditional biomedical methods. BioBERT [69] uses Trans-
former architecture for biomedical text mining tasks; SciB-
ERT [7] is developed by training Transformer on 114M sci-
entific articles covering biomedical and computer science
field, aiming to execute NLP tasks related to scientific do-
main more precisely; Huang et al. [55] proposes Clinical-
BERT utilizing Transformer to develop and evaluate con-
tinuous representations of clinical notes and as a side effect,
the attention map of ClinicalBERT can be used to explain
predictions and thus discover high-quality connections be-
tween different medical contents. Multi-Modal Tasks. Ow-
ing to the success of Transformer across text-based NLP
tasks, many researches are committed to exploiting the po-
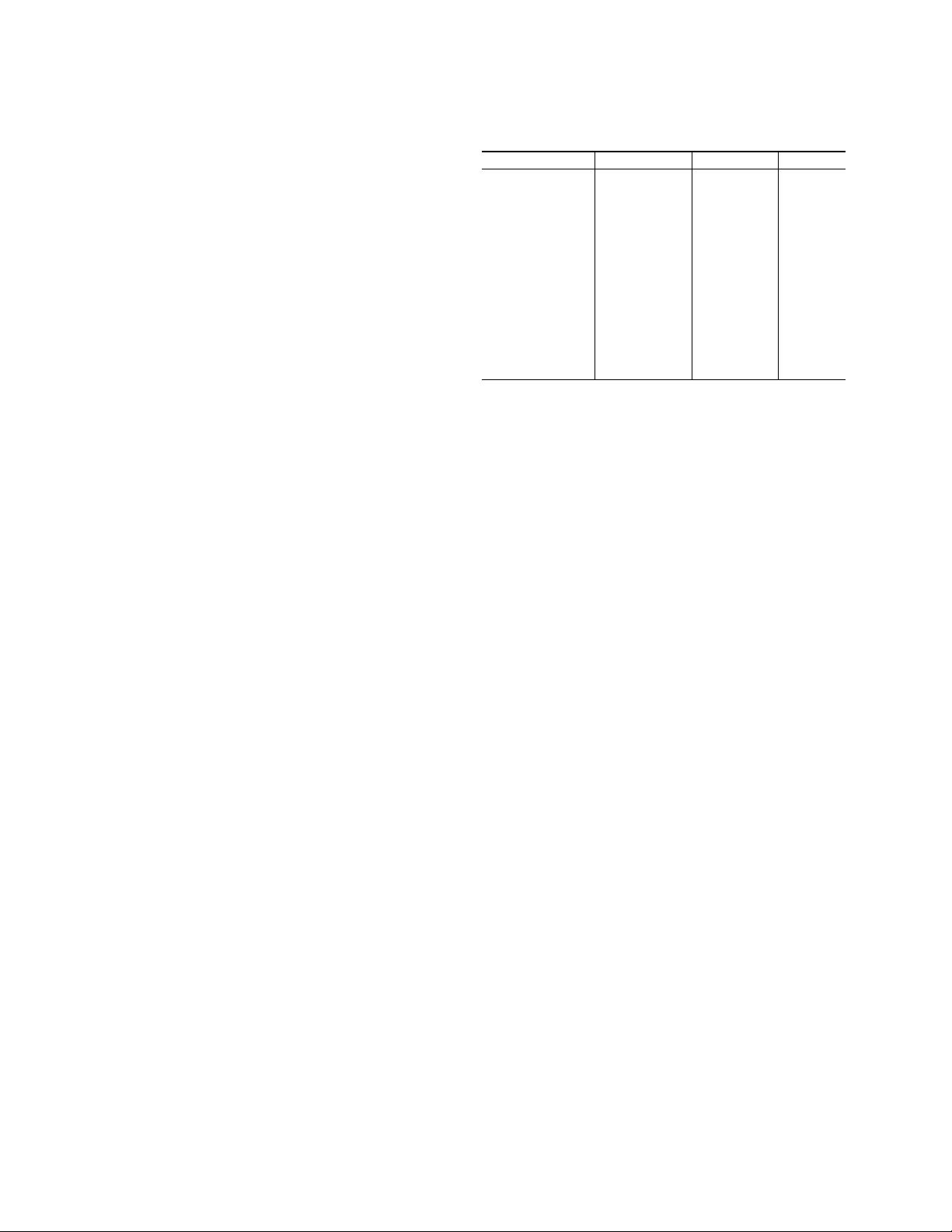
Table 2. List of representative language models built on Trans-
former.
