SparkSQL物理执行计划各操作实现物理执行计划各操作实现
SparkStrategy: logical to physical
Catalyst作为一个实现无关的查询优化框架,在优化后的逻辑执行计划到真正的物理执行计划这部分只提供了接口,没有提供
像Analyzer和Optimizer那样的实现。
本文介绍的是Spark SQL组件各个物理执行计划的操作实现。把优化后的逻辑执行计划映射到物理执行操作类这部分由
SparkStrategies类实现,内部基于Catalyst提供的Strategy接口,实现了一些策略,用于分辨logicalPlan子类并替换为合适的
SparkPlan子类。
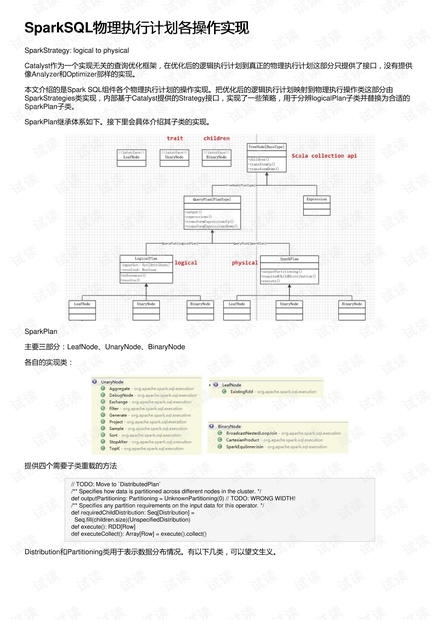
SparkPlan继承体系如下。接下里会具体介绍其子类的实现。
SparkPlan
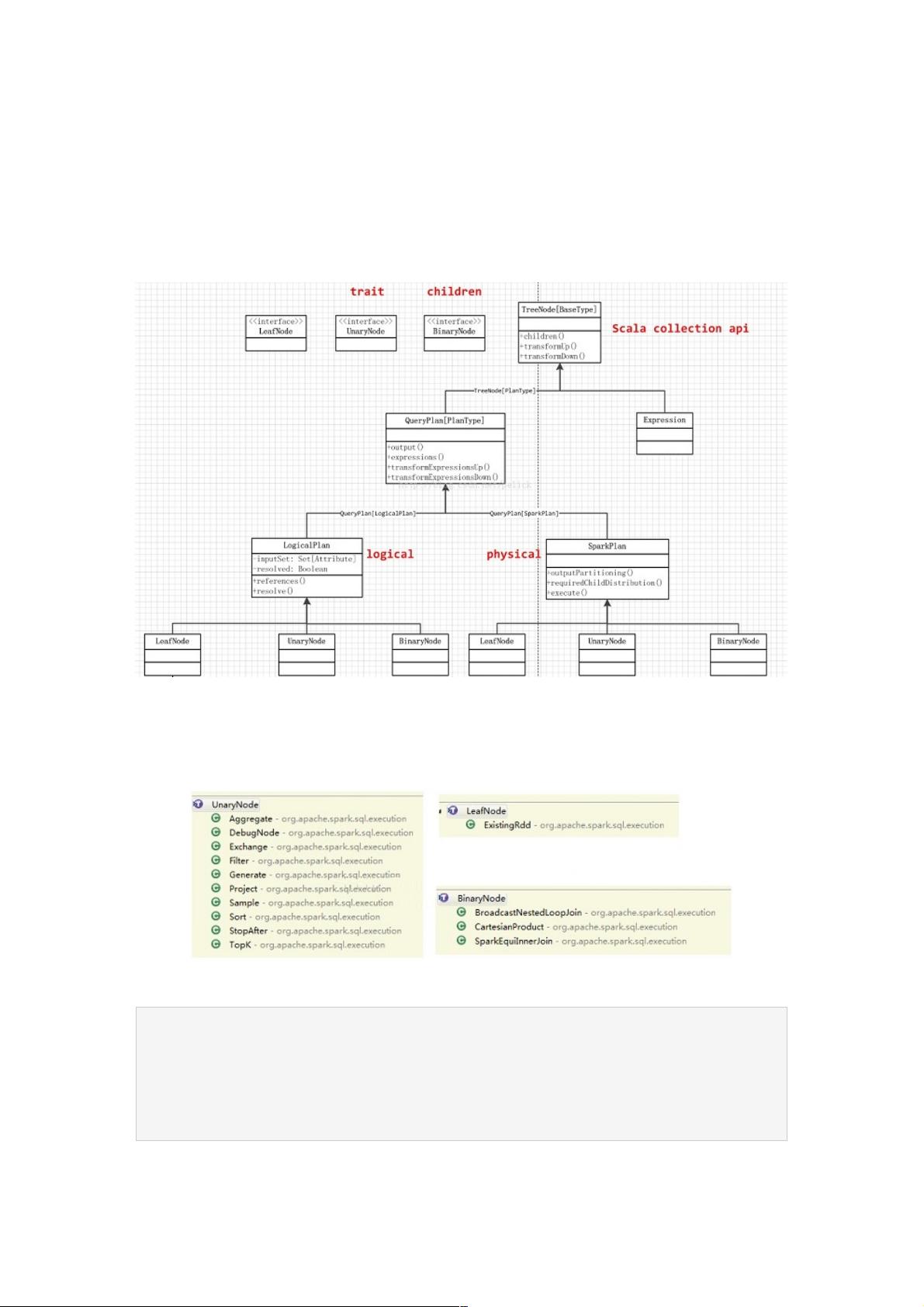
主要三部分:LeafNode、UnaryNode、BinaryNode
各自的实现类:
提供四个需要子类重载的方法
// TODO: Move to `DistributedPlan`
/** Specifies how data is partitioned across different nodes in the cluster. */
def outputPartitioning: Partitioning = UnknownPartitioning(0) // TODO: WRONG WIDTH!
/** Specifies any partition requirements on the input data for this operator. */
def requiredChildDistribution: Seq[Distribution] =
Seq.fill(children.size)(UnspecifiedDistribution)
def execute(): RDD[Row]
def executeCollect(): Array[Row] = execute().collect()
Distribution和Partitioning类用于表示数据分布情况。有以下几类,可以望文生义。

weixin_38500948
- 粉丝: 3
- 资源: 915
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- zigbee-cluster-library-specification
- JSBSim Reference Manual
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0