Models Architecture Params Fine-tuning
GPT [99] Transformer Dec. 117M Yes
GPT-2 [100] Transformer Dec. 117M∼1542M No
GPT-3 [10] Transformer Dec. 125M∼175B No
BERT [29] Transformer Enc. 110M∼340M Yes
RoBERTa [82] Transformer Enc. 355M Yes
XLNet [136]
Two-Stream
≈ BERT Yes
Transformer Enc.
ELECTRA [27] Transformer Enc. 335M Yes
UniLM [30] Transformer Enc. 340M Yes
BART [70] Transformer 110% of BERT Yes
T5 [101] Transfomer 220M∼11B Yes
ERNIE (THU) [149] Transform Enc. 114M Yes
KnowBERT [94] Transformer Enc. 253M∼523M Yes
1
Transformer is the standard encoder-decoder architecture. Transfomer
Enc. and Dec. represent the encoder and decoder part of standard
Transformer. Decoder uses mask self-attention to prevent attending to
the future tokens.
2
The data of the Table is from [98].
tential of Transformer to process multi-modal tasks (e.g.,
video-text, image-text and audio-text). VideoBERT [115]
uses a CNN-based module pre-processing the video to get
the representation tokens, based on which a Transformer en-
coder is trained to learn the video-text representations for
downstream tasks, such as video caption. VisualBERT [72]
and VL-BERT [114] propose single-stream unified Trans-
former to capture visual elements and image-text relation-
ship for downstream tasks like visual question answering
(VQA) and visual commonsence reasoning (VCR). More-
over, several studies such as SpeechBERT [24] explore the
possibility of encoding audio and text pairs with a Trans-
former encoder to process auto-text tasks like Speech Ques-
tion Answering (SQA).
The rapid development of transformer-based models on
varieties of natural language processing as well as NLP-
related tasks demonstrates its structural superiority and ver-
satility. This empowers Transformer to become a universal
module in many other AI fields beyond natural language
processing. The following part of this survey will focus on
the applications of Transformer in a wide range of computer
vision tasks emerged in the past two years.
4. Visual Transformer
In this section, we provide a comprehensive review of the
transformer-based models in computer vision, including the
applications in image classification, high-level vision, low-
level vision and video processing. We also briefly summa-
rize the applications of self-attention mechanism and model
compression methods for efficient transformer.
5
剩余20页未读,继续阅读

syp_net
- 粉丝: 158
- 资源: 1187
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 计算机系统基石:深度解析与优化秘籍
- 《ThinkingInJava》中文版:经典Java学习宝典
- 《世界是平的》新版:全球化进程加速与教育挑战
- 编程珠玑:程序员的基础与深度探索
- C# 语言规范4.0详解
- Java编程:兔子繁殖与素数、水仙花数问题探索
- Oracle内存结构详解:SGA与PGA
- Java编程中的经典算法解析
- Logback日志管理系统:从入门到精通
- Maven一站式构建与配置教程:从入门到私服搭建
- Linux TCP/IP网络编程基础与实践
- 《CLR via C# 第3版》- 中文译稿,深度探索.NET框架
- Oracle10gR2 RAC在RedHat上的安装指南
- 微信技术总监解密:从架构设计到敏捷开发
- 民用航空专业英汉对照词典:全面指导航空教学与工作
- Rexroth HVE & HVR 2nd Gen. Power Supply Units应用手册:DIAX04选择与安装指南
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


